数据是机器学习 (ML) 研究和开发的基础,有助于构建机器学习算法的学习内容以及模型的评估和基准测试方式。然而,数据收集和标记可能会因无意识偏见、数据访问限制和隐私问题等挑战而变得复杂。因此,机器学习数据集可能会反映种族、性别、年龄等维度上的不公平社会偏见。
检查数据集的方法可以揭示不同社会群体在其中如何表现的信息,这是确保机器学习模型和数据集的开发符合我们的人工智能原则的关键组成部分。这些方法可以指导负责任地使用机器学习数据集,并指出可能减轻不公平结果的方法。例如,先前的研究表明,一些物体识别数据集偏向于来自北美和西欧的图像,这促使谷歌的众包努力平衡世界其他地区的图像表现。
今天,我们将使用COCO Captions数据集作为案例研究,演示最近在 Google I/O 上推出的 数据集探索工具Know Your Data (KYD) 的部分功能。使用此工具,我们发现 COCO Captions 中存在一系列性别和年龄偏见,这些偏见可以追溯到数据集收集和注释实践。KYD 是一种数据集分析工具,是对 Google 和更广泛的研究社区正在开发的日益壮大的负责任的 AI 工具套件的补充。目前,KYD 仅支持分析一小部分图像数据集,但我们正在努力使该工具能够适用于这一组以外的数据集。
介绍“了解你的数据”
Know Your Data 可帮助 ML 研究、产品和合规团队了解数据集,以提高数据质量,从而帮助缓解公平性和偏见问题。KYD 提供一系列功能,允许用户探索和检查机器学习数据集 - 用户可以根据给定数据集中已有的注释过滤、分组和研究相关性。KYD 还提供了来自 Google Cloud Vision API的自动计算标签,为用户提供了一种基于数据集中原本不存在的信号探索数据的简单方法。
KYD 案例研究
作为案例研究,我们使用COCO Captions 数据 集探索了其中的一些功能,该数据集包含 30 多万幅图像中的每幅图像的五个人工生成的字幕。鉴于自由格式文本提供的丰富注释,我们将分析重点放在数据集中已经存在的信号上。
探索性别偏见
先前的研究表明,计算机视觉数据集中存在不良的性别偏见,包括女性色情图片和与有害性别刻板印象相符的图像标签相关性。我们使用 KYD 通过检查图像标题中的性别相关性来探索 COCO Captions 中的性别偏见。我们发现,在数据集中不同图像对不同活动的描述中存在性别偏见,以及注释者对不同性别的人的描述方式存在偏见。
我们分析的第一部分旨在揭示数据集中描述的不同活动的性别偏见。我们研究了带有描述不同活动的文字的图像,并分析了它们与性别字幕词(如“男人”或“女人”)的关系。基于最近利用PMI指标来衡量模型学习到的关联的研究,KYD关系选项卡可以轻松检查数据集中不同信号之间的关联。此选项卡可视化了数据集中两个信号同时出现的程度(比偶然预期的更多或更少)。每个单元格表示两个特定信号值之间的正(蓝色)或负(橙色)相关性以及该相关性的强度。
KYD 还允许用户根据子字符串匹配来过滤关系表的行。使用此功能,我们最初探测了包含“-ing”的标题词,这是一种按动词过滤的简单方法。我们立即看到了强烈的性别相关性:
使用 KYD分析任何单词与性别词之间的关系。每个单元格显示两个单词在同一标题中同时出现的频率是否高于(向上箭头)或低于(向下箭头),这完全取决于偶然性。
进一步研究这些相关性后,我们发现,一些与女性有关的刻板活动,如“购物”和“烹饪”,与带有“女性”或“女人”字幕的图像同时出现的频率要高于带有“男性”或“男人”字幕的图像。相比之下,描述许多体力密集型活动的字幕,如“滑板”、“冲浪”和“滑雪板”,与带有“男人”或“男人”字幕的图像同时出现的频率更高。
虽然个别图片说明不得使用刻板印象或贬义语言(例如以下示例),但如果某些性别群体在整个数据集中某项特定活动中的代表性过高(或不足),则从该数据集开发的模型可能会学习刻板印象关联。KYD 可轻松显示、量化和制定计划以减轻这种风险。

图片配文:“两个女人在米色和白色厨房里做饭。
