
今年秋天,Pixel 6 手机搭载了Google Tensor,这是 Google 的首款移动片上系统 (SoC),它将各种处理组件(如中央/图形/张量处理单元、图像处理器等)集成到单个芯片上,专为向 Pixel 用户提供最先进的机器学习 (ML) 创新而定制。事实上,Google Tensor 的每个方面都经过设计和优化,以运行 Google 的 ML 模型,符合我们的AI 原则。首先是 Google Tensor 中集成的定制 TPU,它使我们能够实现对 Pixel 手机的愿景。
今天,我们分享了通过为Google Tensor 的 TPU 设计 ML 模型而实现的设备端机器学习改进。我们使用神经架构搜索(NAS) 来自动化设计 ML 模型的过程,从而激励搜索算法发现在满足延迟和功率要求的同时实现更高质量的模型。这种自动化还使我们能够扩展各种设备端任务的模型开发。我们通过TensorFlow 模型园和TensorFlow Hub公开提供这些模型,以便研究人员和开发人员可以在 Pixel 6 上引导进一步的用例开发。此外,我们还应用了相同的技术来构建一个高能效的人脸检测模型,这是许多 Pixel 6 相机功能的基础。

NAS 查找 TPU 优化模型的图示。每列代表神经网络中的一个阶段,点表示不同的选项,每种颜色代表不同类型的构建块。从输入(例如图像)到输出(例如每个像素的标签预测)通过矩阵的路径代表候选神经网络。在搜索的每次迭代中,使用每个阶段选择的块形成一个神经网络,搜索算法旨在找到共同最小化 TPU 延迟和/或能量并最大化准确性的神经网络。
视觉模型的搜索空间设计
NAS 的一个关键组成部分是设计用于采样候选网络的搜索空间。我们定制了搜索空间,以包括在 Google Tensor TPU 上高效运行的神经网络构建块。
神经网络中用于各种设备上视觉任务的广泛使用的构建块是倒置瓶颈(IBN)。IBN 块有几种变体,每种都有不同的权衡,并且使用常规卷积和深度卷积层构建。虽然具有深度卷积的 IBN 因其低计算复杂度而传统上用于移动视觉模型,但融合 IBN(其中深度卷积被常规卷积取代)已被证明可以提高TPU 上 图像分类和对象检测模型的准确性和延迟。
然而,融合 IBN 对于视觉模型后期阶段常见的神经网络层形状具有过高的计算和内存要求,限制了它们在整个模型中的使用,使深度 IBN 成为唯一的替代方案。为了克服这一限制,我们引入了使用组卷积的 IBN 来增强模型设计的灵活性。常规卷积会混合输入中所有特征的信息,而组卷积会将特征分成更小的组并对该组内的特征执行常规卷积,从而降低总体计算成本。这种 IBN 被称为基于组卷积的 IBN (GC-IBN),其缺点是可能会对模型质量产生不利影响。
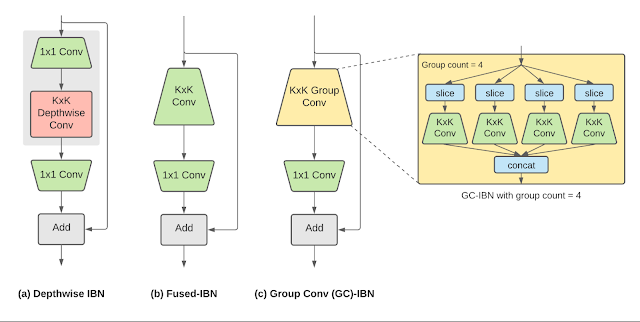
倒置瓶颈 (IBN) 变体:(a) 深度-IBN,过滤器大小为K x K的深度卷积层夹在两个过滤器大小为 1x1 的卷积层之间;(b) 融合-IBN,卷积和深度融合为过滤器大小为K x K 的卷积层;(c) 基于组卷积的 GC-IBN,用组卷积取代融合-IBN 中的K x K常规卷积。组数(组计数)是 NAS 期间的可调参数。
