据估计,全世界随时都有 19 亿人患有皮肤病,由于皮肤科医生短缺,很多病例都由全科医生接诊。仅在美国,诊所就诊的患者中就有多达37%至少有一种皮肤病,而超过一半的患者由非皮肤科医生接诊。然而,研究表明,全科医生和皮肤科医生在皮肤病诊断的准确率上存在显著差距,全科医生的准确率在24%到70%之间,而皮肤科医生的准确率高达77%到96 %。这可能导致转诊不理想、护理延误以及诊断和治疗错误。
非皮肤科医生提高诊断准确性的现有策略包括使用参考教科书、在线资源和咨询同事。机器学习工具的开发也旨在帮助提高诊断的准确性。先前的研究主要集中在皮肤癌的早期筛查,特别是病变是恶性还是良性,或者病变是否为黑色素瘤。然而,超过 90% 的皮肤问题都不是恶性的,解决这些更常见的疾病对于减轻全球皮肤病负担也很重要。
在“用于皮肤病鉴别诊断的深度学习系统”中,我们开发了一个深度学习系统 (DLS) 来解决初级保健中最常见的皮肤病。我们的结果表明,当提供有关患者病例的相同信息(图像和元数据)时,DLS 对 26 种皮肤病的诊断准确率与美国委员会认证的皮肤科医生相当。这项研究强调了 DLS 增强未接受过额外专业培训的全科医生准确诊断皮肤病的能力的潜力。DLS
设计
临床医生经常会面临模棱两可的病例,没有明确的答案。例如,该患者的皮疹是淤积性皮炎还是蜂窝织炎,或者两者兼而有之?临床医生不会只给出一种诊断,而是会进行鉴别诊断,这是一份可能诊断的排序列表。鉴别诊断框定了问题,以便可以系统地应用额外的检查(实验室检查、影像、程序、咨询)和治疗,直到确诊。因此,深度学习系统 (DLS) 可以生成针对皮肤病的可能皮肤状况的排序列表,这与临床医生的思维方式非常相似,是及时对患者进行分类、诊断和治疗的关键。
为了做出这一预测,DLS 处理输入,包括一张或多张皮肤异常的临床图像和多达 45 种类型的元数据(病史的自我报告部分,如年龄、性别、症状等)。对于每个病例,使用 Inception -v4神经网络架构处理多张图像,并将其与特征转换的元数据相结合,以用于分类层。在我们的研究中,我们开发并评估了 17,777 个去识别病例的 DLS,这些病例主要从初级保健诊所转诊到远程皮肤病学服务。 2010 年至 2017 年的数据用于训练,2017 年至 2018 年的数据用于评估。在模型训练期间,DLS 利用了 40 多位皮肤科医生提供的 50,000 多个鉴别诊断。
为了评估 DLS 的准确性,我们将其与基于三位美国委员会认证的皮肤科医生的诊断的严格参考标准进行了比较。总共有 3,756 例皮肤科医生提供了鉴别诊断(“验证集 A”),这些诊断通过投票过程汇总以得出基本事实标签。将 DLS 的皮肤状况排名列表与皮肤科医生得出的鉴别诊断进行比较,分别实现了 71% 和 93% 的 top-1 和 top-3 准确率。
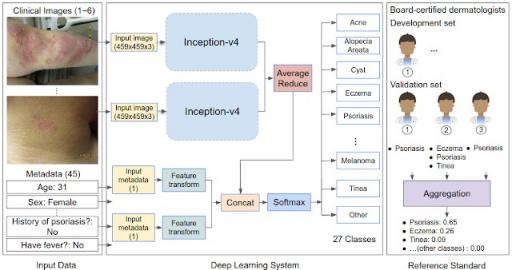
DLS 示意图以及如何通过验证集中的每个病例的三位委员会认证的皮肤科医生投票得出参考标准(基本事实)。
与专业评估的比较
在本研究中,我们还在验证 A 数据集的一个子集(“验证集 B”)中将 DLS 的准确度与三类临床医生的准确度进行了比较:皮肤科医生、初级保健医生 (PCP) 和执业护士 (NP)——所有这些都是随机选择的,代表了一系列的经验、培训和诊断准确度。由于临床医生提供的典型鉴别诊断仅包含最多三种诊断,因此我们仅将 DLS 的前三个预测与临床医生进行了比较。DLS 在验证 B 数据集上实现了 90% 的前 3 名诊断准确度,这与皮肤科医生相当,并且明显高于初级保健医生 (PCP) 和执业护士 (NP)——每组 6 名临床医生分别为 75%、60% 和 55%。这种较高的前 3 名准确度表明 DLS 可能有助于促使临床医生(包括皮肤科医生)考虑他们鉴别诊断中原本没有的可能性,从而提高诊断准确性和病情管理。
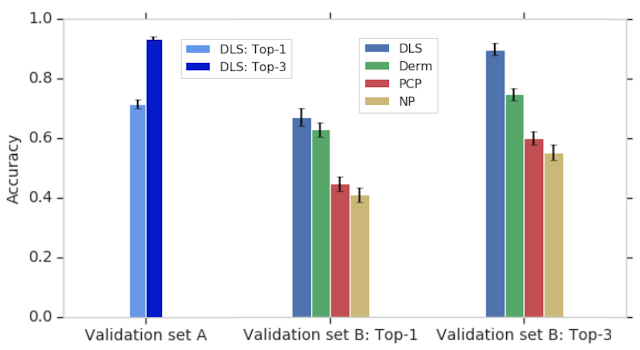
DLS 的领先(前 1 名)鉴别诊断明显高于 PCP 和 NP,与皮肤科医生相当。当我们查看 DLS 的前 3 名准确率时,准确率会大幅提高,这表明在大多数情况下,DLS 的诊断排序列表包含该病例的正确基本事实答案。
评估人口统计学表现
