最近的研究表明,并非所有数据样本都同样适用于训练,尤其是对于深度神经网络(DNN)。事实上,如果数据集包含低质量或错误标记的数据,通常可以通过删除大量训练样本来提高性能。此外,在训练和测试数据集不匹配的情况下(例如,由于训练和测试位置或时间的差异),也可以通过仔细将训练集中的样本限制为与测试场景最相关的样本来实现更高的性能。由于这些场景无处不在,准确量化训练样本的值对于提高现实世界数据集上的模型性能具有巨大的潜力。

顶部:低质量样本(嘈杂/众包)的示例;底部:训练和测试不匹配的示例。
除了提高模型性能之外,为单个数据分配质量值还可以实现新的用例。它可用于建议更好的数据收集实践,例如,哪些类型的额外数据将受益最多,并可用于更有效地构建大规模训练数据集,例如通过使用标签作为关键字进行网络搜索并过滤掉价值较低的数据。
在ICML 2020上接受的 “使用深度强化学习进行数据评估”中,我们使用一种基于元学习的新方法解决了量化训练数据价值的挑战。我们的方法将数据评估集成到预测模型的训练过程中,该模型学习识别对给定任务更有价值的样本,从而提高预测器和数据评估的性能。我们还推出了四个AI Hub Notebook,它们体现了 DVRL 的用例,旨在方便地适应其他任务和数据集,例如 领域自适应、 损坏样本发现和稳健学习、 图像数据的迁移学习 和 数据评估。
量化数据的价值
对于给定的 ML 模型,并非所有数据都是平等的 — 有些数据与当前任务的相关性更高,或者包含的信息内容比其他数据更丰富。那么如何评估单个数据的价值呢?在完整数据集的粒度上,这很简单;人们可以简单地在整个数据集上训练模型,并将其在测试集上的表现用作其价值。然而,估计单个数据的价值要困难得多,尤其是对于依赖大规模数据集的复杂模型,因为在所有可能的子集上重新训练和重新评估模型在计算上是不可行的。
为了解决这个问题,研究人员探索了基于排列的方法(例如影响函数)和基于博弈论的方法(例如数据 Shapley)。然而,即使是目前最好的方法对于大型数据集和复杂模型来说也远远不够计算,而且它们的数据评估性能有限。同时,基于元学习的自适应权重分配方法已经开发出来,使用元目标来估计权重值。但它们的数据值映射通常基于梯度下降学习或其他启发式方法,这些方法会改变传统的预测模型训练动态,而不是优先从高价值数据样本中学习,这可能导致与单个数据点的值无关的性能变化。
使用强化学习 (DVRL) 进行数据估值
为了推断数据值,我们提出了一个数据价值估计器(DVE),它可以估计数据值并选择最有价值的样本来训练预测模型。这种选择操作从根本上来说是不可微的,因此不能使用传统的基于梯度下降的方法。相反,我们建议使用强化学习(RL),使得 DVE 的监督基于一种奖励,该奖励量化了预测器在小型(但干净)验证集上的表现。在给定状态和输入样本的情况下,奖励会指导策略优化朝着最佳数据估值的方向发展。在这里,我们将预测模型学习和评估框架视为环境,这是 RL 辅助机器学习的一种新应用场景。

