在训练神经网络完成给定任务(无论是图像分类还是强化学习)时,通常都会细化与网络内每个连接相关的一组权重。另一种已取得实质性进展的成功神经网络的方法是神经架构搜索,它使用手工设计的组件(例如卷积网络组件或变压器块)构建神经网络架构。事实证明,使用这些组件构建的神经网络架构(例如深度卷积网络)对图像处理任务具有强大的归纳偏差,甚至可以在其权重随机初始化时执行这些任务。虽然神经架构搜索为当前任务领域提供了新的方式来安排具有已知归纳偏差的手工设计组件,但是在自动发现具有这种归纳偏差的新神经网络架构方面进展甚微,适用于各种任务领域。
我们可以在先天与后天的例子中看看这些有用组件的类比。就像生物学中某些早熟物种(从出生那一刻起就具有反捕食行为)无需学习即可执行复杂的运动和感官任务一样,也许我们可以构建无需训练即可表现良好的网络架构。当然,这些自然(以及类似人工)神经网络可以通过训练得到进一步改进,但它们无需学习即可执行的能力表明它们包含使其非常适合其任务的偏见。
在“权重不可知神经网络”(WANN)中,我们提出了专门搜索具有这些偏见的网络的第一步:即使使用随机共享权重,神经网络架构也可以执行各种任务。我们在这项工作中的动机是质疑神经网络架构本身在多大程度上可以在不学习任何权重参数的情况下为给定任务编码解决方案。通过探索这样的神经网络架构,我们展示了无需学习权重参数就可以在其环境中表现良好的代理。此外,为了促进该领域社区的进步,我们还开放了代码以重现我们的 WANN 实验,供更广泛的研究社区使用。
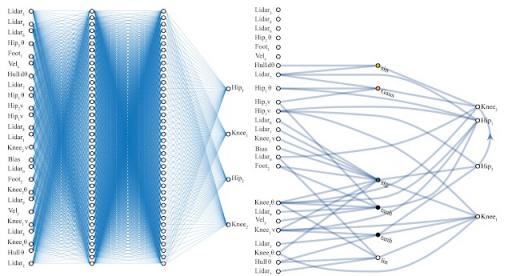
左图:一个手工设计的全连接深度神经网络,有 2760 个权重连接。使用学习算法,我们可以求解 2760 个权重参数集,这样这个网络就可以执行BipedalWalker-v2任务。右图:一个与权重无关的神经网络架构,有 44 个连接,可以执行相同的 Bipedal Walker 任务。与全连接网络不同,这个 WANN 无需训练每个连接的权重参数,仍可执行任务。事实上,为了简化训练,WANN 被设计为在每个权重连接的值相同或共享时执行,即使这个共享权重参数是随机采样的,它也会发挥作用。
寻找 WANN
我们从一组最小神经网络架构候选者开始,每个候选者都只有很少的连接,然后使用完善的拓扑 搜索算法(NEAT),通过逐个添加单个连接和单个节点来演化架构。WANN 背后的关键思想是通过弱化权重来搜索架构。与传统的神经架构搜索方法不同,在传统的神经架构搜索方法中,新架构的所有权重参数都需要使用学习算法进行训练,而我们采用一种更简单、更有效的方法。在这里,在搜索过程中,所有候选架构首先在每次迭代时分配一个共享权重值,然后进行优化,以在广泛的共享权重值范围内表现良好。
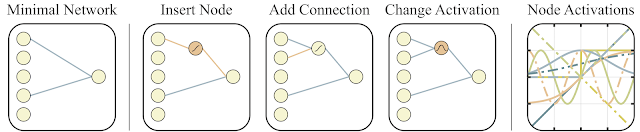
用于搜索网络拓扑空间的运算
符 左图:最小网络拓扑,输入和输出仅部分连接。
中图:网络以以下三种方式之一进行更改:
(1)插入节点:通过拆分现有连接插入新节点。
(2)添加连接:通过连接两个先前未连接的节点添加新连接。
(3)更改激活:重新分配隐藏节点的激活函数。
右图:可能的激活函数(线性、阶跃、正弦、余弦、高斯、双曲正切、S 形、逆、绝对值、ReLU)
