2017 年,Google推出了联邦学习(FL),这种方法使移动设备能够协同训练机器学习 (ML) 模型,同时将原始训练数据保留在每个用户的设备上,从而将执行 ML 的能力与将数据存储在云中的需求分离开来。自推出以来,Google 一直积极参与 FL 研究,并部署 FL 来支持Gboard中的许多功能,包括下一个单词预测、表情符号建议和词汇外单词发现。联邦学习正在改进Assistant 中的“Hey Google”检测模型,在 Google Messages 中建议回复,预测文本选择等。
虽然 FL 允许机器学习无需收集原始数据,但差分隐私(DP) 提供了可量化的数据匿名化措施,当应用于机器学习时,可以解决模型记忆敏感用户数据的担忧。这也是研究的重中之重,并在2014 年产生了RAPPOR 、我们的开源 DP 库、Pipeline DP和TensorFlow Privacy等 DP 在分析中的首批生产用途之一。
经过多年、多团队的努力,涵盖基础研究和产品集成,今天我们很高兴地宣布,我们已经部署了一个使用联邦学习和严格差分隐私保证的生产型 ML 模型。对于这一概念验证部署,我们利用DP-FTRL 算法训练循环神经网络,为西班牙语 Gboard 用户提供下一个单词预测功能。据我们所知,这是第一个直接在正式公布的 DP 保证(技术上为 ρ=0.81零集中差分隐私,zCDP,下文将详细讨论)的用户数据上训练的生产型神经网络。此外,联邦方法提供了互补的数据最小化优势,DP 保证保护每台设备上的所有数据,而不仅仅是单个训练示例。
联邦学习中的数据最小化和匿名化
除了透明度和同意等基本原则外,数据最小化和匿名化的隐私原则对于涉及敏感数据的机器学习应用也非常重要。
联邦学习系统在结构上体现了数据最小化 的原则,联邦学习只针对特定的模型训练任务传输最小更新(重点收集),限制各个阶段的数据访问,尽早处理个体的数据(早期聚合),尽快丢弃收集和处理的数据(最小保留)。
对于使用用户数据进行训练的模型而言,另一个重要的原则是匿名化,这意味着最终模型不应记住特定个人数据所特有的信息,例如电话号码、地址、信用卡号。然而,FL 本身并不能直接解决这个问题。
DP 的数学概念允许人们正式量化这一匿名化原则。差分隐私训练算法在训练期间添加随机噪声,以在输出模型上产生概率分布,并确保在训练数据发生微小变化的情况下,该分布不会发生太大变化;ρ-zCDP 量化了分布可能的变化程度。当添加或删除单个训练示例以可证明的最小方式改变模型上的输出分布时, 我们称之为示例级DP。
2016 年的一大进步 是,证明了在更简单的集中训练环境中,深度学习与示例级差异隐私的实现也是可能的。DP-SGD 算法实现了这一目标,其关键在于利用训练示例采样的随机性来放大隐私保证(“通过采样放大”)。
但是,当用户可以向训练数据集贡献多个示例时,示例级 DP 不一定足够强大,以确保用户的数据不会被记住。相反,我们设计了用户级DP 算法,这要求即使我们添加/删除来自任何一个用户的所有训练示例(或来自我们应用程序中任何一个设备的所有示例),模型的输出分布也不会改变。幸运的是,由于 FL 将用户的所有训练数据汇总为单个模型更新,因此联合算法非常适合提供用户级 DP 保证。
