近年来,BERT和GPT-3等预训练语言模型在自然语言处理(NLP)中得到了广泛应用。通过对大量文本进行训练,语言模型获得了有关世界的广泛知识,在各种 NLP 基准上取得了出色的表现。然而,这些模型往往不透明,因为它们表现如此出色的原因可能不清楚,这限制了进一步基于假设的模型改进。因此,出现了一条新的科学研究方向:这些模型中包含哪些语言知识?
虽然人们可能想要研究多种语言知识,但英语中的主谓一致语法规则为分析提供了强有力的基础,该规则要求动词的语法数与主语的语法数一致。例如,句子“ The dogs run. ”是合乎语法的,因为“ dogs ”和“ run ”都是复数,但“ The dogs runs. ”是不合语法的,因为“ runs ”是单数动词。
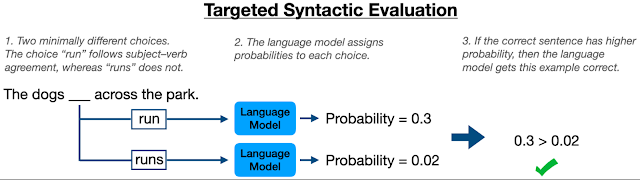
评估语言模型的语言知识的一个框架是目标句法评估(TSE),其中向模型展示最少不同的句子对,一个符合语法,一个不符合语法,模型必须确定哪一个符合语法。TSE 可用于测试英语主谓一致规则的知识,方法是让模型判断同一句子的两个版本:一个版本中某个动词以单数形式书写,另一个版本中动词以复数形式书写。
基于上述背景,在EMNLP 2021上发表的“频率对 Transformers 句法规则学习的影响”中,我们研究了 BERT 模型正确应用英语主谓一致规则的能力如何受到模型在预训练期间看到单词的次数的影响。为了测试特定条件,我们使用精心控制的数据集从头开始预训练了 BERT 模型。我们发现 BERT 在预训练数据中不一起出现的主谓对上取得了良好的表现,这表明它确实学会了应用主谓一致。然而,当错误形式比正确形式出现的频率高得多时,模型往往会预测错误形式,这表明 BERT 不将语法一致视为必须遵循的规则。这些结果有助于我们更好地理解预训练语言模型的优势和局限性。
先前的工作
先前的研究使用 TSE 来测量 BERT 模型中的英语主谓一致能力。在此设置中,BERT通过为给定动词的单数和复数形式(例如“runs”和“run”)分配概率来执行填空任务(例如“the dog _ across the park ” )。如果模型已正确学会应用主谓一致规则,那么它应该始终为使句子语法正确的动词形式分配更高的概率。
这项先前的研究使用自然句子(取自Wikipedia)和随机句子对 BERT 进行了评估,随机句子是人为构造的,在语法上有效,但在语义上毫无意义,例如诺姆·乔姆斯基的著名例子“无色绿色思想狂睡”。随机句子在测试句法能力时很有用,因为模型不能仅仅依赖表面的语料库统计数据:例如,虽然“dogs run”比“dogs runs”更常见,但“dogs publish”和“dogs publishes”都非常罕见,因此模型不太可能简单地记住其中一个比另一个更有可能的事实。
BERT 在 nonce 句子上的准确率超过 80%(远高于随机基线的 50%),这被视为该模型已学会应用主谓一致规则的证据。在我们的论文中,我们通过在特定数据条件下对 BERT 模型进行预训练,超越了之前的研究,使我们能够更深入地研究这些结果,以了解预训练数据中的某些模式如何影响性能。
看不见的主谓词对
我们首先观察了模型在预训练期间看到的主谓对的表现,以及主语和动词从未在同一句子中一起出现的例子:
BERT 在自然和随机评估句子中的错误率,根据训练期间是否在同一句子中看到特定的主语-动词 (SV) 对进行分层。BERT 在未见过的 SV 对上的表现远优于简单的启发式方法,例如挑选更频繁的动词或挑选更频繁的 SV 对。
对于自然和随机评估句子中未见过的主谓 (SV) 对,BERT 的错误率会略有增加,但它仍然比简单的启发式方法要好得多,例如挑选在预训练数据中出现频率更高的动词形式,或挑选与主语名词一起出现频率更高的动词形式。这告诉我们,BERT 不仅仅是在反映它在预训练期间看到的东西:做出决策不仅仅基于原始频率,而且可以推广到新的主谓对,这表明该模型已经学会了应用一些有关主谓一致性的基本规则。
动词频率
接下来,我们不再仅限于“见过”和“没见过”,而是研究了单词的频率如何影响 BERT 使用主谓一致规则正确使用该单词的能力。在这项研究中,我们选择了一组 60 个动词,然后创建了多个版本的预训练数据,每个版本都经过设计以包含特定频率的 60 个动词,确保单数和复数形式出现的次数相同。然后,我们从这些不同的数据集训练 BERT 模型,并在主谓一致任务中对它们进行评估:
BERT 遵循主谓一致规则的能力取决于训练集中动词的频率。
这些结果表明,尽管 BERT 能够模拟主谓一致规则,但它需要看到动词大约 100 次才能可靠地将其与规则一起使用。
动词形式之间的相对频率
最后,我们想了解动词单数和复数形式的相对频率如何影响 BERT 的预测。例如,如果动词的一种形式(例如“combat”)在预训练数据中出现的频率远高于另一种动词形式(例如“combats”),那么 BERT 可能更有可能将高概率分配给更常见的形式,即使它在语法上不正确。为了评估这一点,我们再次使用了相同的 60 个动词,但这次我们创建了预训练数据的操纵版本,其中动词形式之间的频率比从 1:1 到 100:1 不等。下图显示了 BERT 在这些不同程度的频率不平衡下的表现:
随着训练数据中动词形式之间的频率比变得越来越不平衡,BERT 在语法上使用这些动词的能力就会下降。
这些结果表明,在预训练期间,当两种动词形式出现的次数相同时,BERT 在预测正确的动词形式方面取得了良好的准确率,但随着频率不平衡的增加,结果会变得更糟。这意味着,尽管 BERT 已经学会了如何应用主谓一致,但它并不一定将其用作“规则”,而是倾向于预测高频词,而不管它们是否违反主谓一致约束。
结论
使用 TSE 评估 BERT 的性能可以揭示其在句法任务上的语言能力。此外,研究其句法能力与单词在训练数据集中出现频率的关系可以揭示 BERT 处理相互竞争的优先级的方式——它知道主语和动词应该一致,高频词的可能性更大,但不明白一致性是必须遵循的规则,频率只是一种偏好。我们希望这项工作能为语言模型如何反映其训练数据集的属性提供新的见解。
致谢
我很荣幸能够与 Tal Linzen 和 Ellie Pavlick 合作完成这个项目。
评论