大家普遍认为,深度强化学习研究(将传统强化学习与深度神经网络相结合)的巨大发展始于开创性的DQN算法的发布。这篇论文展示了这种组合的潜力,表明它可以产生能够非常有效地玩多种 Atari 2600 游戏的代理。从那时起,出现了几种 基于原始 DQN 并对其进行改进的方法。流行的Rainbow 算法结合了许多最新进展,在ALE 基准上实现了最先进的性能。然而,这一进步是以非常高的计算成本为代价的,这带来了一个不良的副作用,即扩大了拥有充足计算资源的人与没有充足计算资源的人之间的差距。
在即将于ICML 2021上发表的 “重温 Rainbow:促进更具洞察力和包容性的深度强化学习研究”中,我们将在一组中小型任务上重温该算法。我们首先讨论与 Rainbow 算法相关的计算成本。我们探索如何通过较小规模的实验得出关于结合各种算法组件的好处的相同结论,并进一步将这个想法推广到如何在较小的计算预算下进行的研究可以提供有价值的科学见解。
彩虹的代价
Rainbow 计算成本高的一个主要原因是,学术出版的标准通常要求在大型基准测试(如ALE)上评估新算法,ALE 包含 57 个强化学习代理可以学习玩的 Atari 2600 游戏。对于一款典型的游戏,使用Tesla P100 GPU训练模型大约需要五天时间。此外,如果想要建立有意义的置信界限,通常需要进行至少五次独立运行。因此,要对 Rainbow 进行全套 57 款游戏的训练,需要大约 34,200 GPU 小时(或 1425 天)才能提供令人信服的经验性能统计数据。换句话说,这样的实验只有在能够并行在多个 GPU 上训练时才可行,而这对于较小的研究小组来说是难以承受的。
重温彩虹
与原始 Rainbow 论文一样,我们评估了在原始 DQN 算法中添加以下组件的效果:双 Q 学习、优先经验重放、决斗网络、多步学习、分布式 RL和噪声网络。
我们对一组四种经典控制环境进行了评估,这些环境可以在 10-20 分钟内完成训练(而 ALE 游戏则需要五天):
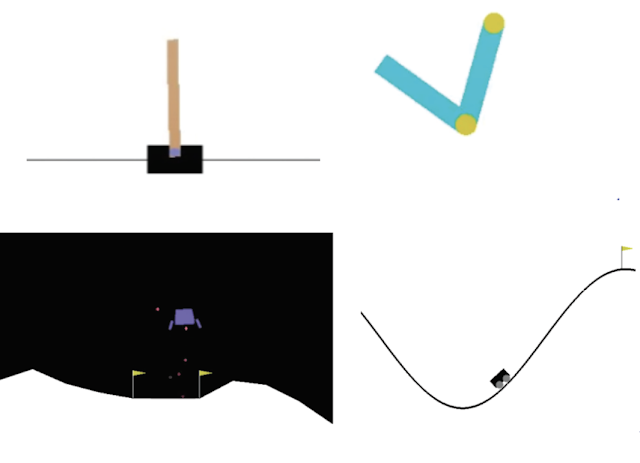
左上:在CartPole中,任务是平衡手推车上的杆子,代理可以左右移动手推车。右上:在Acrobot中,有两个臂和两个关节,代理向两个臂之间的关节施加力,以便将下臂抬高到阈值以上。左下:在LunarLander中,代理要将宇宙飞船降落在两面旗帜之间。右下:在MountainCar中,代理必须在两座山之间积聚动力,才能驶向最右边的山顶。
我们研究了将每个组件独立添加到 DQN 以及从完整的 Rainbow 算法中删除每个组件的效果。与原始 Rainbow 论文一样,我们发现,总体而言,添加这些算法确实比基础 DQN 提高了学习效果。但是,我们也发现了一些重要的区别,例如分布式 RL(通常被认为是一种积极的补充)本身并不总是能带来改进。事实上,与 Rainbow 论文中的 ALE 结果相反,在经典控制环境中,分布式 RL 只有在与另一个组件结合时才会产生改进。
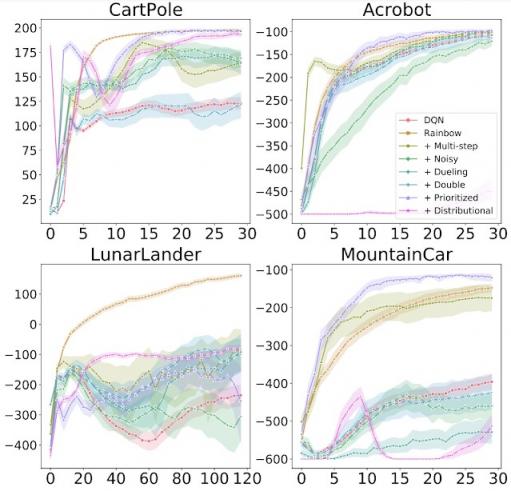
每个图都显示了将各个组件添加到 DQN 时的训练进度。x 轴表示训练步骤,y 轴表示性能(越高越好)。
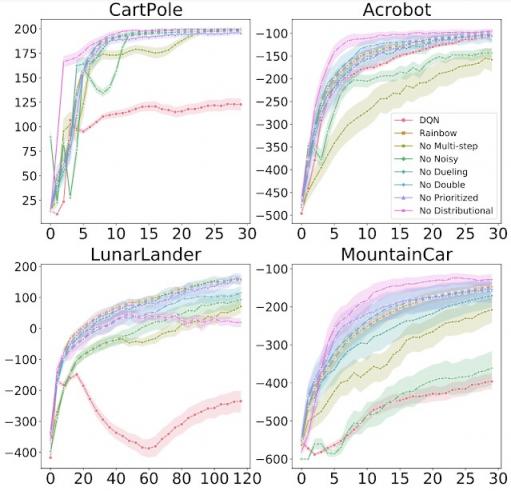
每个图都显示了从 Rainbow 中移除各个组件时的训练进度。x 轴表示训练步骤,y 轴表示性能(越高越好)。
