人们可以轻松识别视频中正在发生的活动并预测接下来可能发生的事件,但对于机器来说,这要困难得多。然而,对于机器来说,理解视频的内容和动态对于时间定位、动作检测和自动驾驶汽车导航等应用越来越重要。为了训练神经网络执行这样的任务,通常使用监督训练,其中训练数据由人们逐帧精心标记的视频组成。此类注释很难大规模获得。因此,人们对自监督学习很感兴趣,在自监督学习中,模型在各种代理任务上进行训练,这些任务的监督自然存在于数据本身中。
在“ VideoBERT:视频和语言表示学习的联合模型”(VideoBERT)和“用于时间表示学习的对比双向变压器”(CBT)中,我们建议从未标记的视频中学习时间表示。目标是发现与较长时间范围内发生的动作和事件相对应的高级语义特征。为了实现这一目标,我们利用了人类语言已经进化出用于描述高级物体和事件的词语这一关键见解。在视频中,语音往往与视觉信号在时间上保持一致,可以使用现成的自动语音识别(ASR) 系统提取,从而提供自然的自我监督来源。我们的模型是跨模态学习的一个例子,因为它在训练期间联合利用了来自视觉和音频(语音)模态的信号。

来自同一视频位置的图像帧和人类语音通常在语义上是对齐的。这种对齐并不详尽,有时还会有噪音,我们希望通过在更大的数据集上进行预训练来缓解这种噪音。对于左侧示例,ASR 输出为“继续紧紧滚动并将空气挤压到侧面,你可以稍微拉一下。 ”,其中动作被语音捕获,但物体没有。对于右侧示例,ASR 输出为“这是你需要耐心等待的地方”,这与视觉内容完全无关。
用于视频的 BERT 模型
表征学习的第一步是定义一个代理任务,该任务引导模型从较长的未标记视频中学习时间动态和跨模态语义对应关系。为此,我们概括了Transformer 的双向编码器表征(BERT) 模型。通过应用Transformer架构对长序列进行编码,并在包含大量文本的语料库上进行预训练, BERT 模型在各种自然语言处理任务中表现出了最佳性能。BERT 使用完形填空测试作为其代理任务,其中 BERT 模型被迫双向预测上下文中的缺失单词,而不仅仅是预测序列中的下一个单词。 为此,我们概括了 BERT 训练目标,使用图像帧与相同位置的 ASR 句子输出相结合来组成跨模态“句子”。根据视觉特征相似性,将图像帧转换为持续时间为 1.5 秒的视觉标记。然后将它们与 ASR 单词标记连接起来。我们训练 VideoBERT 模型来填补视觉文本句子中缺失的标记。我们的假设(我们的实验也支持这一假设)是,通过对该代理任务进行预训练,模型可以学习推理较长时间的动态(视觉完形填空)和高级语义(视觉文本完形填空)。
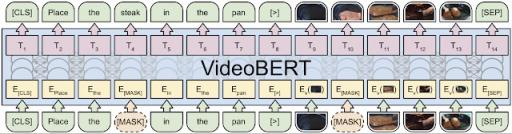
VideoBERT 在视频和文本掩码标记预测(或完形填空)任务中的说明。底部:来自视频相同位置的视觉和文本 (ASR) 标记被连接起来以形成 VideoBERT 的输入。一些视觉和文本标记被掩码掉。中间:
VideoBERT 应用Transformer架构来联合编码双向视觉文本上下文。黄色和粉色框分别对应输入和输出嵌入。顶部:训练目标是恢复掩码位置的正确标记。
检查 VideoBERT 模型
我们用超过一百万个教学视频(例如烹饪、园艺和汽车维修)训练了 VideoBERT。训练完成后,可以检查 VideoBERT 模型在多项任务中学习到的内容,以验证输出是否准确反映了视频内容。例如,文本到视频预测可用于自动从视频生成一组说明(例如食谱),从而生成反映每个步骤所述内容的视频片段(标记)。此外,视频到视频预测可用于根据初始视频标记可视化可能的未来内容。

