
机器学习模型要想生成有意义的文本,就必须掌握大量有关世界的知识,并具备抽象能力。虽然经过此类训练的语言模型在规模扩大后能够自动获取这些知识,但如何最好地解锁这些知识并将其应用于特定的现实世界任务尚不清楚。
一种成熟的实现方法称为微调,即在标记数据集上训练预训练模型(例如BERT和T5),使其适应下游任务。然而,微调需要大量的训练样本,以及每个下游任务的存储模型权重,这并不总是可行的,尤其是对于大型模型而言。
在“经过微调的语言模型是零样本学习者”一文中,我们探索了一种简单的技术,称为 指令微调,或简称指令调整。这涉及对模型进行微调,不是为了解决特定任务,而是为了使其更适合解决一般的 NLP 任务。我们使用指令调整来训练模型,我们称之为微调语言网络 (FLAN)。因为与预训练模型所涉及的大量计算相比,FLAN 的指令调整阶段仅需要少量更新,所以它是预训练主菜的隐喻甜点。这使 FLAN 能够执行各种看不见的任务。

FLAN 工作原理说明:该模型针对不同的指令集进行微调,并推广到未见过的指令。随着更多类型的任务添加到微调数据模型中,性能得到提高。
背景
最近,一种使用语言模型解决任务的流行技术被称为零样本或少样本提示。该技术根据语言模型在训练期间可能见过的文本制定任务,然后语言模型通过完成文本来生成答案。例如,为了对电影评论的情绪进行分类,语言模型可能会收到以下句子:“‘自《风月俏佳人》以来最好的浪漫喜剧电影评论是 _ ’”,并被要求用“积极”或“消极”一词完成句子。
尽管这种技术在某些任务上表现出色,但它需要精心设计提示,将任务设计成看起来像模型在训练期间见过的数据——这种方法在某些任务上表现良好,但并非所有任务都如此,而且对于从业者来说,与模型交互的方式也可能不直观。例如,GPT-3(当今使用的最大语言模型之一)的创建者发现,这种提示技术在自然语言推理 (NLI) 任务上并没有带来良好的表现
指令调优
相反,FLAN 会根据大量不同的指令对模型进行微调,这些指令使用简单直观的任务描述,例如“将此电影评论归类为正面或负面”,或“将此句子翻译成丹麦语”。
从头开始创建指令数据集来微调模型需要大量资源。因此,我们改用模板将现有数据集转换为指令格式。

自然语言推理数据集的示例模板。
我们表明,通过对这些指令进行模型训练,它不仅可以很好地解决在训练期间看到的各种指令,而且可以很好地遵循一般的指令。
评估模型
为了以有意义的方式将 FLAN 与其他技术进行比较,我们使用了已建立的基准数据集来比较我们的模型与现有模型的性能。此外,我们在训练期间没有看到该数据集中的任何示例的情况下评估了 FLAN 的表现。
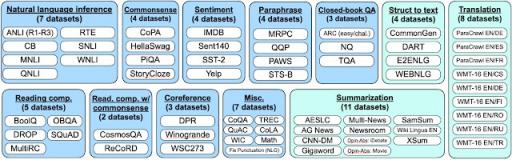
但是,如果我们在与评估数据集过于相似的数据集上进行训练,则性能结果仍可能会出现偏差。例如,在一个问答数据集上进行训练可能会帮助模型在另一个问答数据集上表现更好。因此,我们将所有数据集按任务类型分组,并且不仅保留数据集的训练数据,还保留数据集所属的 整个任务集群。
我们将数据集分组到下面的集群中。
结果
我们在 25 项任务上评估了 FLAN,发现除了 4 项任务外,其他所有任务上 FLAN 的表现都比零样本提示要好。我们发现,在 25 项任务中的 20 项上,我们的结果优于零样本 GPT-3,在某些任务上甚至优于少样本 GPT-3。
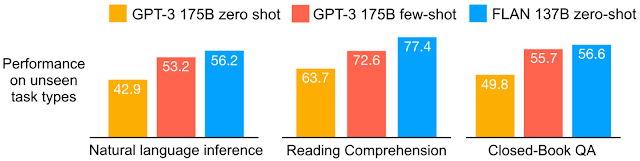
对于各种模型,我们展示了任务集群中所有数据集的平均准确率。自然语言推理数据集:ANLI R1–R3、CB和RTE。阅读理解数据集:BoolQ、MultiRC、OpenbookQA。闭卷问答数据集:ARC、NQ、TriviaQA。
我们还发现,模型规模对于模型从指令调整中获益的能力非常重要。在较小的规模下,FLAN 技术实际上会降低性能,而只有在较大的规模下,模型才能够从训练数据中的指令推广到看不见的任务。这可能是因为太小的模型没有足够的参数来执行大量任务。
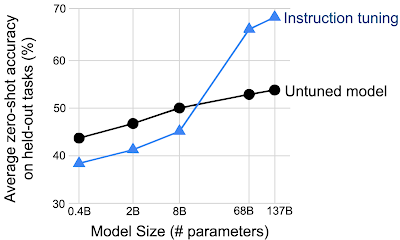
指令调整只能提高特定规模模型在看不见的任务上的性能。
结论
FLAN 模型并不是第一个使用一组指令进行训练的模型,但据我们所知,我们是第一个大规模应用该技术并证明它可以提高模型泛化能力的模型。我们希望我们提出的方法将有助于激发更多研究能够执行前所未见的任务并从极少量数据中学习的模型。
我们还发布了执行转换的代码,以便其他研究人员可以重现我们的研究结果并在此基础上进行构建。
致谢
我们感谢 Google Research 的合作者 Vincent Y. Zhao、Kelvin Guu、Adams Wei Yu、Brian Lester、Nan Du、Andrew M. Dai 和 Quoc V. Le。
评论