皮肤类型与皮肤病学尤其相关,在皮肤病学中,对皮肤本身的视觉评估对于诊断至关重要。为了评估对皮肤类型的潜在偏见,我们检查了基于Fitzpatrick 皮肤类型的DLS 性能,该类型范围从 I 型(“苍白色,总是晒伤,从不晒黑”)到 VI 型(“最深的棕色,从不晒伤”)。为了确保有足够多的病例来得出令人信服的结论,我们重点关注了至少占数据的 5% 的皮肤类型 — — Fitzpatrick 皮肤类型 II 至 IV。在这些类别中,DLS 的准确度相似,前 1 个准确度范围为 69-72%,前 3 个准确度范围为 91-94%。令人鼓舞的是,DLS 在患者亚组中也保持准确,这些亚组基于其他自我报告的人口统计信息(年龄、性别和种族/民族)在数据集中存在大量(至少 5%)的患者。作为进一步的定性分析,我们通过显著性(解释)技术评估了 DLS 令人放心地“关注”的是异常而不是肤色。
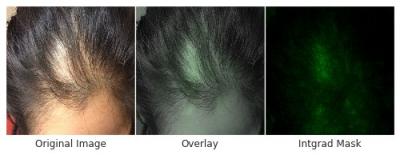
左图:脱发病例示例,非专业人士很难做出具体诊断,而具体诊断对于确定适当的治疗方法至关重要。右图:图像中以绿色突出显示的区域,显示 DLS 认为重要并用于进行预测的区域。中间图:组合图像,表明 DLS 主要关注脱发区域来做出预测,而不是前额肤色等,这可能表明存在潜在偏差。
整合多种数据类型
我们还研究了不同类型的输入数据对 DLS 性能的影响。就像拥有来自多个角度的图像可以帮助远程皮肤科医生更准确地诊断皮肤状况一样,DLS 的准确性会随着图像数量的增加而提高。如果缺少元数据(例如病史),模型的性能就会下降。这种准确性差距可能出现在没有病史的情况下,可以通过仅使用图像训练 DLS 来部分缓解。尽管如此,这些数据表明,提供有关皮肤状况的几个问题的答案可以大大提高 DLS 的准确性。
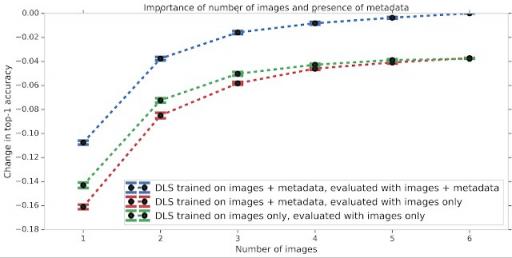
当存在更多图像(蓝线)或元数据(蓝线与红线相比)时,DLS 性能会提高。在没有元数据作为输入的情况下,仅使用图像训练单独的 DLS 会比当前的 DLS(绿线)带来轻微的改进。
未来的工作和应用
虽然这些结果非常有希望,但仍有许多工作要做。首先,作为现实世界实践的反映,我们的数据集中皮肤癌(如黑色素瘤)相对罕见,这阻碍了我们训练精确的癌症检测系统的能力。与此相关的是,我们数据集中的皮肤癌标签未经活检证实,限制了这方面的基本事实的质量。其次,虽然我们的数据集确实包含各种 Fitzpatrick 皮肤类型,但某些皮肤类型在此数据集中太罕见,无法进行有意义的训练或分析。最后,验证数据集来自一个远程皮肤病学服务。虽然包括了两个州的 17 个初级保健地点,但对来自更广泛地理区域的病例进行额外验证将至关重要。我们相信,可以通过在训练和验证集中纳入更多经活检证实的皮肤癌病例,并纳入代表其他 Fitzpatrick 皮肤类型和来自其他临床中心的病例来解决这些限制。
深度学习在皮肤病鉴别诊断方面的成功令人鼓舞,这种工具有潜力协助临床医生。例如,这种 DLS 可以帮助对病例进行分类,以指导临床护理的优先顺序,或者可以帮助非皮肤科医生更准确地启动皮肤病护理,并可能改善就诊体验。尽管还有大量工作要做,但我们对未来研究这种系统对临床医生的实用性充满期待。如需研究合作咨询,请联系 dermatology-research@google.com。
致谢
这项工作涉及一个由软件工程师、研究人员、临床医生和跨职能贡献者组成的多学科团队的努力。本项目的主要贡献者包括 Yuan Liu、Ayush Jain、Clara Eng、David H. Way、Kang Lee、Peggy Bui、Kimberly Kanada、Guilherme de Oliveira Marinho、Jessica Gallegos、Sara Gabriele、Vishakha Gupta、Nalini Singh、Vivek Natarajan、Rainer Hofmann-Wellenhof、Greg S. Corrado、Lily H. Peng、Dale R. Webster、Dennis Ai、Susan Huang、Yun Liu、R. Carter Dunn 和 David Coz。作者感谢 William Chen、Jessica Yoshimi、Xiang Ji 和 Quang Duong 为数据收集提供的软件基础设施支持。还要感谢 Genevieve Foti、Ken Su、T Saensuksopa、Devon Wang、Yi Gao 和 Linh Tran。最后但同样重要的是,如果没有皮肤科医生、初级保健医生、审查本研究病例的执业护士、帮助建立皮肤状况图谱的 Sabina Bis 和提供手稿反馈的 Amy Paller 的参与,这项工作就不可能实现。此处
提供的信息是研究,并不反映可供销售的产品。无法保证将来的可用性。
评论