萦绕在脑海中的旋律通常被称为“耳虫”,这是一种众所周知且有时令人恼火的现象——耳虫一旦出现,就很难摆脱它。研究发现,无论是听还是唱,与原曲互动都会驱走耳虫。但如果你记不住歌曲的名字,只能哼唱旋律,该怎么办?
现有的将哼唱的旋律与其原始复音录音室录音进行匹配的方法面临一些挑战。由于歌词、背景人声和乐器,音乐或录音室录音的音频可能与哼唱的曲调截然不同。由于失误或故意,当有人哼唱自己演绎的歌曲时,音调、调性、节奏或韵律可能会略有不同,甚至有很大不同。这就是为什么许多现有的通过哼唱进行查询的方法将哼唱的曲调与歌曲的现有旋律或哼唱版本的数据库进行匹配,而不是直接识别歌曲。然而,这种方法通常依赖于需要手动更新的有限数据库。
Hum to Search 于 10 月推出,是 Google 搜索中一个全新的完全机器学习的系统,它允许用户仅使用哼唱的版本来查找歌曲。与现有方法相比,这种方法从歌曲的声谱图中生成旋律的嵌入,而无需生成中间表示。这使模型能够将哼唱的旋律直接与原始(复音)录音相匹配,而无需每个音轨的哼唱或 MIDI 版本或其他复杂的手工逻辑来提取旋律。这种方法大大简化了 Hum to Search 的数据库,使其能够不断更新来自世界各地的原始录音的嵌入 - 甚至是最新版本。
背景
许多现有的音乐识别系统在处理音频样本之前会将其转换为频谱图,以便找到良好的匹配。然而,识别哼唱旋律的一个挑战是,哼唱的曲调通常包含的信息相对较少,正如这首哼唱的《Bella Ciao》所示。哼唱版本与相应录音室录音中的相同片段之间的差异可以通过频谱图可视化,如下所示:
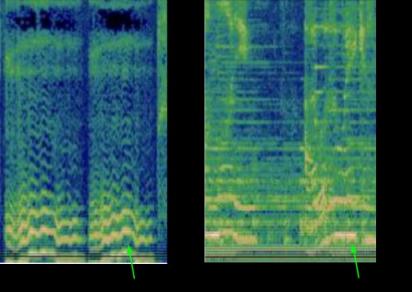
可视化哼唱片段和匹配的录音室录音。
给定左侧的图像,模型需要从超过 5000 万张外观相似的图像(对应于其他歌曲的录音室录音片段)中找到与右侧图像相对应的音频。为了实现这一点,模型必须学会专注于主导旋律,忽略背景人声、乐器和声音音色,以及由背景噪音或房间混响引起的差异。为了用肉眼找到可能用于匹配这两个频谱图的主导旋律,人们可能会在上面图像底部附近的线条中寻找相似之处。
之前为实现音乐发现所做的努力,特别是在识别咖啡馆或俱乐部等环境中播放的录制音乐方面,展示了如何将机器学习应用于这一问题。2017 年向 Pixel 手机发布的Now Playing使用设备上的深度神经网络识别歌曲,无需服务器连接,而Sound Search进一步开发了这项技术,提供基于服务器的识别服务,可以更快、更准确地搜索超过 1 亿首歌曲。接下来的挑战是利用从这些版本中学到的知识,从同样庞大的歌曲库中识别哼唱或演唱的音乐。
机器学习设置
开发 Hum to Search 的第一步是修改 Now Playing 和 Sound Search 中使用的音乐识别模型,使其能够处理哼唱的录音。原则上,许多此类检索系统(例如图像识别)的工作方式类似。神经网络通过成对的输入(此处为哼唱或歌唱的音频与录音的音频对)进行训练,为每个输入生成嵌入,这些嵌入稍后将用于匹配哼唱的旋律。
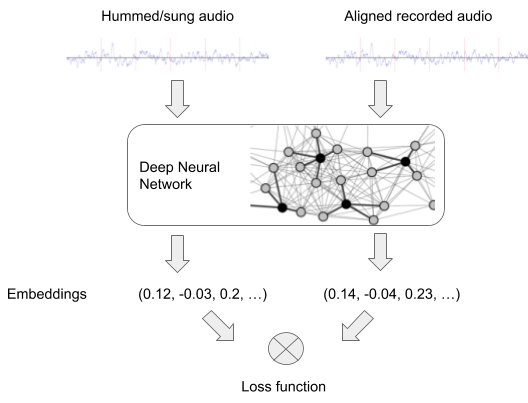
神经网络的训练设置
为了实现哼唱识别,网络应生成包含相同旋律的音频对彼此接近的嵌入,即使它们具有不同的乐器伴奏和歌声。包含不同旋律的音频对应该相距很远。在训练中,网络会提供这样的音频对,直到它学会生成具有此属性的嵌入。
然后,经过训练的模型可以为与歌曲参考录音的嵌入相似的曲调生成嵌入。找到正确的歌曲只需从根据流行音乐音频计算出的参考录音数据库中搜索类似的嵌入即可。
训练数据
因为训练模型需要歌曲对(录音和演唱),所以第一个挑战是获取足够的训练数据。我们的初始数据集主要由演唱的音乐片段组成(其中很少有哼唱)。为了使模型更加稳健,我们在训练过程中增强了音频,例如通过随机改变演唱输入的音高或节奏。最终的模型对于唱歌的人足够好,但对于哼唱或吹口哨的人则不太好。
