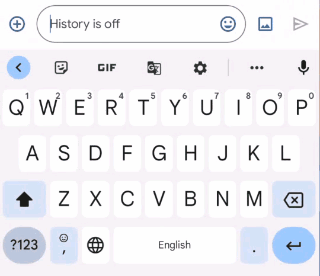
尽管智能手机取得了巨大成功并被广泛采用,但用它们撰写较长的文本仍然相当麻烦。在写作过程中,语法错误经常会潜入文本中(在正式场合尤其不受欢迎),而且在控制功能有限的小屏幕上纠正这些错误可能非常耗时。
为了解决其中的一些挑战,我们推出了一项语法纠正功能,该功能直接内置于Pixel 6上的Gboard中,该功能完全在设备上运行以保护隐私,在用户输入时检测并建议纠正语法错误。构建此类功能需要解决几个关键障碍:内存大小限制、延迟要求和处理部分句子。目前,该功能能够纠正英语句子(我们计划在不久的将来扩展到更多语言),并且几乎可以在任何带有 Gboard 1 的应用程序上使用。
Gboard 会在用户输入时建议如何纠正不合语法的句子。
模型架构
我们训练了一个序列到序列神经网络,以输入一个句子(或句子前缀)并输出语法正确的版本——如果原文已经语法正确,则模型的输出与其输入相同,表明不需要进行任何更正。该模型使用一种混合架构,将Transformer 编码器与LSTM 解码器相结合,这种组合在质量和延迟之间实现了良好的平衡。
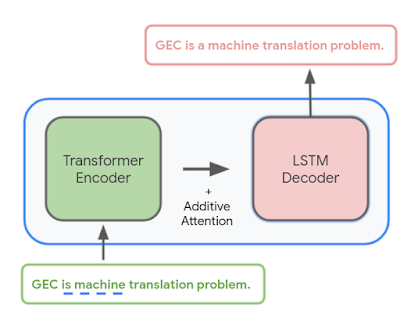
语法错误纠正(GEC)模型架构概述。
移动设备受限于有限的内存和计算能力,这使得构建高质量的语法检查系统变得更加困难。我们使用了一些技术来构建一个小型、高效且功能强大的模型。
共享嵌入: 由于模型的输入和输出在结构上相似(例如,都是同一种语言的文本),我们在 Transformer 编码器和 LSTM 解码器之间共享一些模型权重,这大大减少了模型文件大小,而不会过度影响准确性。
分解嵌入:该模型将一个句子拆分为一系列预定义标记。为了获得良好的质量,我们发现使用大量预定义标记词汇表非常重要,但这会大大增加模型大小。分解嵌入将隐藏层的大小与词汇嵌入的大小分开。这使我们能够拥有一个具有大量词汇表的模型,而无需显著增加总权重的数量。
量化:为了进一步减小模型大小,我们执行训练后量化,这使我们能够仅使用 8 位来存储每个 32 位浮点权重。虽然这意味着每个权重都以较低的保真度存储,但我们发现模型的质量并没有受到实质性影响。
通过采用这些技术,生成的模型仅占用 20MB 的存储空间,并在 Google Pixel 6 CPU 上在 22ms 内对 60 个输入字符进行推理。
训练模型
为了训练模型,我们需要<原始,校正后>文本对形式的训练数据。
生成小型设备模型的一种可能方法是使用与大型云端语法模型相同的训练数据。虽然这些数据可以生成质量相当高的设备模型,但我们发现,使用一种称为硬蒸馏的技术来生成与设备域更匹配的训练数据可以产生质量更好的结果。
硬蒸馏的工作原理如下:我们首先从公共网络收集了数亿个英语句子。然后,我们使用大型云端语法模型为这些句子生成语法更正。然后,这个 <原始,更正> 句子对的训练数据集用于训练一个较小的设备上模型,该模型可以更正完整的句子。我们发现,使用此训练数据集构建的设备上模型产生的建议质量明显高于基于用于训练云端模型的原始数据构建的类似大小的设备上模型。
然而,在使用这些数据训练模型之前,还有另一个问题需要解决。为了让模型能够在用户输入时纠正语法(移动设备的一项重要功能),它需要能够处理句子前缀。虽然这可以在用户只输入部分句子时启用语法纠正,但此功能在消息应用中特别有用,因为用户经常会省略句子中的最后一个句号,并在输入完成后立即按下发送按钮。如果语法纠正只在完整的句子上触发,它可能会错过许多错误。
这就提出了一个问题:如何判断给定的句子前缀是否符合语法。我们使用启发式方法来解决这个问题——如果给定的句子前缀可以完成形成一个语法正确的句子,那么我们就认为它是语法正确的。如果不能,就认为它是不正确的。