除了研究不同活动所描绘的社会群体的偏见外,我们还探讨了注释者在描述他们认为是男性或女性的人的外表时所存在的偏见。受到研究其他形式的视觉媒体中嵌入的“男性凝视”的媒体学者的启发,我们研究了在 COCO 中被视为女性的个体被描述为欲望对象的形容词的频率。KYD 让我们能够轻松地检查与二元性别相关的单词(例如“女性/女孩/女人”与“男性/男人/男孩”)与评估外表吸引力相关的单词之间的共现。重要的是,这些标题是由人类注释者编写的,他们对图像中人物的性别进行主观评估,并选择吸引力的描述词。我们发现, “有吸引力”、“美丽”、“漂亮”和“性感”等词在描述被视为女性的人时比在描述被视为男性的人时使用得更多,这证实了先前研究对视觉媒体中性别看法的论述。
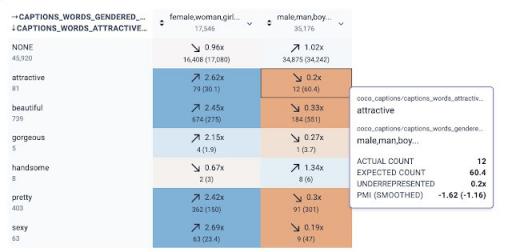
KYD 的截图显示了描述吸引力的单词和性别单词之间的关系。例如,“吸引力”和“男性/男人/男孩”同时出现 12 次,但我们预计偶然出现次数约为 60 次(比率为 0.2 倍)。另一方面,“吸引力”和“女性/女人/女孩”同时出现的次数是偶然出现的 2.62 倍。
KYD 还允许我们通过单击相关关系来手动检查每个关系的图像。例如,我们可以看到标题包含女性术语(例如“女人”)和单词“美丽”的图像。
探索年龄偏见
研究表明,相对于总人口而言, 65 岁以上的成年人在数据集中的代表性不足——改善年龄代表性的第一步是允许开发人员在数据集中评估年龄代表性。通过查看描述不同活动的字幕词并分析它们与描述年龄的字幕词的关系,KYD 帮助我们评估了描述老年人的字幕示例范围。拥有各种环境和活动中的成年人的字幕示例对于各种任务(例如图像字幕或行人检测)都很重要。
KYD 明确指出的第一个趋势是,注释者在详细描述不同活动的标题中很少将人们描述为老年人。关系选项卡还显示了一种趋势,即“elderly”、“old”和“older”往往不会出现在描述各种身体活动的动词中,而这些活动对于系统来说可能很重要,需要检测。值得注意的是,相对于“young”,“old”更常用于描述人以外的事物,例如物品或衣服,因此这些关系也捕捉到了一些不描述人的用法。
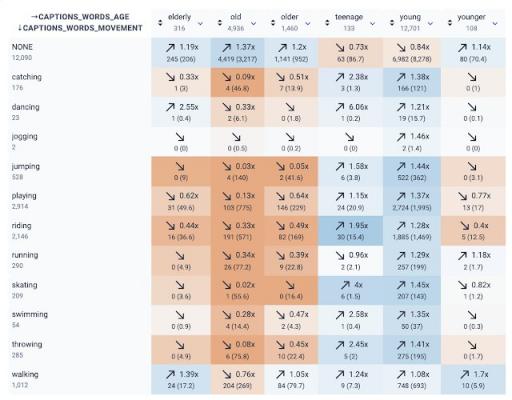
KYD 截图中与年龄和运动相关的词语之间的关系。
我们在此检查的包含老年人参考资料的标题代表性不足,可能是因为描绘老年人的图像相对缺乏,以及注释者在描述图像中的人物时倾向于省略与老年人相关的术语。虽然手动检查“老”和“跑步”的交集显示出负相关关系,但我们注意到它没有显示老年人和许多火车头。KYD可以轻松地定量和定性检查关系,以确定数据集的优势和需要改进的领域。
结论
了解 ML 数据集的内容是制定适当策略以减轻不公平数据集偏见的下游影响的关键第一步。上述分析指出了几种潜在的缓解措施。例如,某些活动与社会群体之间的相关性可能导致训练有素的模型重现社会刻板印象,而这种相关性可以通过“数据集平衡”来缓解——增加代表性不足的群体/活动组合的代表性。然而,仅仅关注数据集平衡的缓解措施是不够的,正如我们对注释者如何描述不同性别的分析所表明的那样。我们发现注释者对图像中描绘的人物的主观判断反映在最终数据集中,这表明需要更深入地研究图像注释方法。对于正在开发图像字幕数据集的数据从业者来说,一种解决方案是考虑整合已开发的用于编写对种族、性别和其他身份类别敏感的图像描述的指南。
上述案例研究仅重点介绍了KYD 的部分功能。例如,Cloud Vision API 信号也集成到 KYD 中,可用于推断注释者未直接标记的信号。我们鼓励更广泛的 ML 社区进行自己的 KYD 案例研究并分享他们的发现。
KYD 是对整个 ML 社区正在开发的 其他数据 集分析工具的补充,包括 Google 不断发展的Responsible AI 工具包。我们期待 ML 从业者使用 KYD 来更好地理解他们的数据集并减轻潜在的偏见和公平性问题。
致谢
本文的分析和撰写由 Emily Denton、Mark Díaz 和 Alex Hanna 共同完成。我们感谢 Marie Pellat、Ludovic Peran、Daniel Smilkov、Nikhil Thorat 和 Tsung-Yi 对本文的贡献和评论。我们还要感谢开发 KYD 中使用的信号和指标的研究人员和团队,特别是帮助我们实施 nPMI 的团队。
评论