序列到序列 ( seq2seq ) 模型已成为解决自然语言生成任务的首选方法,其应用范围从机器翻译到单语生成任务,例如摘要、句子融合、文本简化和机器翻译后编辑。然而,这些模型似乎不是许多单语任务的最佳选择,因为所需的输出文本通常代表对输入文本的少量改写。在完成此类任务时,seq2seq 模型速度较慢,因为它们一次生成一个单词的输出(即自回归),并且浪费资源,因为大多数输入标记只是被简单地复制到输出中。
相反,文本编辑模型最近引起了人们的浓厚兴趣,因为它们提出预测应用于输入以重建输出的编辑操作(例如单词删除、插入或替换)。然而,以前的文本编辑方法有局限性。它们要么很快(非自回归),但不灵活,因为它们使用有限数量的编辑操作,要么很灵活,支持所有可能的编辑操作,但速度很慢(自回归)。无论哪种情况,它们都没有专注于对大型结构(句法)转换进行建模,例如从主动语态“他们晚餐吃牛排”切换到被动语态“晚餐吃了牛排”。相反,他们专注于局部转换,删除或替换短语。当需要进行大规模结构转换时,它们要么无法产生它,要么插入大量新文本,这很慢。
在“ FELIX:通过标记和插入实现灵活的文本编辑”中,我们介绍了 FELIX,这是一种快速灵活的文本编辑系统,可对大型结构变化进行建模,与 seq2seq 方法相比,速度提高了 90 倍,同时在四个单语生成任务上取得了令人印象深刻的成果。与传统的 seq2seq 方法相比,FELIX 具有以下三个主要优势:
样本效率:训练高精度文本生成模型通常需要大量高质量的监督数据。FELIX 使用三种技术来最大限度地减少所需的数据量:(1)微调预训练检查点,(2)学习少量编辑操作的标记模型,以及(3)与预训练任务非常相似的文本插入任务。
推理时间快: FELIX 完全是非自回归的,避免了自回归解码器导致的推理时间慢。
灵活的文本编辑: FELIX 在学习的编辑操作的复杂性和它建模的转换的灵活性之间取得了平衡。
简而言之,FELIX 旨在从自我监督预训练中获得最大收益,在资源匮乏的环境中以很少的训练数据就能高效运行。
概述
为了实现上述目标,FELIX 将文本编辑任务分解为两个子任务:标记(决定输入词的子集及其在输出文本中的顺序)和插入(插入输入中不存在的词)。标记模型采用一种新颖的指针机制,支持结构转换,而插入模型则基于掩码语言模型。这两个模型都是非自回归的,确保模型速度很快。FELIX 的图表如下所示。
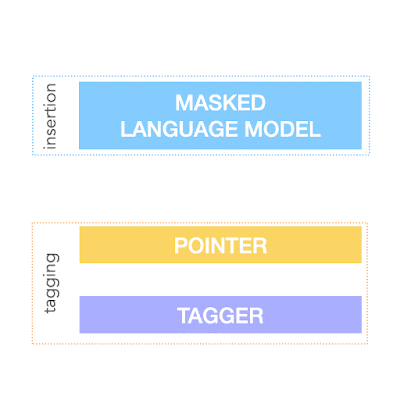
这是针对文本简化任务的数据进行 FELIX 训练的示例。输入词首先被标记为 KEEP (K)、DELETE (D) 或 KEEP 和 INSERT (I)。标记后,输入被重新排序。然后,重新排序的输入被输入到掩码语言模型中。
标记模型