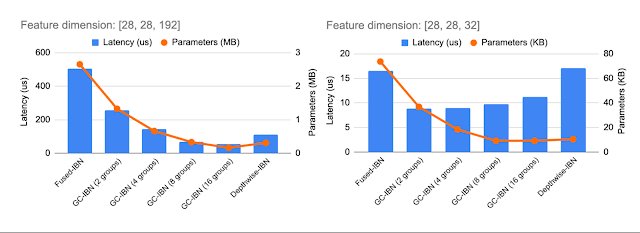
GC-IBN 作为选项的加入提供了超越其他 IBN 的额外灵活性。不同 IBN 变体的计算成本和延迟取决于正在处理的特征维度(上图显示了两个示例特征维度)。我们使用 NAS 来确定 IBN 变体的最佳选择。
更快、更准确的图像分类
在深度神经网络的哪个阶段使用哪种 IBN 变体取决于目标硬件的延迟以及生成的神经网络在给定任务上的性能。我们构建了一个包含所有这些不同 IBN 变体的搜索空间,并使用 NAS 来发现用于图像分类任务的神经网络,这些神经网络可以在 TPU 上以所需的延迟优化分类准确率。与在 TPU 上运行时的现有设备上模型相比,生成的 MobileNetEdgeTPUV2 模型系列在给定延迟(或所需准确率的延迟)下提高了准确率。MobileNetEdgeTPUV2 的表现也优于其前身MobileNetEdgeTPU,后者是为上一代 TPU 设计的图像分类模型。
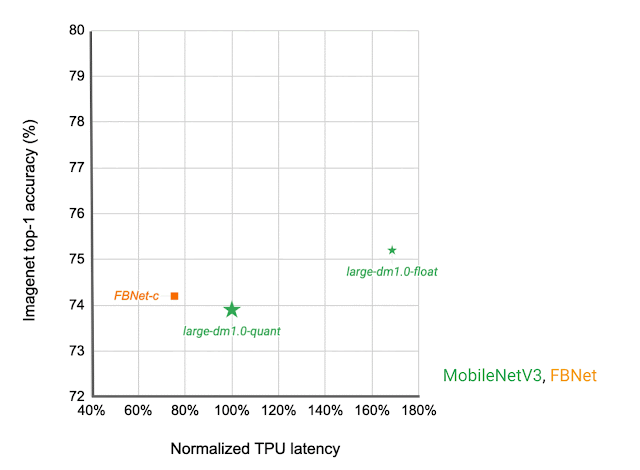
网络架构系列可视化为不同延迟目标下的连通点。与其他移动模型(例如FBNet、MobileNetV3和EfficientNets)相比,MobileNetEdgeTPUV2 模型在 Google Tensor 的 TPU 上运行时以更低的延迟实现了更高的ImageNet top-1 准确率。
MobileNetEdgeTPUV2 模型使用模块构建,这些模块还可以改善 Google Tensor SoC 中其他计算元素(例如CPU)的延迟/准确度权衡。与 TPU 等加速器不同,CPU 在神经网络中的乘法和累加运算数量与延迟之间表现出更强的相关性。GC-IBN 的乘法和累加运算往往比融合 IBN 少,这使得 MobileNetEdgeTPUV2 即使在 Pixel 6 CPU 上也能胜过其他模型。
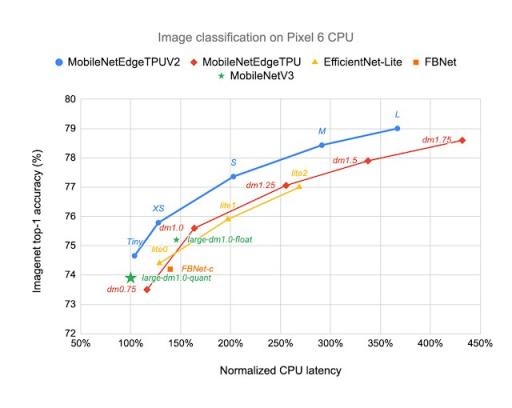
MobileNetEdgeTPUV2 模型在 Pixel 6 CPU 上以更低的延迟实现了 ImageNet top-1 准确率,并且优于其他针对 CPU 优化的模型架构,例如 MobileNetV3。
改进设备上的语义分割
许多视觉模型由两个组件组成,基本特征提取器用于理解图像的一般特征,头部用于理解特定领域的特征,例如语义分割(为图像中的每个像素分配标签(例如天空、汽车等)的任务)和对象检测(检测图像中对象实例(例如猫、门、汽车等)的任务)。图像分类模型通常用作这些视觉任务的特征提取器。如下所示,MobileNetEdgeTPUV2 分类模型与DeepLabv3+分割头部相结合,提高了设备上分割的质量。
为了进一步提高分割模型的质量,我们使用双向特征金字塔网络 ( BiFPN ) 作为分割头,对特征提取器提取的不同特征进行加权融合。使用 NAS,我们可以找到特征提取器和 BiFPN 头中块的最佳配置。由此产生的模型名为 Autoseg-EdgeTPU,可产生更高质量的分割结果,同时运行速度更快。