然而,限制一个用户的贡献和添加噪音都会以牺牲模型准确性为代价,因此保持模型质量的同时提供强大的 DP 保证是一个关键的研究重点。
差异隐私联邦学习的艰难之路
2018 年,我们推出了DP-FedAvg 算法,该算法将 DP-SGD 方法扩展到具有用户级 DP 保证的联合设置,并于 2020 年首次将该算法部署到移动设备。这种方法确保训练机制不会对任何一个用户的数据过于敏感,而经验隐私审计技术则排除了某些形式的记忆。
然而,通过采样放大论点对于为 DP-FedAvg 提供强大的 DP 保证至关重要,但在现实世界的跨设备 FL 系统中,确保从大量人群中精确且均匀地随机抽样设备将会非常复杂且难以验证。一个挑战是,设备会根据许多外部因素(例如,要求设备处于空闲状态、使用不计费的 WiFi 和充电)来选择何时连接(或“签到”),并且可用设备的数量可能会有很大差异。
要实现正式的隐私保障,需要执行以下所有 操作的协议:
即使可用的设备组合随时间发生很大变化,训练仍能取得进展。
即使设备可用性发生意外或任意变化,也能保持隐私保证。
为了提高效率,允许客户端设备在本地决定是否登录服务器以参与训练,独立于其他设备。
通过随机签到进行隐私放大的初步研究突出了这些挑战,并引入了一个可行的协议,但部署该协议需要对我们的生产基础设施进行复杂的更改。此外,与 DP-SGD 的抽样放大分析一样,随机签到可能实现的隐私放大取决于可用的设备数量。例如,如果只有 1000 台设备可用于训练,并且每个训练步骤都需要至少 1000 台设备参与,那么这需要 1) 包括所有当前可用的设备并支付高额的隐私成本,因为选择中没有随机性,或者 2) 暂停协议,直到有更多设备可用时才取得进展。
使用 DP-FTRL 实现联邦学习的可证明差分隐私
为了应对这一挑战,DP-FTRL 算法基于两个关键观察结果:1)梯度下降算法的收敛性主要不取决于单个梯度的准确性,而是取决于梯度累积和的准确性;2)我们可以利用聚合服务器添加的负相关噪声,提供具有强 DP 保证的累积和的准确估计:本质上,将噪声添加到一个梯度中,并从后面的梯度中减去相同的噪声。DP-FTRL 使用树聚合算法高效地实现了这一点 [ 1 , 2 ]。
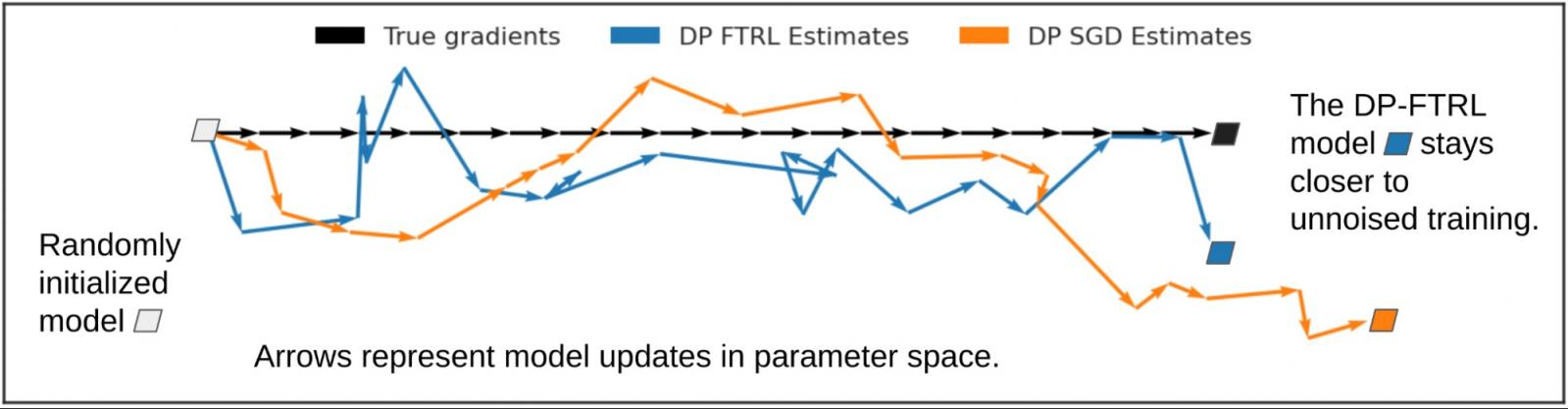
下图说明了估算累积总和而非单个梯度如何有所帮助。我们来看看 DP-FTRL 和 DP-SGD 引入的噪声如何影响模型训练,相比之下,真实梯度(没有添加噪声;黑色)在每次迭代中向右移动一个单位。基于累积总和的单个 DP-FTRL 梯度估计值(蓝色)的均方误差大于单独噪声的 DP-SGD 估计值(橙色),但由于 DP-FTRL 噪声呈负相关,因此其中一些噪声会逐步抵消,整体学习轨迹更接近真实的梯度下降步骤。
