自然语言处理(NLP) 在过去几年中取得了重大进展,BERT、ALBERT、ELECTRA和XLNet等预训练模型在各种任务中都取得了显著的准确性。在预训练中,通过反复屏蔽单词并尝试预测它们(这称为屏蔽语言建模) ,从大型文本语料库(例如Wikipedia )中学习表示。得到的表示编码了有关语言和概念之间相关性的丰富信息,例如外科医生和手术刀。然后是第二个训练阶段,即微调,在此阶段,模型使用特定于任务的训练数据来学习如何使用通用的预训练表示来执行具体任务,例如分类。鉴于这些表示在许多 NLP 任务中得到广泛采用,因此了解其中编码的信息以及任何学习到的相关性如何影响下游性能至关重要,以确保这些模型的应用符合我们的AI 原则。
在“测量和减少预训练模型中的性别相关性”中,我们对 BERT 及其低内存对应模型 ALBERT 进行了案例研究,研究了与性别相关的相关性,并制定了一系列使用预训练语言模型的最佳实践。我们展示了公共模型检查点和学术任务数据集的实验结果,以说明最佳实践的应用方式,为探索超出本案例研究范围的设置奠定了基础。我们将很快发布一系列检查点Zari 1,它们可以减少性别相关性,同时在标准 NLP 任务指标上保持最先进的准确性。
测量相关性
为了了解预训练表示中的相关性如何影响下游任务性能,我们应用了一组不同的评估指标来研究性别的表示。在这里,我们将讨论其中一项测试的结果,该测试基于共指解析,这是一种允许模型理解句子中给定代词的正确先行词的能力。例如,在下面的句子中,模型应该识别出his指的是护士,而不是病人。

该任务的标准学术表述是OntoNotes测试(Hovy 等人, 2006),我们使用此数据的F1 分数来衡量模型在一般环境中的共指消解的准确度(如Tenney 等人, 2019)。由于 OntoNotes 仅代表一种数据分布,我们还考虑了WinoGender基准,该基准提供了额外的、平衡的数据,旨在识别性别和职业之间的模型关联何时错误地影响共指消解。WinoGender 指标的高值(接近一)表示模型是根据性别和职业之间的规范关联做出决策的(例如,将护士与女性而不是男性相关联)。当模型决策在性别和职业之间没有一致的关联时,分数为零,这表明决策基于其他信息,例如句子结构或语义。
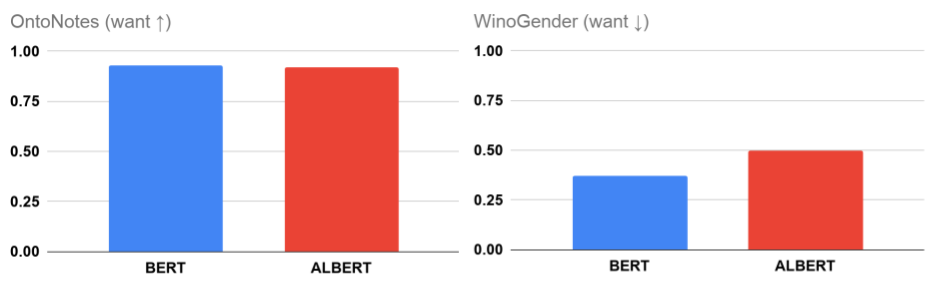
OntoNotes(准确度)和 WinoGender(性别相关性)上的 BERT 和 ALBERT 指标。WinoGender 指标的低值表示模型在推理中不优先使用性别相关性。
在这项研究中,我们发现 (Large) BERT或ALBERT公共模型在 WinoGender 示例上都没有获得零分,尽管在 OntoNotes 上取得了令人印象深刻的准确率(接近 100%)。这至少部分是由于模型在推理中优先使用性别相关性。这并不完全令人惊讶:有一系列线索可用于理解文本,一般模型可以拾取其中的任何或全部。然而,有理由谨慎行事,因为模型最好不要主要基于作为先验知识学习到的性别相关性而不是输入中可用的证据来进行预测。
最佳实践
鉴于预训练模型表示中的意外关联可能会影响下游任务推理,我们现在要问:在开发新的 NLP 模型时,可以做些什么来减轻这种风险?