分割模型的最后几层对整体延迟有重大影响,这主要是由于生成高分辨率分割图所涉及的操作。为了优化 TPU 上的延迟,我们引入了一种生成高分辨率分割图的近似方法,该方法降低了内存需求,并将速度提高了近 1.5 倍,同时不会显著影响分割质量。
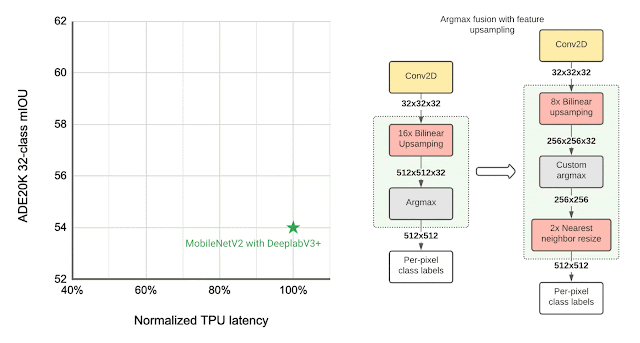
左图:比较不同分割模型在ADE20K语义分割数据集(前 31 个类别)上的性能,以平均交并比(mIOU) 衡量。右图:近似特征上采样(例如,将分辨率从 32x32 提高到 512x512)。用于计算每个像素标签的Argmax操作与双线性上采样融合。在较小分辨率特征上执行 Argmax 可降低内存需求并改善 TPU 上的延迟,而不会对质量产生重大影响。
更高质量、低能耗的物体检测
经典的对象检测架构将约 70% 的计算预算分配给特征提取器,仅约 30% 分配给检测头。对于此任务,我们将 GC-IBN 块合并到我们称为“意大利面搜索空间” 1 的搜索空间中,这提供了将更多计算预算转移到检测头的灵活性。该搜索空间还使用最近 NAS 作品(例如MnasFPN)中看到的非平凡连接模式来合并网络的不同但相关的阶段以加强理解。
我们将 NAS 生成的模型与MobileDet-EdgeTPU进行了比较,后者是为上一代 TPU 定制的一类移动检测模型。MobileDets 已被证明可以在各种移动加速器上实现最先进的检测质量:DSP、GPU 和上一代 TPU。与 MobileDets 相比,新系列 SpaghettiNet-EdgeTPU 检测模型在COCO上以相同的延迟实现了 +2.2% 的mAP(绝对值),并且消耗的能量不到 MobileDet-EdgeTPU 所用能量的 70%,即可实现类似的准确度。
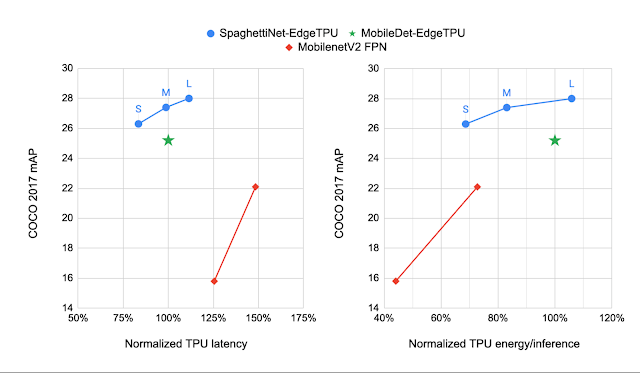
使用 mAP 指标(越高越好)比较不同物体检测模型在COCO数据集上的表现。与之前的移动模型(例如 MobileDets 和具有特征金字塔网络 (FPN) 的 MobileNetV2)相比,SpaghettiNet-EdgeTPU 以更低的延迟和能耗实现了更高的检测质量。
包容且节能的人脸检测
人脸检测是相机的一项基础技术,可实现一系列附加功能,例如修复焦点、曝光和白平衡,甚至使用新的“人脸模糊”功能消除面部模糊。此类功能必须以负责任的方式设计,Pixel 6 中的人脸检测功能在开发时始终牢记 我们的AI 原则。

左图:未经改进的原始照片。右图:动态环境中的清晰人脸。这是人脸模糊处理与以更高帧率运行的更精确人脸检测器相结合的结果。
由于移动摄像头可能非常耗电,因此人脸检测模型必须符合功耗预算。为了优化能效,我们使用 Spaghetti 搜索空间和算法来搜索在给定能量目标下最大限度提高准确度的架构。与高度优化的基线模型相比,SpaghettiNet 以约 70% 的能量实现了相同的准确度。由此产生的人脸检测模型 FaceSSD 更节能、更准确。这种改进的模型与我们的自动白平衡和自动曝光调节改进相结合,是Pixel 6 上Real Tone的一部分。这些改进有助于更好地反映所有肤色的美感。开发者可以通过Android Camera2 API在自己的应用中使用此模型。