为了提供强有力的隐私保障,我们限制了用户贡献更新的次数。幸运的是,在生产 FL 基础设施中,无替换采样相对容易实现:每个设备都可以在本地记住它过去对哪些模型做出了贡献,并选择在以后的轮次中不连接到这些模型的服务器。
生产培训细节和正式的DP声明
对于上面介绍的生产级 DP-FTRL 部署,每台合格设备都会维护一个由用户键盘输入组成的本地训练缓存,并在参与时计算模型的更新,使其更有可能根据迄今为止输入的内容建议用户实际输入的下一个单词。我们对这些数据运行了 DP-FTRL,以训练具有约 130 万个参数的循环神经网络。训练在六天内进行了 2000 轮,每轮有 6500 台设备参与。为了实现 DP 保证,设备最多每 24 小时参与一次训练。模型质量比之前的 DP-FedAvg 训练模型有所提高,后者比非 DP 模型提供了经实证检验的隐私优势,但缺乏有意义的正式 DP 保证。
我们使用的训练机制在TensorFlow Federated和TensorFlow Privacy 中以开源形式提供,并且结合我们在生产部署中使用的参数,它提供了非常强大的隐私保证。我们的分析在用户级别给出了 ρ=0.81 zCDP(将每台设备上的所有数据视为不同的用户),其中较小的数字以数学精确的方式对应更好的隐私。作为比较,这比2020 年美国人口普查选择的 ρ=2.63 zCDP 保证更强。
下一步
虽然我们已经达到了使用提供有意义的小 zCDP 的机制部署生产 FL 模型的里程碑,但我们的研究之旅仍在继续。我们仍然远远不能说这种方法对于大多数 ML 模型或产品应用程序都是可行的(更不用说实用了),并且还存在其他私有 ML 方法。例如,成员资格推理测试和其他经验隐私审计技术可以提供防止用户数据泄露的补充保障。最重要的是,我们认为使用用户级 DP 训练模型,即使使用非常大的 zCDP,也是向前迈出的重要一步,因为它需要使用 DP 机制进行训练,该机制将模型的敏感度限制在任何一个用户的数据上。此外,随着更好的算法或更多数据的出现,它为以后具有改进的隐私保证的训练模型铺平了道路。我们很高兴继续努力最大化 ML 可以提供的价值,同时最大限度地降低那些贡献训练数据的人的潜在隐私成本。
致谢
作者要感谢 Alex Ingerman 和 Om Thakkar 对博客文章本身的重大影响,以及 Google 团队帮助开发这些想法并将其付诸实践:
核心研究团队:Galen Andrew、Borja Balle、Peter Kairouz、Daniel Ramage、宋爽、Thomas Steinke、Andreas Terzis、Om Thakkar、徐正
FL 基础设施团队:Katharine Daly、Stefan Dierauf、Hubert Eichner、Timon Van Overveldt、Chunxiang Zheng
Gboard 团队:Angana Ghosh、刘旭、张远波
演讲团队:Françoise Beaufays、陈明清、Rajiv Mathews、Vidush Mukund、Igor Pisarev、Swaroop Ramaswamy、Dan Zivkovic
评论