准确记录建筑物足迹对于从人口估计和城市规划到人道主义响应和环境科学等一系列应用都很重要。洪水或地震等灾难发生后,当局需要估计有多少家庭受到影响。理想情况下,应该有最新的人口普查信息,但实际上,此类记录可能已过时或不可用。相反,建筑物位置和密度的数据可以成为有价值的替代信息来源。
收集此类数据的一个好方法是通过卫星图像,它可以绘制出世界各地的建筑物分布图,特别是在偏远或难以进入的地区。然而,在某些环境下,用计算机视觉方法检测建筑物可能是一项艰巨的任务。因为卫星成像需要从几百公里的高空拍摄地球,即使是高分辨率(30-50 厘米/像素),一栋小型建筑物或帐篷也只占据几个像素。对于非正式定居点或农村地区来说,这项任务更加困难,因为在这些地区,用天然材料建造的建筑物在视觉上可以融入周围环境。还有许多类型的自然和人工特征很容易与俯视图像中的建筑物混淆。

可能使建筑物识别计算机视觉模型感到困惑的物体(从左上角开始顺时针方向)是水池、岩石、围墙和集装箱。
在“利用高分辨率卫星图像进行大陆级建筑物检测”中,我们解决了这些挑战,使用新方法检测不同地形(如草原、沙漠和森林)以及非正式定居点和难民设施等农村和城市环境中的建筑物。我们使用这种建筑物检测模型创建了开放建筑物数据集,这是一个新的开放访问数据资源,包含 5.16 亿座建筑物的位置和足迹,覆盖非洲大陆的大部分地区。该数据集将支持多种实际、科学和人道主义应用,包括灾难响应或人口测绘、规划服务(如新医疗设施)或研究人类对自然环境的影响。
模型开发
我们通过手动标记 10 万张图像中的 175 万座建筑物,为建筑物检测模型构建了一个训练数据集。下图展示了我们如何标记训练数据中的图像的一些示例,其中考虑到了非洲大陆不同地区的混杂特征。例如,在农村地区,我们需要识别不同类型的居住地并将它们与自然特征区分开来,而在城市地区,我们需要为密集和连续的结构制定标记政策。

(1)包含住宅和粮仓等小型附属建筑的院落示例。(2)圆形茅草屋顶结构的示例,模型很难将其与树木区分开来,需要使用小路、空地和阴影的线索来消除歧义。(3)几座相邻建筑物的示例,其边界难以区分。
我们以自下而上的方式训练模型来检测建筑物,首先将每个像素分类为建筑物或非建筑物,然后将这些像素分组为单个实例。检测流程基于U-Net模型,该模型常用于卫星图像分析。U-Net 的一个优点是它是一种相对紧凑的架构,因此可以应用于大量图像数据而无需繁重的计算负担。这一点至关重要,因为将其应用于大陆规模的卫星图像的最终任务意味着要在数十亿个图像块上运行该模型。

卫星图像中建筑物分割的示例。 左图: 源图像; 中图: 语义分割,每个像素分配一个置信度分数,以区分它是建筑物还是非建筑物; 右图: 实例分割,通过阈值化和将连通分量分组获得。
使用基本模型进行初步实验时,其精确度和召回率较低,原因包括建筑物外观具有多种自然和人工特征。我们发现了许多可以提高性能的方法。其中之一是使用mixup作为正则化方法,即通过取加权平均值将随机训练图像混合在一起。虽然 mixup 最初是为图像分类而提出的,但我们对其进行了修改,使其可用于语义分割。正则化对于建筑物分割任务通常很重要,因为即使有 10 万张训练图像,训练数据也无法捕捉到模型在测试时呈现的地形、大气和光照条件的全部变化,因此有过度拟合的趋势。通过 mixup 以及训练图像的随机增强可以缓解这一问题。
我们发现另一种有效的方法是使用无监督的自我训练。我们准备了一组来自非洲各地的 1 亿张卫星图像,并将它们过滤为 870 万张图像的子集,其中大部分包含建筑物。该数据集用于使用Noisy Student方法进行自我训练,其中上一阶段最佳建筑物检测模型的输出被用作“老师”,然后训练“学生”模型,该模型根据增强图像做出类似的预测。在实践中,我们发现这减少了误报并提高了检测输出。学生模型对建筑物的置信度更高,对背景的置信度更低。
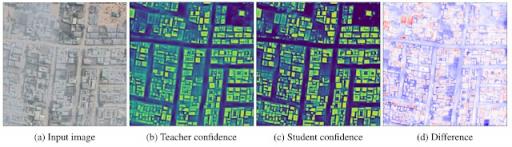
典型图像中学生模型和教师模型之间的模型输出差异。在图 (d) 中,红色区域是学生模型认为比教师模型更可能是建筑物的区域,蓝色区域更可能是背景。
我们最初面临的一个问题是,我们的模型倾向于创建“斑点”检测,没有清晰的边缘,并且相邻建筑物倾向于合并在一起。为了解决这个问题,我们应用了原始U-Net 论文中的另一个想法,即使用距离加权来调整损失函数,以强调在边界附近做出正确预测的重要性。在训练期间,距离加权通过增加损失权重来更加强调边缘 - 特别是在存在几乎接触的实例时。对于建筑物检测,这鼓励模型正确识别建筑物之间的间隙,这一点很重要,这样许多紧密的结构就不会合并在一起。我们发现原始的 U-Net 距离加权公式很有用,但计算速度很慢。因此,我们开发了一种基于边缘高斯卷积的替代方法,它既更快又更有效。