面向移动设备的数据中心质量语言模型
在移动设备上部署低延迟、高质量的语言模型有利于语言理解、语音识别和机器翻译等机器学习任务。MobileBERT是BERT的衍生产品,是一种针对移动 CPU 进行调整的 自然语言处理(NLP) 模型。
然而,由于为了在移动 CPU 上高效运行这些模型而进行了各种架构优化,它们的质量不如大型 BERT 模型。由于 TPU 上的 MobileBERT 运行速度明显快于 CPU,因此它为进一步改进模型架构并缩小 MobileBERT 和 BERT 之间的质量差距提供了机会。我们扩展了 MobileBERT 架构并利用 NAS 来发现能够很好地映射到 TPU 的模型。这些新的 MobileBERT 变体(称为 MobileBERT-EdgeTPU)实现了高达 2 倍的硬件利用率,使我们能够在 TPU 上部署大型且更准确的模型,延迟与基线 MobileBERT 相当。
当部署在 Google Tensor 的 TPU 上时,MobileBERT-EdgeTPU 模型可产生与通常部署在数据中心的大型 BERT 模型相当的设备质量。
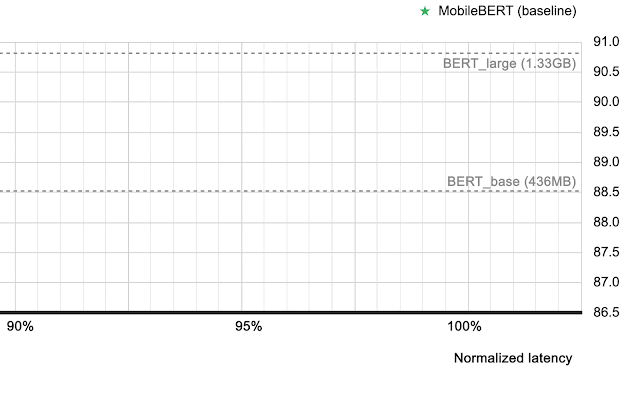
问答任务 ( SQuAD v 1.1 ) 上的表现。虽然 Pixel 6 中的 TPU 比 CPU 提供了约 10 倍的加速,但对 TPU 的进一步模型定制实现了与通常部署在数据中心的大型BERT模型相当的设备质量。
结论
在本文中,我们演示了如何为目标硬件设计 ML 模型来扩展 Pixel 6 的设备端 ML 功能,并为 Pixel 用户带来高质量的 ML 驱动体验。借助 NAS,我们将 ML 模型的设计扩展到各种设备端任务,并构建了在移动设备的延迟和功率限制内提供最先进质量的设备端模型。研究人员和 ML 开发者可以通过TensorFlow 模型园和TF Hub访问这些模型,并在自己的用例中试用它们。
致谢
这项工作得益于 Google 多个团队的通力合作。我们要感谢 Rachit Agrawal、Berkin Akin、Andrey Ayupov、Aseem Bathla、Gabriel Bender、Po-Hsein Chu、Yicheng Fan、Max Gubin、Jaeyoun Kim、Quoc Le、Dongdong Li、Jing Li、Yun Long、Hanxiao Lu、Ravi Narayanaswami、Benjamin Panning、Anton Spiridonov、Anakin Tung、Zhuo Wang、Dong Hyuk Woo、Hao Xu、Jiayu Ye、Hongkun Yu、Ping Zhou 和 Yanqi Zhuo 的贡献。最后,我们要感谢 Tom Small 为本博文创作插图。
评论