用户目前输入的内容 建议语法纠正
她投入了很多
她投入了很多
她付出了很多努力
她昨天付出了很多努力 将“puts”替换为“put in”。
不完整句子的 GEC。有效句子前缀没有更正。
我们创建了第二个数据集,该数据集适用于训练大型云模型,但这次重点关注句子前缀。我们使用上述启发式方法生成数据,方法是从基于云的模型的训练数据集中取出 <原始,更正> 句子对,并从中随机抽取对齐的前缀。
例如,给定 <原文,修改后> 的句子对:
原句:她昨天下午付出了很多努力。
改正句:她昨天下午付出了很多努力。
我们可能会对以下前缀对进行采样:
原始前缀:她投入
更正前缀:她投入
原始前缀:她昨天付出了很多努力
更正前缀:她昨天付出了很多努力
然后,我们使用神经语言模型(与SmartCompose 使用的模型类似)将每个原始前缀自动补全为完整的句子。如果全句语法模型在整句中未发现任何错误,则意味着至少有一种可能的方法来补全这个原始前缀而不会犯任何语法错误,因此我们认为原始前缀是正确的,并输出 <原始前缀,原始前缀> 作为训练示例。否则,我们输出 <原始前缀,更正后的前缀>。我们使用这些训练数据来训练一个可以更正句子前缀的大型云端模型,然后使用该模型进行硬提炼,生成与设备域更匹配的 新<原始,更正后的>句子前缀对。
最后,我们将这些新的句子前缀对与完整句子对相结合,构建了设备端模型的最终训练数据。基于这些组合数据进行训练的设备端模型随后能够纠正完整句子和句子前缀。
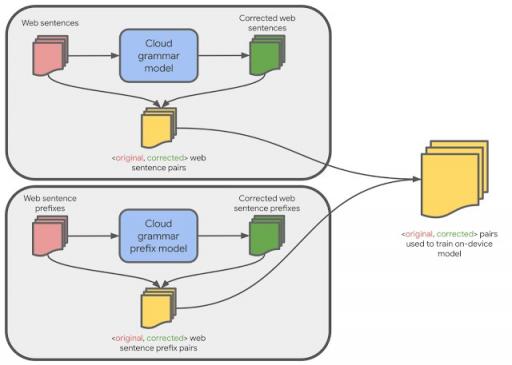
设备上模型的训练数据由基于云的模型生成。
设备上的语法纠正
无论句子是否完整,只要用户输入超过三个单词,Gboard 就会向设备上的语法模型发送请求。为了提供优质的用户体验,我们会在用户与语法错误互动时标注语法错误并提供替换建议。但是,该模型只输出更正后的句子,因此需要将其转换为替换建议。为此,我们通过最小化编辑距离(即,将原始句子转换为更正后的句子所需的编辑次数)来对齐原始句子和更正后的句子。
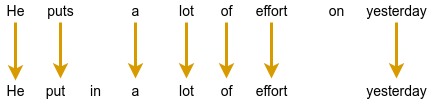
通过将纠正后的句子与原始句子对齐来提取编辑。
最后,我们将插入编辑和删除编辑转换为替换编辑。在上面的例子中,我们将建议插入“in”转换为建议将“puts”替换为“put in”的编辑。同样,我们建议将“effort on”替换为“effort”。
结论
我们设计了一个紧凑的模型架构,并在训练过程中通过硬蒸馏利用基于云的语法系统,构建了一个小型的高质量语法校正模型。这个紧凑的模型使用户能够完全在自己的设备上校正文本,而无需将他们的击键发送到远程服务器。
致谢
我们非常感谢其他团队成员做出的关键贡献,包括 Abhanshu Sharma、Akshay Kannan、Bharath Mankalale、Chenxi Ni、Felix Stahlberg、Florian Hartmann、Jacek Jurewicz、Jayakumar Hoskere、Jenny Chin、Kohsuke Yatoh、Lukas Zilka、Martin Sundermeyer、Matt Sharifi、Max Gubin、Nick Pezzotti、Nithi Gupta、Olivia Graham、Qi Wang、Sam Jaffee、Sebastian Millius、Shankar Kumar、Sina Hassani、Vishal Kumawat 以及 Yuanbo Zhang、Yunpeng Li 和 Yuxin Dai。我们还要感谢 Xu Liu 和 David Petrou 的支持。
评论