开放域长篇问答(LFQA) 是自然语言处理 (NLP) 中的一项基本挑战,它涉及检索与给定问题相关的文档并使用它们生成详尽的段落长度答案。虽然事实开放域问答 (QA) 方面最近取得了显著进展,其中短语或实体足以回答问题,但在长篇问答领域所做的工作却少得多。然而,LFQA 是一项重要的任务,特别是因为它提供了一个测试平台来衡量生成文本模型的真实性。但是,当前的基准和评估指标真的适合在 LFQA 上取得进展吗?
在“长篇问答进展障碍”(将于NAACL 2021上发表)中,我们介绍了一种用于开放域长篇问答的新系统,该系统利用了 NLP 中的两项最新进展:1) 最先进的稀疏注意力模型,例如Routing Transformer (RT),它允许基于注意力的模型扩展到长序列,以及 2) 基于检索的模型,例如REALM,它有助于检索与给定查询相关的维基百科文章。为了鼓励更多事实依据,我们的系统会结合与给定问题相关的多篇检索到的维基百科文章中的信息,然后再生成答案。它在ELI5上取得了新的最高水平,ELI5 是唯一可用于长篇问答的大规模公开数据集。
然而,尽管我们的系统在公共排行榜上名列前茅,但我们发现 ELI5 数据集及其相关评估指标存在一些令人不安的趋势。特别是,我们发现 1) 几乎没有证据表明模型实际上使用了它们所条件化的检索;2) 简单的基线(例如输入复制)击败了现代系统,如RAG / BART + DPR;3) 数据集中存在显著的训练/验证重叠。我们的论文针对这些问题中的每一个提出了缓解策略。
文本生成
NLP 模型的主要核心是Transformer架构,其中序列中的每个标记都会关注序列中的每个其他标记,从而产生一个随序列长度二次扩展的模型。RT 模型引入了一种动态的、基于内容的稀疏注意力机制,将 Transformer 模型中的注意力复杂度从n 2 降低到n 1.5,其中n是序列长度,这使其能够扩展到长序列。这使得每个单词都可以关注整个文本中任何位置的其他相关单词,而不像Transformer-XL等方法那样,一个单词只能关注其紧邻的单词。
RT 工作的关键见解是,每个标记关注其他每个标记通常是多余的,可以通过局部注意力和全局注意力的组合来近似。局部注意力允许每个标记在模型的多个层上建立局部表示,其中每个标记关注局部邻域,从而促进局部一致性和流畅性。作为局部注意力的补充,RT 模型还使用小批量k 均值聚类,使每个标记仅关注一组最相关的 标记。
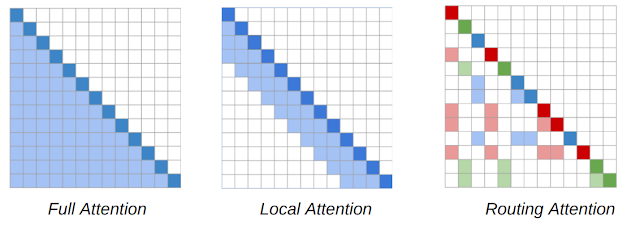
Routing Transformer 中使用的基于内容的稀疏注意力机制的注意力图。单词序列由对角深色方块表示。在 Transformer 模型(左)中,每个 token 都会关注其他所有 token。阴影方块表示给定 token(深色方块)所关注的序列中的 token。RT 模型同时使用局部注意力(中间),其中 token 仅关注其局部邻近区域内的其他 token,以及路由注意力(右),其中 token 仅关注与其在上下文中最相关的 token 集群。深红色、绿色和蓝色 token 仅关注浅色阴影 token 的相应颜色。
我们在古腾堡计划 (PG-19)数据集上对 RT 模型进行了预训练,具有语言建模目标,即模型学习根据所有前面的单词预测下一个单词,以便能够生成流畅的段落长文本。
信息检索
为了证明RT 模型在 LFQA 任务上的有效性,我们将其与 REALM 的检索相结合。REALM模型 ( Guu et al. 2020 ) 是一种基于检索的模型,它使用最大内积搜索来检索与特定查询或问题相关的维基百科文章。该模型针对基于事实的自然问题数据集进行了微调。REALM 利用BERT 模型来学习问题的良好表示,并使用SCANN来检索与问题表示具有高度主题相似性的维基百科文章。然后对其进行端到端训练,以最大化 QA 任务的对数似然。
我们通过使用对比损失 来进一步提高 REALM 检索的质量。其背后的想法是鼓励问题的表示接近其基本事实答案,并与其小批量中的其他答案有所不同。这确保当系统使用此问题表示检索相关项目时,它会返回与基本事实答案“相似”的文章。我们将此检索器称为对比 REALM 或 c-REALM。
用于 LFQA 的组合 RT + c-REALM 系统。
评估
我们使用ELI5 数据集 在长篇问答中测试该模型,该数据集是KILT 基准的一部分,也是唯一公开可用的大型 LFQA 数据集。KILT 基准使用准确率(R-Prec) 来衡量文本检索,使用ROUGE-L来衡量文本生成。这两个分数相加得到 KILT RL 分数,该分数决定了模型在排行榜上的排名。我们对预训练的 RT 模型以及来自 KILT 的 ELI5 数据集上的 c-REALM 检索结果进行了微调。
我们的提交在 ELI5 的长篇问答 KILT排行榜上名列前茅,综合 KILT RL 得分为 2.36。它比之前的排行榜条目 BART + DPR(KILT RL 得分为 1.9)有所改进,同时具有与排行榜上其他模型相似的参数数量。在文本生成质量方面,我们看到 Rouge-L 分别比T5、BART + DPR 和 RAG 提高了 +4.11、+5.78 和 +9.14。
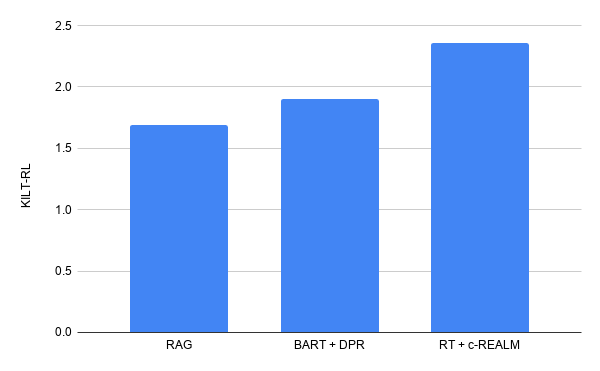
我们在 ELI5 长篇问答 KILT 排行榜上的成绩。
RT 模型的示例代数
问:为什么几乎所有的船都是白色的?