除了探索一系列与权重无关的神经网络之外,寻找复杂程度适中的网络架构也很重要。我们利用多目标优化技术,同时优化网络性能和复杂性,从而实现这一目标。
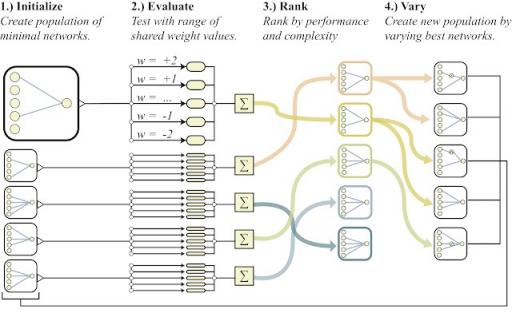
权重不可知神经网络搜索概述以及用于搜索网络拓扑空间的相应运算符。
训练 WANN 架构
与传统网络不同,我们可以通过简单地找到最大化其性能的最佳单个共享权重参数来轻松训练 WANN。在下面的示例中,我们看到我们的架构(在一定程度上)适用于使用恒定权重的摆动式推杆任务:
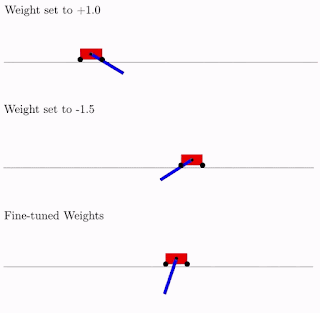
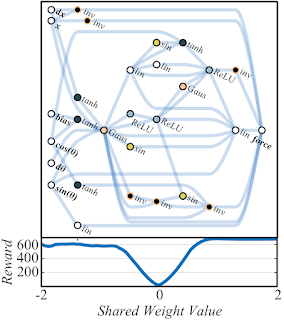
WANN 在各种不同的体重参数下执行 Cartpole Swing-up 任务,同时也使用微调的体重参数。如上图所示,虽然 WANN 可以使用一系列共享权重参数执行任务,但其性能仍然无法与通常用于网络训练的学习每个连接权重的网络相提并论。如果我们想进一步提高其性能,我们可以使用 WANN 架构和最佳共享权重作为起点,使用学习算法微调每个连接权重,就像我们通常训练任何神经网络一样。使用网络架构的权重不可知属性作为起点,并通过学习微调其性能,可能有助于提供对动物学习方式的深刻类比。
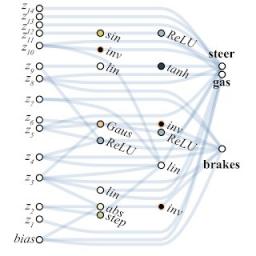

通过对性能和网络简单性进行多目标优化,我们的方法从像素赛车任务中找到了一个简单的 WANN,该 WANN 运行良好,而无需明确训练网络权重。
网络架构仅使用随机权重即可发挥作用,这种能力还具有其他优势。例如,通过使用相同 WANN 架构的副本,但为每个 WANN 副本分配不同的权重值,我们可以为同一任务创建多个不同模型的集合。该集合通常比单个模型具有更好的性能。我们以使用随机权重的MNIST分类器为例来说明这一点:
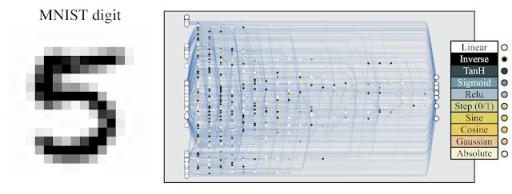
MNIST 分类器经过改进,可以使用随机权重。
虽然使用随机初始化的传统网络在 MNIST 上的准确率约为 10%,但这种特定的网络架构使用随机权重,当应用于 MNIST 时,其准确率远高于偶然性 (> 80%)。当使用一组 WANN 时,每个 WANN 分配不同的共享权重,准确率将提高到 > 90%。
即使没有集成方法,将网络中的权重值数量压缩为一个也可以快速调整网络。快速微调权重的能力可能对持续终身学习很有用,在这种学习中,代理会在整个生命周期中获得、适应和转移技能。这使得 WANN 特别适合利用鲍德温效应,即奖励倾向于学习有用行为的个体的进化 压力,而不会陷入计算成本高昂的“学会学习”陷阱。
结论
我们希望这项工作可以成为帮助发现新的基本神经网络组件(如卷积网络)的垫脚石,卷积网络的发现和应用对深度学习的惊人进步起到了重要作用。自发现卷积神经网络以来,研究界可用的计算资源已显著增加。如果我们将这些资源投入到自动发现中,并希望实现网络架构的渐进式改进,那么我们相信,值得我们探索新的构建块,而不仅仅是它们的排列。
如果您有兴趣了解有关这项工作的更多信息,我们邀请读者阅读我们的交互式文章(或论文的pdf版本以供离线阅读)。除了向研究界开源这些实验外,我们还发布了 NEAT 的通用 Python 实现,称为PrettyNEAT,以帮助感兴趣的读者从第一原理探索神经网络进化的激动人心的领域。
评论