最先进的机器学习 (ML) 仅通过对照片进行模型训练,就在许多计算机视觉任务上实现了卓越的准确性。在这些成功的基础上,进一步提高 3D 物体理解能力,将为增强现实、机器人技术、自动驾驶和图像检索等更广泛的应用提供巨大支持。例如,今年早些时候,我们发布了MediaPipe Objectron,这是一组专为移动设备设计的实时 3D 物体检测模型,这些模型在完全注释的真实世界 3D 数据集上进行训练,可以预测物体的 3D 边界框。
然而,与 2D 任务(例如ImageNet、COCO和Open Images ) 相比,由于缺乏大型现实世界数据集,理解 3D 中的对象仍然是一项具有挑战性的任务。为了使研究界能够在 3D 对象理解方面取得持续进步,迫切需要发布以对象为中心的视频数据集,这些数据集可以捕获对象的更多 3D 结构,同时匹配用于许多视觉任务(即视频或摄像头流)的数据格式,以帮助训练和对机器学习模型进行基准测试。
今天,我们很高兴发布Objectron 数据集,这是一组以物体为中心的短视频片段,从不同角度捕捉大量常见物体。每个视频片段都附有 AR 会话元数据,其中包括相机姿势和稀疏点云。数据还包含每个物体的手动注释 3D 边界框,用于描述物体的位置、方向和尺寸。该数据集由 15K 个带注释的视频片段和从地理多样化样本(覆盖五大洲的 10 个国家/地区)收集的超过 400 万张带注释的图像组成。

Objectron 数据集中的示例视频。
3D 物体检测解决方案
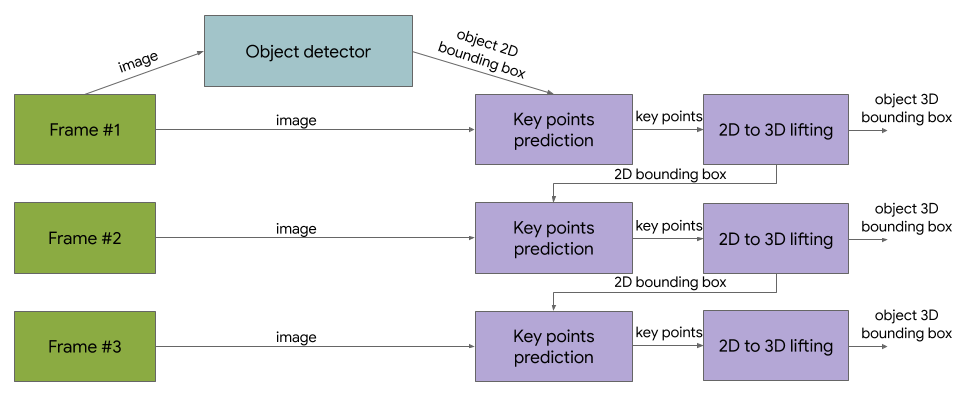
除了数据集之外,我们还将分享针对四类物体(鞋子、椅子、杯子和相机)的3D 物体检测解决方案。这些模型在MediaPipe中发布,MediaPipe 是 Google 为直播和流媒体提供跨平台可定制 ML 解决方案的开源框架,它还支持设备上实时手部、虹膜和身体姿势跟踪等ML 解决方案。

在移动设备上运行的 3D 物体检测解决方案的示例结果。
与之前发布的单阶段 Objectron 模型相比,这些最新版本采用了两阶段架构。第一阶段采用TensorFlow 对象检测模型来查找对象的 2D 裁剪。然后,第二阶段使用图像裁剪来估计 3D 边界框,同时计算下一帧对象的 2D 裁剪,这样对象检测器就不需要每帧都运行。第二阶段 3D 边界框预测器在 Adreno 650 移动 GPU 上以 83 FPS 的速度运行。
参考 3D 物体检测解决方案的图表。
3D 物体检测的评估指标
借助地面实况注释,我们使用 3D交并比(IoU) 相似度统计来评估 3D 物体检测模型的性能,这是计算机视觉任务中常用的指标,它衡量边界框与地面实况的接近程度。
我们提出了一种算法,用于计算一般面向 3D 的框的精确 3D IoU 值。首先,我们使用Sutherland-Hodgman 多边形裁剪算法计算两个框面之间的交点。这类似于计算机图形学中使用的一种技术——截头体剔除。交点的体积由所有裁剪多边形的凸包计算得出。最后,根据两个框的交点体积和并集体积计算 IoU。我们将随数据集一起 发布评估指标源代码。
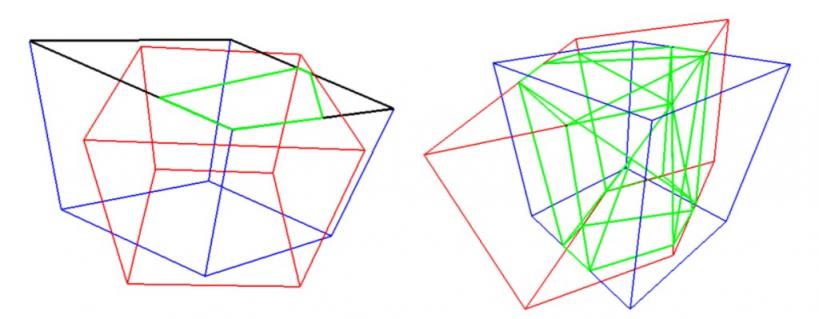
使用多边形裁剪算法计算并集的 3D 交集,左:通过根据框裁剪多边形来计算每个面的交点。右:通过计算所有交点的凸包来计算交集体积(绿色)。
数据集格式
Objectron 数据集的技术细节(包括使用方法和教程)可在数据集网站上找到。该数据集包括自行车、书籍、瓶子、相机、麦片盒、椅子、杯子、笔记本电脑和鞋子,并存储在Google Cloud 存储的objectron 存储桶中,其中包含以下资产:
视频序列
注释标签(对象的 3D 边界框)
AR 元数据(例如相机姿势、点云和平面)
处理后的数据集:带注释帧的混洗版本,图像采用 tf.example 格式,视频采用 SequenceExample 格式。
支持脚本根据上述指标运行评估
支持将数据加载到Tensorflow、PyTorch和 Jax以及可视化数据集的脚本,包括“Hello World”示例
借助该数据集,我们还开源了一个数据管道,用于在流行的 Tensorflow、PyTorch 和 Jax 框架中解析数据集。还提供了 示例colab 笔记本。
通过发布此 Objectron 数据集,我们希望能够让研究界突破 3D 物体几何理解的极限。我们还希望促进新的研究和应用,例如视图合成、改进的 3D 表示和无监督学习。加入我们的邮件列表并访问我们的 github 页面, 随时关注未来的活动和发展。
致谢
本文中描述的研究由 Adel Ahmadyan、Liangkai Zhang、Jianing Wei、Artsiom Ablavatski、Mogan Shieh、Ryan Hickman、Buck Bourdon、Alexander Kanaukou、Chuo-Ling Chang、Matthias Grundmann 和 Tom Funkhouser 完成。我们感谢 Aliaksandr Shyrokau、Sviatlana Mialik、Anna Eliseeva 和注释团队提供的高质量注释。我们还要感谢 Jonathan Huang 和 Vivek Rathod 对 TensorFlow 对象检测 API 的指导。
评论