VideoBERT 的定性结果,已在烹饪视频上进行预训练。顶部:给定一些食谱文本,我们生成一系列视觉标记。底部:给定一个视觉标记,我们显示 VideoBERT 在不同时间尺度上预测的前三个未来标记。在本例中,该模型预测一碗面粉和可可粉可能会在烤箱中烘烤,并可能变成布朗尼或纸杯蛋糕。我们使用特征空间中最接近标记的训练集中的图像来可视化视觉标记。
为了验证 VideoBERT 是否能够学习视频和文本之间的语义对应关系,我们在烹饪视频数据集上测试了其“零样本”分类准确度,其中在预训练期间既未使用视频也未使用注释。为了进行分类,将视频标记与模板句子“现在让我向您展示如何 [MASK] [MASK]”连接起来,并提取预测的动词和名词标记。VideoBERT 模型的准确度达到了全监督基线的前 5 名,表明该模型能够在这种“零样本”设置中表现出色。
使用对比双向变换器进行迁移学习
虽然 VideoBERT 在学习如何自动标记和预测视频内容方面表现出色,但我们注意到 VideoBERT 使用的视觉标记可能会丢失细粒度的视觉信息,例如较小的物体和细微的动作。为了探索这一点,我们提出了对比双向变换器(CBT) 模型,该模型消除了这个标记化步骤,并通过在下游任务上进行迁移学习进一步评估了学习到的表示的质量。 CBT 应用了不同的损失函数,即对比损失,以最大化掩蔽位置和其余跨模态句子之间的互信息。我们针对多种任务(例如动作分割、动作预期和视频字幕)和各种视频数据集评估了所学习到的表示。在大多数基准测试中,CBT 方法的表现都远远优于之前的最先进方法。我们观察到:(1)跨模态目标对于迁移学习性能很重要;(2)更大、更多样化的预训练集可带来更好的表示;(3)与平均池化或LSTM等基线方法相比,CBT 模型在利用长时间上下文方面要好得多。
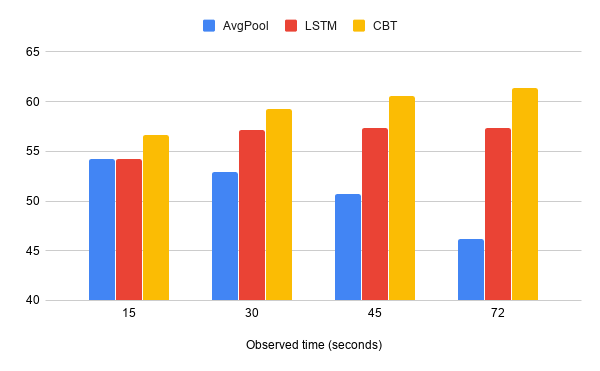
使用 CBT 方法对包含 200 个活动类别的未修剪视频进行动作预测准确度测试。我们将其与AvgPool和LSTM进行比较,并报告观察时间为 15、30、45 和 72 秒时的性能。
结论和未来工作
我们的研究结果证明了 BERT 模型在从未标记视频中学习视觉语言和视觉表征方面的强大功能。我们发现我们的模型不仅可用于零样本动作分类和配方生成,而且学习到的时间表征也能很好地迁移到各种下游任务,例如动作预测。未来的工作包括联合学习低级视觉特征和长期时间表征,从而更好地适应视频环境。此外,我们计划扩大预训练视频的数量,使其更加丰富多样。
致谢
核心团队包括 Chen Sun、Fabien Baradel、Austin Myers、Carl Vondrick、Kevin Murphy 和 Cordelia Schmid。我们要感谢 Jack Hessel、Bo Pang、Radu Soricut、Baris Sumengen、Zhenhai Zhu 和 BERT 团队分享了出色的工具,这些工具极大地促进了我们的实验。我们还要感谢 Justin Gilmer、Abhishek Kumar、Ben Poole、David Ross 和 Rahul Sukthankar 的有益讨论。
评论