我们还在MinAtar 环境(由一组五款小型 Atari 游戏组成) 上重新运行了 Rainbow 实验,并发现了定性相似的结果。MinAtar 游戏的训练速度大约是常规 Atari 2600 游戏的 10 倍(原始 Rainbow 算法就是在这些游戏上进行评估的),但仍有一些有趣的方面,例如游戏动态和对代理的像素输入。因此,它们提供了一个具有挑战性的中级环境,介于经典控制和完整的 Atari 2600 游戏之间。
从总体来看,我们发现我们的结果与原始 Rainbow 论文 的结果一致——每个算法组件产生的影响可能因环境而异。如果我们要提出一个平衡不同算法组件权衡的单一代理,我们的 Rainbow 版本可能与原始版本一致,因为结合所有组件可以产生更好的整体代理。然而,不同算法组件的变化中有一些重要的细节值得更彻底的研究。
彩虹之外
在引入 DQN 时,它使用了Huber 损失和RMSProp 优化器。研究人员在 DQN 基础上构建时也通常使用这些相同的选择,因为他们的大部分精力都花在了其他算法设计决策上。本着重新评估这些假设的精神,我们重新审视了DQN在低成本、小规模经典控制和 MinAtar 环境中使用的损失函数和优化器。我们使用Adam 优化器(最近最流行的优化器选择)结合更简单的损失函数即均方误差损失(MSE) 进行了一些初步实验。由于在开发新算法时优化器和损失函数的选择经常被忽视,因此我们惊讶地发现,所有经典控制和 MinAtar 环境都得到了显著改善。
因此,我们决定在完整的 ALE 套件(60 个 Atari 2600 游戏)上评估将两个优化器(RMSProp 和 Adam)与两个损失(Huber 和 MSE)相结合的不同方式。我们发现 Adam+MSE 的组合比 RMSProp+Huber 更好。
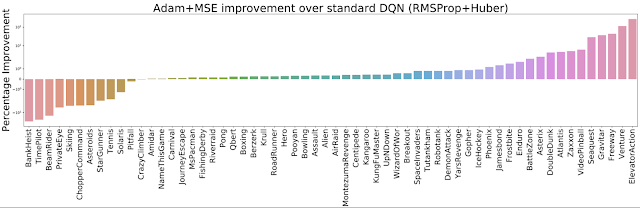
测量 Adam+MSE 相对于默认 DQN 设置(RMSProp + Huber)的改进;越高越好。
此外,在比较各种优化器损失组合时,我们发现当使用 RMSProp 时,Huber 损失往往比 MSE 表现更好(由橙色实线和虚线之间的间隙表示)。
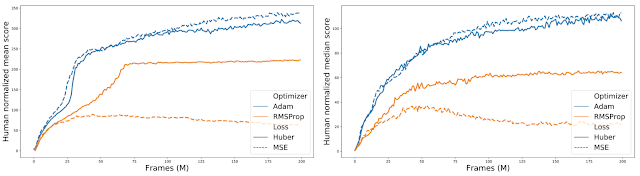
对全部 60 款 Atari 2600 游戏的归一化分数进行汇总,比较不同的优化器损失组合。
结论
在有限的计算预算下,我们能够以高水平重现Rainbow 论文的发现并发现新的有趣现象。显然,重新审视某件事比一开始就发现它要容易得多。然而,我们进行这项工作的目的是论证对中小型环境进行实证研究的相关性和重要性。我们相信,这些计算密集程度较低的环境非常适合对新算法的性能、行为和复杂性进行更严格和更彻底的分析。
我们绝不是在呼吁减少对大规模基准的重视。我们只是敦促研究人员将小规模环境视为其研究中的宝贵工具,并敦促审稿人避免忽视专注于小规模环境的实证研究。通过这样做,除了减少实验对环境的影响外,我们还能更清楚地了解研究前景,并减少来自不同且资源不足的社区的研究人员的障碍,这只会帮助我们的社区和科学进步更加强大。
致谢
感谢本文第一作者 Johan 的辛勤工作和坚持不懈!我们还要感谢 Marlos C. Machado、Sara Hooker、Matthieu Geist、Nino Vieillard、Hado van Hasselt、Eleni Triantafillou 和 Brian Tanner 对本文的深刻评论。
评论