使用强化学习 (DVRL) 进行数据价值评估训练。当使用准确度奖励训练数据价值评估器时,最有价值的样本(用绿点表示)被使用得越来越多,而最不有价值的样本(用红点表示)使用得较少。
结果
我们在多种类型的数据集和用例上评估了 DVRL 的数据价值估计质量。
删除高/低值样本后的模型性能
从训练数据集中删除低值样本可以提高预测模型的性能,尤其是在训练数据集包含损坏样本的情况下。另一方面,删除高值样本(尤其是在数据集较小的情况下)会显著降低性能。总体而言,删除高/低值样本后的性能是数据评估质量的有力指标。
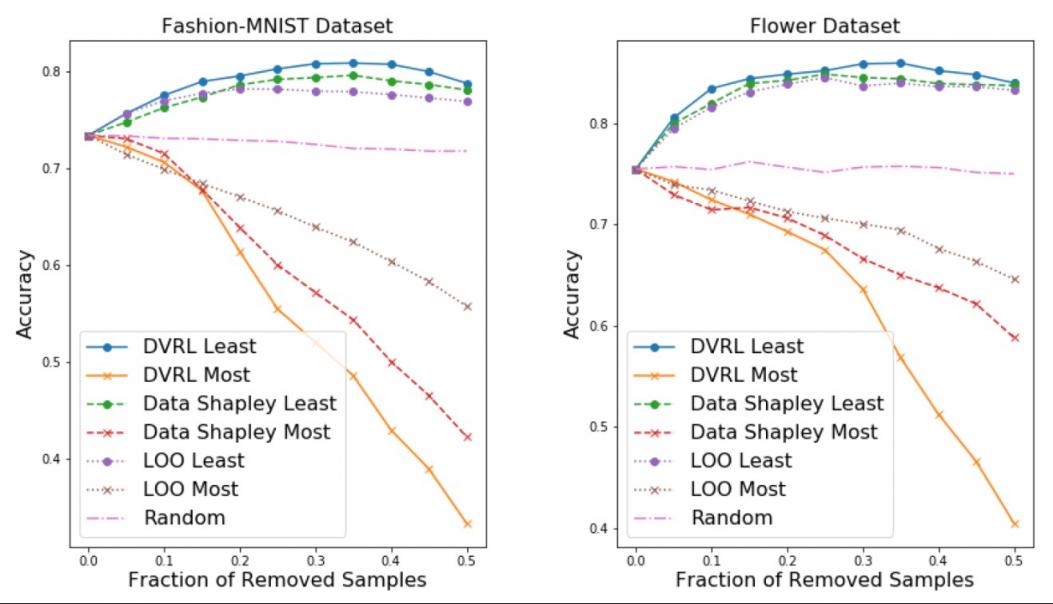
删除最有价值和最没有价值的样本后的准确率,其中 20% 的标签在设计上是有噪声的。通过删除这些噪声标签作为最没有价值的样本,高质量的数据评估方法可以实现更高的准确率。从这个角度来看,我们证明了 DVRL 的表现明显优于其他方法。
在大多数情况下, DVRL在删除最重要的样本后性能下降最快,而在删除最不重要的样本后性能下降最慢,这突显了与竞争方法(Leave-One-Out和 Data Shapley)相比,DVRL 在识别噪声标签方面的优势。
带噪声标签的稳健学习
我们考虑 DVRL 如何以端到端的方式可靠地学习噪声数据,而无需删除低值样本。理想情况下,噪声样本应在 DVRL 收敛时获得较低的数据值,并返回高性能模型。
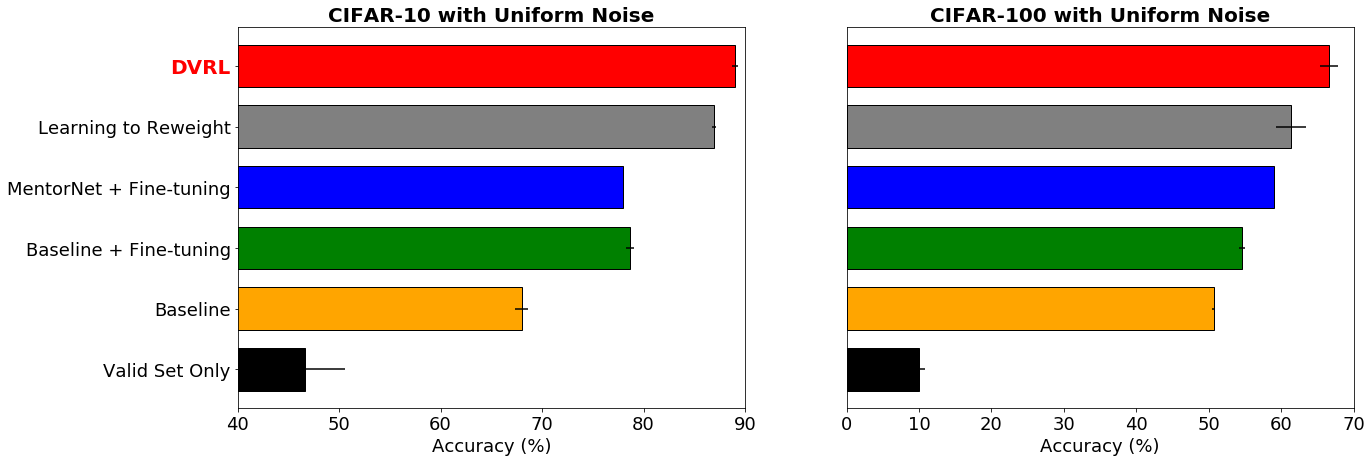
带有噪声标签的稳健学习。在CIFAR-10 和 CIFAR-100数据集上测试 ResNet-32 和WideResNet-28-10的准确率,标签上有 40% 的均匀随机噪声。DVRL 的表现优于其他基于元学习的流行方法。
我们展示了使用 DVRL最小化噪声标签影响的 最优结果。这些结果还表明 DVRL 可以扩展到复杂模型和大规模数据集。
领域自适应
我们考虑这样的场景:训练数据集的分布与验证和测试数据集的分布有很大不同。通过从训练数据集中选择最符合验证数据集分布的样本,数据估值预计会对这项任务有益。我们关注以下三种情况:(1)基于图像搜索结果(低质量网页爬取)的训练集,应用于使用HAM 10000数据(高质量医疗)预测皮肤病变分类的任务;(2)用于USPS 数据(不同的视觉领域)数字识别任务的 MNIST 训练集;(3) 用于检测垃圾邮件的电子邮件垃圾邮件数据,应用于SMS 数据集(不同任务)。通过联合优化数据估值器和相应的预测模型,DVRL 为领域自适应带来了显著的改进。

结论
我们提出了一种新颖的数据评估元学习框架,该框架确定了每个训练样本在预测模型训练中使用的可能性。与以前的研究不同,我们的方法将数据评估集成到预测模型的训练过程中,从而使预测器和 DVE 能够相互提高性能。我们使用通过 RL 训练的 DNN 来建模这个数据值估计任务,并从代表目标任务性能的小型验证集获得奖励。以计算高效的方式,DVRL 可以提供高质量的训练数据排名,这对于领域自适应、损坏样本发现和稳健学习非常有用。我们表明,DVRL 在不同类型的任务和数据集上的表现明显优于替代方法。
致谢
我们衷心感谢 Tomas Pfister 的贡献。
评论