距离加权方案强调附近的边缘:U-Net (左) 和边缘的高斯卷积 (右)。
我们的技术报告对每种方法都有更详细的介绍。
结果
我们评估了该模型在非洲大陆不同地区的性能,分为城市、农村和中等密度等不同类别。此外,为了准备潜在的人道主义应用,我们在流离失所者和难民定居点地区测试了该模型。不同地区的准确率和召回率确实存在差异,因此在整个非洲大陆实现一致的性能是一项持续的挑战。
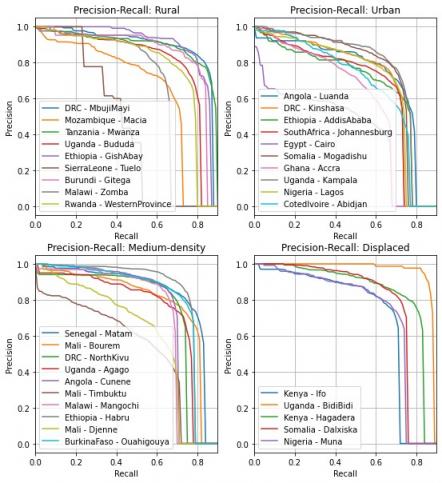
精确召回率曲线,以 0.5 交并比阈 值测量。
在目视检查低分区域的检测结果时,我们注意到各种原因。在农村地区,标签错误是个问题。例如,标签员很难发现空旷地区内的单栋建筑。在城市地区,该模型倾向于将大型建筑分成单独的实例。该模型在沙漠地形中的表现也不佳,因为建筑物在背景中很难区分。
我们进行了一项消融研究,以了解哪些方法对最终性能贡献最大,以平均精度(mAP) 来衡量。距离加权、混合和使用ImageNet预训练是监督学习基线性能的最大因素。未使用这些方法的消融模型的 mAP 差异分别为 -0.33、-0.12 和 -0.07。无监督自训练进一步显著提升了 +0.06 mAP。
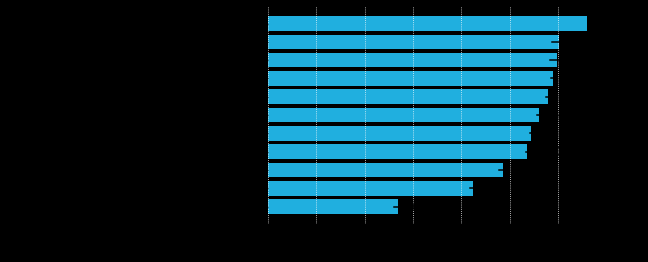
训练方法的消融研究。第一行显示结合自训练的最佳模型的 mAP 性能,第二行显示仅使用监督学习的最佳模型(基线)。通过依次禁用基线中的每个训练优化,我们观察了对 mAP 测试性能的影响。距离加权的影响最为显著。
生成开放建筑数据集
为了创建最终的数据集,我们将最好的建筑物检测模型应用于整个非洲大陆的卫星图像(86 亿个图像块,覆盖 1940 万平方公里,占非洲大陆的 64%),结果检测到了 5.16 亿个不同的结构。
每栋建筑的轮廓都被简化为多边形,并与一个Plus Code相关联,这是一个由数字和字母组成的地理标识符,类似于街道地址,可用于识别没有正式地址系统的地区的建筑。我们还提供了置信度分数和建议阈值的指导,以实现特定的精度水平。
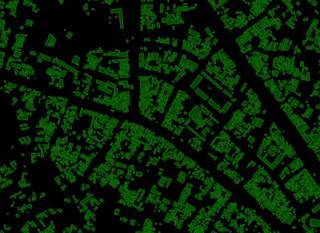
结构的尺寸各不相同,如下所示,趋向于较小的占地面积。例如,纳入小型结构对于支持对非正规住区或难民设施的分析非常重要。
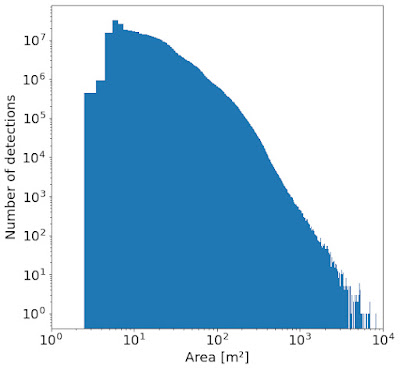
建筑物占地面积的分布。
这些数据是免费提供的,我们期待了解其使用情况。未来,我们可能会根据使用情况和反馈添加新功能和新区域。
致谢
这项工作是我们AI for Social Good工作的一部分,由加纳 Google Research 领导。感谢这项工作的合著者:Wojciech Sirko、Sergii Kashubin、Marvin Ritter、Abigail Annkah、Yasser Salah Eddine Bouchareb、Yann Dauphin、Daniel Keysers、Maxim Neumann 和 Moustapha Cisse。我们感谢 Abdoulaye Diack、Sean Askay、Ruth Alcantara 和 Francisco Moneo 的协调帮助。Rob Litzke、Brian Shucker、Yan Mayster 和 Michelina Pallone 在地理基础设施方面提供了宝贵的帮助。
评论