测量非预期相关性很重要:可以使用准确度指标来评估模型质量,但这些指标只能衡量性能的一个维度,尤其是当测试数据来自与训练数据相同的分布时。例如,BERT 和 ALBERT 检查点的准确度在 1% 以内,但在使用性别相关性进行共指解析的程度上相差 26%(相对)。这种差异对于某些任务可能很重要;在以可能不符合历史社会规范的职业人士(例如男护士)为特色的应用程序中,选择 WinoGender 得分较低的模型可能是可取的。
即使在进行看似无害的配置更改时也要小心:神经网络模型训练由许多超参数控制,这些超参数通常被选中以最大化某些训练目标。虽然配置选择通常看起来无害,但我们发现它们会导致性别相关性发生重大变化,无论是好是坏。例如, dropout 正则化用于减少大型模型的过度拟合。当我们增加用于预训练 BERT 和 ALBERT 的 dropout 率时,即使在微调之后,我们也会看到性别相关性显着降低。这是有希望的,因为简单的配置更改使我们能够以较低的危害风险训练模型,但它也表明我们在对模型配置进行任何更改时都应该小心谨慎并仔细评估。
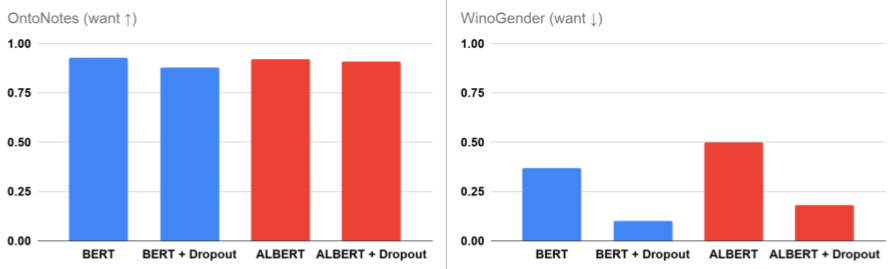
增加 dropout 正则化对 BERT 和 ALBERT 的影响。
有机会采取一般的缓解措施: dropout 对性别相关性可能产生的意外影响的另一个推论是,它为使用通用方法减少意外相关性提供了可能性:通过在我们的研究中增加 dropout,我们改进了模型对 WinoGender 示例的推理方式,而无需手动指定任何有关任务的信息或完全更改微调阶段。不幸的是,随着 dropout 率的增加,OntoNotes 的准确性确实开始下降(我们可以在 BERT 结果中看到),但我们对在预训练中缓解这种情况的潜力感到兴奋,其中更改可以导致模型改进,而无需特定于任务的更新。我们在论文中探讨了反事实数据增强作为另一种具有不同权衡的缓解策略。
下一步
我们相信这些最佳实践为开发强大的 NLP 系统提供了一个起点,该系统在尽可能广泛的语言环境和应用中表现良好。当然,这些技术本身并不足以捕获和消除所有潜在问题。任何在现实环境中部署的模型都应经过严格的测试,考虑到其多种使用方式,并实施保障措施以确保符合道德规范,例如 Google 的 AI 原则。我们期待评估框架和数据的发展更加广泛和包容,以涵盖语言模型的多种用途及其旨在服务的广泛人群。
致谢
本研究与 Xuezhi Wang、Ian Tenney、Ellie Pavlick、Alex Beutel、Jilin Chen、Emily Pitler 和 Slav Petrov 合作完成。在整个项目过程中,我们与 Fernando Pereira、Ed Chi、Dipanjan Das、Vera Axelrod、Jacob Eisenstein、Tulsee Doshi 和 James Wexler 的讨论让我们受益匪浅。
评论