人们可以很容易地从图片中检索有关 3D 环境的视觉信息——我们可以识别物体、确定实例大小并重建 3D 场景布局,所有这些都使用 2D 图像中包含的有限信号。这种能力通常被称为逆投影问题,指的是重建从视网膜图像到视网膜刺激源的模糊映射。现实世界的计算机视觉应用,例如自动驾驶,严重依赖这些功能来定位和识别 3D 物体,这需要视觉模型推断投影到 2D 图像的每个 3D 点的空间位置、语义类别和实例标签。从图像重建 3D 世界的能力可以分解为两个不相交的计算机视觉任务:单目深度估计(从单个图像预测深度)和视频全景分割(视频域中实例分割和语义分割的统一)。然而,研究通常分别考虑每个任务。使用统一的计算机视觉模型共同解决这些任务可以通过在多个任务之间共享计算来实现更容易的部署和更高的效率。
受同时预测深度和视频全景分割的模型的潜在价值的驱动,我们提出了“ ViP-DeepLab:通过深度感知视频全景分割学习视觉感知”,并被CVPR 2021接受。在这项工作中,我们提出了一项新任务,即深度感知视频全景分割,旨在同时解决单目深度估计和视频全景分割问题。对于新任务,我们提出了两个派生数据集,并附带一个称为深度感知视频全景质量(DVPQ) 的新评估指标。这个新指标包括深度估计和视频全景分割的指标,需要一个视觉模型来同时处理这两个子任务。为此,我们通过添加用于深度和视频预测的网络分支来扩展Panoptic-DeepLab,以创建 ViP-DeepLab,这是一个统一的模型,可联合执行图像平面上每个像素的视频全景分割和单目深度估计,并在子任务的多个学术数据集上实现最先进的性能。该视频演示了新任务并展示了ViP-DeepLab的结果。

ViP-DeepLab 获得的深度感知视频全景分割结果。左上:用作输入的视频帧。右上:视频全景分割结果。左下:估计深度。右下:重建的 3D 点。每个对象实例都有一个唯一且时间一致的标签,例如 pedestrain_1、pedestrain_2 等。输入图像来自Cityscapes 数据集。
概述
虽然 Panoptic-DeepLab 能够输出单帧的语义分割、中心预测和中心回归,但它缺乏对多帧进行深度估计和时间一致的实例 ID 预测的能力。然而,ViP-DeepLab 通过从两个连续帧作为输入执行额外的预测来实现这一点。第一个额外的输出是第一帧的深度估计,它为每个像素分配一个估计的深度。此外,ViP-DeepLab 还对两个连续帧执行中心回归,仅针对第一帧中出现的对象中心。这个过程称为中心偏移预测,它允许 ViP-DeepLab 将两帧中的所有像素分组到第一帧中出现的同一对象。如果新实例没有分组到先前检测到的实例中,就会出现它们。这个过程在视频序列中的每两个连续帧(有一个重叠帧)继续进行,将全景预测拼接在一起以形成具有时间一致的实例 ID 的预测。也就是说,它将对象的位置以及它们在视频场景中随时间移动的方式拼接在一起。

ViP-DeepLab 视频全景分割的输出。两个连续帧连接在一起作为输入。语义分割输出将每个像素与其语义类别相关联,而实例分割输出则识别与第一帧中单个对象相关联的两个帧中的像素。输入图像来自Cityscapes 数据集。
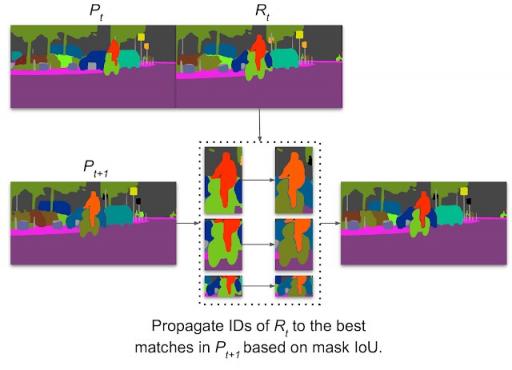
拼接视频全景预测的可视化。ViP-DeepLab 根据区域对之间的掩码交并比来传播 ID 。它能够跟踪具有大幅度运动的物体,例如图像中的骑自行车的人。
神经网络设计
在Panoptic-DeepLab 的基础上,ViP-DeepLab 还包含两个预测分支:(1) 深度预测分支,(2) 下一帧实例分支。具体来说,深度预测头是一种简单的设计,可预测每个像素的深度回归,而下一帧实例分支可预测第二帧中像素相对于第一帧中中心的中心偏移。
结果
我们已经在多个流行基准上测试了 ViP-DeepLab,包括Cityscapes-VPS、KITTI 深度预测和KITTI 多目标跟踪和分割(MOTS)。
具体来说,ViP-DeepLab 取得了最先进 (SOTA) 的结果,在 Cityscapes-VPS 测试集上,视频全景质量 (VPQ) 明显优于以前的方法 5.1%。
方法 VPQ全部 VPQ事物 VPQ资料
VPS网 57.4% 45.8% 64.8%
ViP-DeepLab 62.5%(+5.1%) 50.2%(+4.4%) 70.3%(+5.5%)
在 Cityscapes-VPS 测试集上的 VPQ 比较。
ViP-DeepLab在 KITTI 深度预测基准上排名第一,比以前的方法提高了 0.65 SILog (越小越好)。
方法 SI日志 平方误差 绝对误差相对 均方根误差
渐进式网页 11.45 2.30 9.05 12.32
ViP-DeepLab 10.80 2.19 8.94 11.77
KITTI 深度预测基准上的单目深度估计比较。请注意,对于深度估计指标,值越小,性能越好。虽然差异可能看起来很小,但此基准上表现最佳的方法在 SILog 中的差距通常小于 0.1。
此外,根据sMOTSA指标排名,ViP-DeepLab在 KITTI MOTS行人识别中排名第一,在KITTI MOTS 汽车识别中排名第三,而根据较新的HOTA指标排名,ViP-DeepLab 在行人和汽车识别中均排名第三。
班级 方法 霍塔
车 点轨迹 62.0%
ViP-DeepLab 76.4%(+14.4%)
行人 点轨迹 54.4%
ViP-DeepLab 64.3%(+9.9%)
KITTI 多目标跟踪和分割的性能比较。
最后,我们还针对新任务深度感知视频全景分割提出了两个新数据集,并在其上测试了 ViP-DeepLab。我们希望我们在这两个新数据集上的 ViP-DeepLab 结果将成为社区进行比较的强大基准。结果如下所示。
数据集 DVPQ全部 DVPQ事物 DVPQ资料
城市景观-DVPS 55.1% 43.3% 63.6%
森基蒂-DVPS 45.6% 36.6% 52.2%
ViP-DeepLab 在两个新数据集上执行深度感知视频全景分割任务的性能。
结论
ViP-DeepLab 架构简单,在视频全景分割、单目深度估计以及多目标跟踪与分割方面实现了最佳性能。我们希望,ViP-DeepLab 能够与MaX-DeepLab(提出了一种高效的双路径转换器模块,可实现端到端图像全景分割)一起为社区服务,并进一步研究如何更全面地了解现实世界中的场景。
致谢
我们要感谢 Yukun Zhu、Hartwig Adam 和 Alan Yuille(ViP-DeepLab 的合著者)以及 Maxwell Collins 和 Mobile Vision 团队的支持和宝贵讨论。
评论