图是实体组之间联系的有用的理论表示,并且在数据科学中用于各种目的,从按受欢迎程度对网页进行排名和绘制社交网络,到辅助导航。在许多情况下,此类应用程序需要处理包含数千亿条边的图,这太大了,无法在单台消费级机器上处理。扩展图算法的典型方法是在分布式环境中运行,即将数据(和算法)划分到多台计算机之间以并行执行计算。虽然这种方法可以处理具有数万亿条边的图,但它也带来了新的挑战。也就是说,由于每台计算机一次只能看到输入图的一小部分,因此需要处理机器间通信并设计可以分布在多台计算机上的算法。
2008 年推出了 用于实现分布式算法的框架MapReduce 。它透明地处理机器之间的通信,同时提供良好的容错能力,并启发了许多分布式计算框架的开发,包括Pregel、Apache Hadoop等等。尽管如此,开发用于非常大的图的分布式计算算法的挑战依然存在,并且在这种情况下设计有效的算法,即使是对于基本问题,例如连通分量、最大匹配或最短路径,一直是一个活跃的研究领域。虽然最近的研究已经为许多问题展示了新算法,包括我们的连通分量算法(理论和实践上)和层次聚类算法,但仍然需要能够更快地解决一系列问题的方法。
今天,我们介绍了两篇最近的论文,它们首先构建了分布式图算法的理论模型,然后演示了如何应用该模型,从而解决了这个问题。我们提出的模型自适应大规模并行计算(AMPC) 增强了 MapReduce 的理论能力,提供了一种在更少的计算轮次中解决许多图问题的途径。我们还展示了如何在实践中有效地实施AMPC 模型。我们描述的算法套件包括最大独立集、最大匹配、连通分量和最小生成树的算法,其运行速度比目前最先进的方法快 7 倍。
MapReduce 的局限性
为了理解 MapReduce 在开发图算法方面的局限性,请考虑连通分量问题的简化版本。输入是一组有根树,目标是为每个节点计算其树的根。即使是这个看似简单的问题也不容易在 MapReduce 中解决。事实上,在大规模并行计算(MPC) 模型(MapReduce、Pregel、 Apache Giraph和许多其他分布式计算框架背后的理论模型)中,人们普遍认为这个问题至少需要与log n成比例的计算轮数,其中n是图中的节点总数。虽然log n似乎不是一个很大的数字,但处理万亿边图的算法通常每轮都会将数百 TB 的数据写入磁盘,因此即使轮数稍微减少也可能带来显著的资源节省。
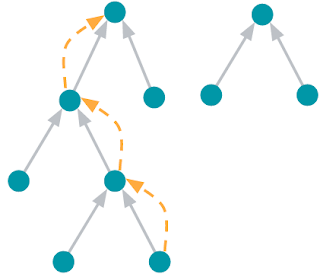
寻找根节点的问题。节点用蓝色圆圈表示。灰色箭头从每个节点指向其父节点。根节点是没有父节点的节点。橙色箭头表示算法从节点到其所属树的根节点所遵循的路径。
在我们用于查找连通分量和计算层次聚类的 算法中也出现了类似的子问题。我们发现,可以通过使用分布式哈希表(DHT) 实现这些算法来绕过 MapReduce 的限制。分布式哈希表是一种使用键值对集合初始化然后实时返回与提供的键关联的值的服务。在我们的实现中,对于每个节点,DHT 都会存储其父节点。然后,处理图形节点的机器可以使用 DHT 并“向上走”树直到到达根。虽然使用 DHT 可以很好地解决这个特定问题(尽管它依赖于输入树不太深),但尚不清楚这个想法是否可以更广泛地应用。
自适应大规模并行计算模型
为了将这种方法扩展到其他问题,我们首先开发了一个模型来从理论上分析利用 DHT 的算法。由此产生的 AMPC 模型建立在成熟的 MPC 模型之上,并正式描述了使用分布式哈希表所带来的功能。