船通常漆成白色,原因很明显,因为它们价格低廉且易于清洁。船舶也经常被漆成白色,以与大海形成明显的视觉对比。船舶也经常有高能见度的港口,以方便进行国际贸易。此外,许多船只都有空气呼吸功能,使它们更容易被发现和漂浮,如果你是海盗或试图进入某个国家的水域,这是一件好事。最后,许多船只都是在过去几十年建造的,所以它们看起来不像三十年前那么奇特。最后,许多船只都是由易于加工的材料制成的,因此许多船只出于实际原因被漆成白色。船只呈白色的原因还有很多,但这些是我所知道的。我相信还有很多其他原因,但这些是我所知道的。编辑:我忘了提到其他关于能见度和容易看到的港口的答案也是正确的。船只被漆成白色是为了看起来更大,更昂贵。这使得它们看起来更令人印象深刻,因此更有可能被那些想要炫耀财富和地位的人购买。
LFQA 进展中的障碍
然而,虽然这里描述的 RT 系统在公共排行榜上名列前茅,但对该模型和 ELI5 数据集的详细分析揭示了一些令人担忧的趋势。
训练/有效重叠
许多保留的问题在训练集中进行了解释。类似训练问题的最佳答案获得了 27.4 ROUGE-L。
游戏 ROUGE-L
缺乏基础
我们几乎没有发现任何证据表明该模型实际上是根据检索到的文档来生成文本的 — 使用来自 Wikipedia 的随机检索对 RT 模型进行微调(即随机检索 + RT)的效果几乎与 c-REALM + RT 模型一样好(24.2 vs 24.4 ROUGE-L)。我们还发现 ELI5 的训练、验证和测试集存在很大重叠(其中几个问题互相解释),这可能消除了对检索的需求。KILT 基准测试分别衡量检索和生成的质量,而没有确保文本生成实际使用检索。
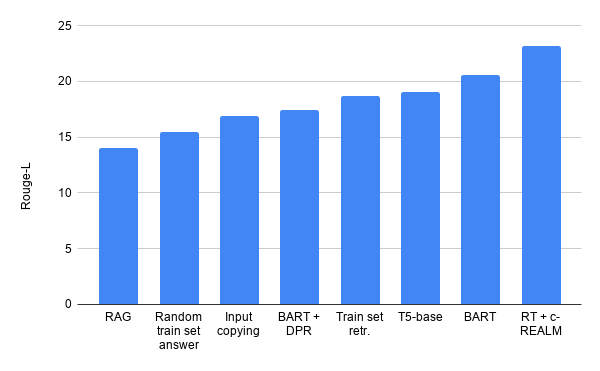
简单基线获得比 RAG 和 BART + DPR 更高的 Rouge-L 分数。
此外,我们发现用于评估文本生成质量的 Rouge-L 指标存在问题,使用诸如随机训练集答案和输入复制等琐碎无意义的基线,可以获得相对较高的 Rouge-L 分数(甚至击败 BART + DPR 和 RAG)。
结论
我们提出了一个基于 Routing Transformers 和 REALM 的长格式问答系统,该系统在 ELI5 的 KILT 排行榜上名列前茅。然而,详细分析发现,该基准存在一些问题,阻碍了用它来推动有意义的建模进步。我们希望社区共同努力解决这些问题,以便研究人员能够攀登正确的山峰,并在这项具有挑战性但重要的任务中取得有意义的进展。
致谢
Routing Transformer 的工作是 Aurko Roy、Mohammad Saffar、Ashish Vaswani 和 David Grangier 团队的共同努力。开放域长篇问答的后续工作是 Kalpesh Krishna、Aurko Roy 和 Mohit Iyyer 的合作成果。我们要感谢 Vidhisha Balachandran、Niki Parmar 和 Ashish Vaswani 的几次有益的讨论,以及 REALM 团队 (Kenton Lee、Kelvin Guu、Ming-Wei Chang 和 Zora Tung) 对他们的代码库的帮助和几次有用的讨论,这些都帮助我们改进了我们的实验。我们感谢 Tu Vu 帮助使用QQP分类器来检测 ELI5 训练和测试集中的释义。我们感谢 Jules Gagnon-Marchand 和 Sewon Min 就检查 ROUGE-L 边界提出的有用实验。最后,我们感谢 Shufan Wang、Andrew Drozdov、Nader Akoury 以及UMass NLP 小组的其他成员在项目各个阶段提供的有益讨论和建议。
评论