为了提高模型在哼唱旋律方面的表现,我们使用SPICE从现有音频数据集生成了模拟“哼唱”旋律的额外训练数据,SPICE 是我们团队在FreddieMeter项目中开发的音高提取模型。SPICE 从给定的音频中提取音高值,然后我们使用这些音高值生成由离散音频音调组成的旋律。该系统的第一个版本将这个原始剪辑转换为这些音调。
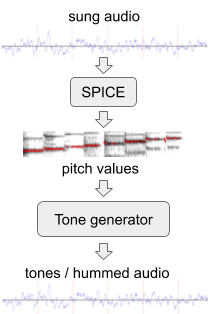
从歌声生成哼唱音频
后来,我们改进了这种方法,用神经网络代替了简单的音调生成器,该神经网络可以生成类似于实际哼唱或吹口哨的音频。例如,网络从上面的歌声片段中生成了这个哼唱示例或吹口哨示例。
最后一步,我们通过混合和匹配音频样本来比较训练数据。例如,如果我们有两个不同歌手的类似片段,我们会将这两个片段与我们的初步模型对齐,从而能够向模型显示另一对代表相同旋律的音频片段。
机器学习改进
在训练 Hum to Search 模型时,我们从三重态损失函数开始。事实证明,这种损失在各种分类任务(如图像和录制音乐)中表现良好。给定一对对应于相同旋律的音频(嵌入空间中的点 R 和 P,如下所示),三重态损失将忽略来自不同旋律的某些部分训练数据。这有助于机器学习改进学习行为,无论是当它发现一个太“简单”的不同旋律时,因为它已经离 R 和 P 很远(参见点 E),还是因为它太难,考虑到模型的当前学习状态,音频最终太接近 R — — 即使根据我们的数据,它代表不同的旋律(参见点 H)。

示例音频片段可视化为嵌入空间中的点
我们发现,通过考虑这些额外的训练数据(点 H 和 E),我们可以提高模型的准确率,即通过制定一批示例中模型置信度的一般概念:模型有多确定它看到的所有数据都可以正确分类,或者它是否看到了不符合其当前理解的示例?基于这种置信度概念,我们增加了一个损失,使嵌入空间所有区域的模型置信度接近 100%,从而提高了模型的准确率和召回率。
上述更改,尤其是我们对训练数据进行的变化、增强和叠加,使得部署在 Google 搜索中的神经网络模型能够识别唱出的或哼唱的旋律。当前系统在歌曲数据库中达到了很高的准确率,该数据库包含超过 50 万首歌曲,我们正在不断更新这些歌曲。这个歌曲语料库仍有增长空间,以涵盖世界上更多的旋律。
在 Google 应用中搜索
要试用此功能,您可以打开最新版本的 Google 应用,点击麦克风图标并说“这是什么歌?”或点击“搜索歌曲”按钮,然后您就可以哼唱、唱歌或吹口哨了!我们希望 Hum to Search 可以帮助您解决耳虫问题,或者只是在您想要查找和播放歌曲而不必输入其名称的情况下为您提供帮助。
致谢
本文所述工作由 Alex Tudor、Duc Dung Nguyen、Matej Kastelic、Mihajlo Velimirović、Stefan Christoph、Mauricio Zuluaga、Christian Frank、Dominik Roblek 和 Matt Sharifi 共同完成。我们衷心感谢 Krishna Kumar、Satyajeet Salgar 和 Blaise Aguera y Arcas 的持续支持,以及与我们合作构建完整 Hum to Search 产品的所有 Google 团队。
我们还要感谢 Google 的所有同事,他们捐献了自己的歌唱或哼唱视频,为这项工作奠定了基础,还要感谢 Nick Moukhine 开发了 Google 内部的歌唱捐赠应用程序。最后,特别感谢 Meghan Danks 和 Krishna Kumar 对本文早期版本的反馈。
评论