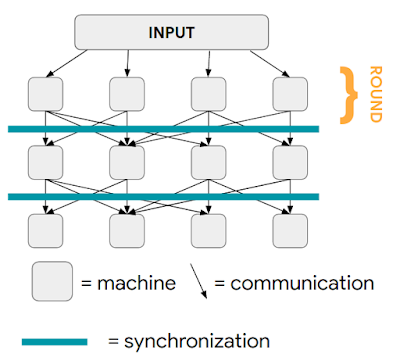
在 MPC 模型中,有一组机器,它们通过同步轮次中的消息传递进行通信。在一轮中发送的消息将在下一轮开始时传递,并构成该轮的全部输入(即机器不会从一轮保留到下一轮的信息)。在第一轮中,可以假设输入在机器之间随机分布。目标是尽量减少计算轮次的数量,同时确保每轮中机器之间的负载平衡。
MPC 模型中的计算。每列代表后续计算轮次中的一台机器。一旦所有机器都完成了一轮计算,该轮次发送的所有消息都会被传递,然后开始下一轮计算。
然后,我们通过引入一种新方法正式化了 AMPC 模型,在这种方法中,机器每轮写入只写分布式哈希表,而不是通过消息进行通信。一旦新一轮开始,上一轮的哈希表将变为只读,并且新的只写输出哈希表将可用。重要的是,只有通信方法发生了变化 — 每台机器的通信量和可用空间受到的限制与 MPC 模型中完全相同。因此,从高层次上讲,AMPC 模型的附加功能是每台机器都可以选择要读取的数据,而不是提供一段数据。
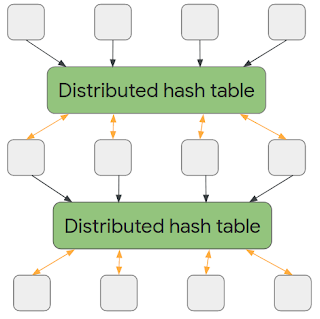
AMPC 模型中的计算。一旦所有机器都完成了一轮计算,它们产生的数据就会保存到分布式哈希表中。在下一轮中,每台机器都可以从这个分布式哈希表中读取任意值并写入新的分布式哈希表。
算法与实证评估
机器通信方式的这种看似微小的差异使我们能够设计出更快的算法来解决许多基本图形问题。具体来说,我们表明,无论图形的大小如何,都可以在恒定的轮次内找到连通分量、最小生成树、最大匹配和最大独立集。
为了研究 AMPC 算法的实际适用性,我们通过将 Flume C++(FlumeJava的 C++ 对应物)与 DHT 通信层相结合来实例化该模型。我们针对最小生成树、最大独立集和最大匹配对 AMPC 算法进行了评估,并观察到与未使用 DHT 的实现相比,我们可以实现高达 7 倍的速度提升。同时,AMPC 实现平均 完成的轮次减少了 10 倍,并且写入磁盘的数据也更少。
我们对 AMPC 模型的实现利用了硬件加速的远程直接内存访问(RDMA),这项技术允许从远程机器的内存中读取数据,延迟仅为几微秒,这仅比从本地内存中读取慢一个数量级。 虽然一些 AMPC 算法传输的数据比 MPC 算法要多,但它们总体上更快,因为它们主要使用 RDMA 执行快速读取,而不是昂贵的磁盘写入。
结论
利用 AMPC 模型,我们构建了一个受实际高效实现启发的理论框架,然后开发了新的理论算法,这些算法提供了良好的经验性能并保持了良好的容错特性。我们很高兴看到 AMPC 模型已经成为进一步研究的主题,并且很高兴了解使用 AMPC 模型或其实际实现可以更有效地解决哪些其他问题。
致谢
本博文中介绍的两篇论文的合著者包括 Soheil Behnezhad、Laxman Dhulipala、Hossein Esfandiari 和 Warren Schudy。我们还感谢Graph Mining 团队的成员的合作,特别是 Mohammad Hossein Bateni 对本文的贡献。要了解有关我们最近在可扩展图形算法方面的工作的更多信息,请观看我们最近的Graph Mining and Learning 研讨会的视频。
评论