FELIX 的第一步是标记模型,它由两个部分组成。首先,标记器确定应保留或删除哪些词以及应在何处插入新词。当标记器预测插入时,会将特殊的MASK标记添加到输出中。标记之后,有一个重新排序步骤,指针将重新排序输入以形成输出,这样它就可以重用输入的部分内容,而不是插入新文本。重新排序步骤支持任意重写,从而可以对较大的更改进行建模。指针网络经过训练,使得输入中的每个单词都指向输出中出现的下一个单词,如下所示。

实现将“心脏壁有3层”转化为“心脏MASK有3层”的指向机制。
插入模型
标记模型的输出是重新排序的输入文本,其中删除了单词和插入标记预测的MASK标记。插入模型必须预测MASK标记的内容。由于 FELIX 的插入模型与BERT的预训练目标非常相似,因此它可以直接利用预训练,这在数据有限时尤其有利。
插入模型的示例,其中标记器预测将插入两个单词,并且插入模型预测 MASK 标记的内容。

结果
我们对 FELIX 在句子融合、文本简化、抽象摘要和机器翻译后编辑方面进行了评估。这些任务在所需的编辑类型和所针对的数据集大小方面差异很大。以下是在句子融合任务(即将两个句子合并为一个句子)上的结果,在一系列数据集大小下,将 FELIX 与大型预训练的 seq2seq 模型(BERT2BERT)和文本编辑模型(LaserTager)进行了比较。我们发现 FELIX 的表现优于 LaserTagger,并且只需几百个训练示例即可进行训练。对于完整数据集,自回归 BERT2BERT 的表现优于 FELIX。但是,在推理过程中,该模型需要的时间明显更长。
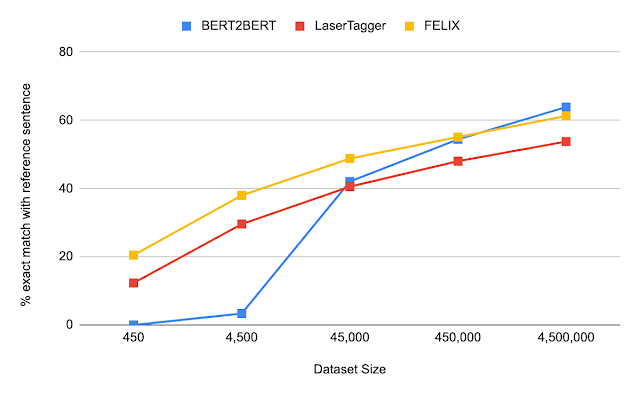
DiscoFuse 数据集上不同训练数据集大小的比较。我们将 FELIX(使用性能最佳的模型)与 BERT2BERT 和 LaserTagger 进行比较。
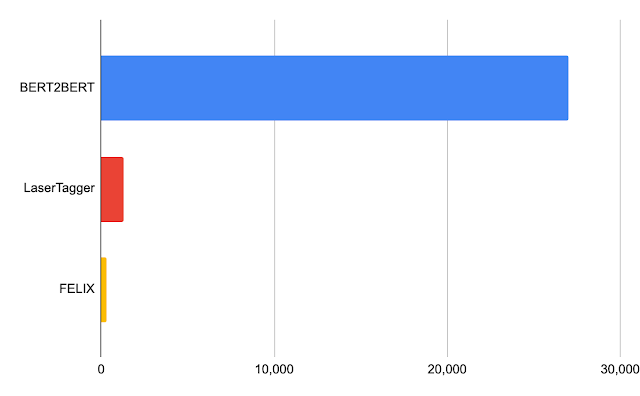
Nvidia Tesla P100 上 32 个批次的延迟(以毫秒为单位)。
结论
我们提出了完全非自回归的 FELIX,它提供了更快的推理时间,同时实现了最先进的结果。FELIX 还通过三种技术最大限度地减少了所需的训练数据量——微调预训练检查点、学习少量编辑操作以及模仿预训练中的掩码语言模型任务的插入任务。最后,FELIX 在学习的编辑操作的复杂性和它可以处理的输入输出转换百分比之间取得了平衡。我们已经开源了FELIX 的代码,希望它能为研究人员提供更快、更高效、更灵活的文本编辑模型。
致谢
这项研究由 Jonathan Mallinson、Aliaksei Severyn(同等贡献)、Eric Malmi 和 Guillermo Garrido 进行。我们要感谢 Aleksandr Chuklin、Daniil Mirylenka、Ryan McDonald 和 Sebastian Krause 的有益讨论、早期实验和论文建议。
评论