近年来,以多种语言和多种平台为全球用户创建和提供视频内容的数量大幅增加。创建高质量内容的过程可能包括多个阶段,从视频捕获和添加字幕到视频和音频编辑。在某些情况下,对话会在录音室重新录制(称为对话替换、后期同步或配音),以实现高质量并替换可能在嘈杂条件下录制的原始音频。然而,对话替换过程可能很困难且繁琐,因为新录制的音频需要与视频很好地同步,需要多次编辑才能匹配嘴部动作的准确时间。
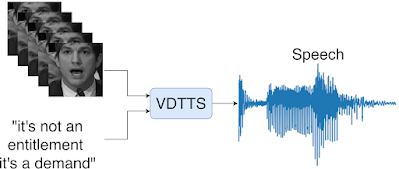
在“不仅仅是文字:自然界中视觉驱动的文本转语音韵律”中,我们提出了一个概念验证的视觉驱动的文本转语音模型,称为 VDTTS,该模型可自动执行对话替换过程。给定一段文本和说话者的原始视频帧,VDTTS 经过训练可生成相应的语音。与专注于嘴部区域的标准视觉语音识别模型不同,我们使用MediaPipe检测和裁剪整个面部,以避免可能排除与说话者讲话相关的信息。这为 VDTTS 模型提供了足够的信息来生成与视频匹配的语音,同时恢复韵律的各个方面,例如时间和情感。尽管没有经过明确训练来生成与输入视频同步的语音,但学习到的模型仍然可以这样做。
给定说话者的文本和视频帧,VDTTS 会生成与视频信号匹配韵律的语音。
VDTTS 模型
VDTTS 模型的核心与Tacotron相似,并包含四个主要组件:(1) 处理输入的文本和视频编码器;(2) 将编码器连接到解码器的多源注意力机制;(3) 包含说话人嵌入的声谱图解码器(类似于VoiceFilter),并生成梅尔声谱图(频域中的一种压缩表示形式);(4)从梅尔声谱图产生波形的 冻结的、预训练的神经声码器。
VDTTS 的整体架构。文本和视频编码器处理输入,然后多源注意力机制将这些输入连接到产生梅尔频谱图的解码器。然后,声码器从梅尔频谱图产生波形以生成语音作为输出。
我们使用LSVSR 中的视频和文本对来训练 VDTTS ,其中的文本与视频中某个人说的确切单词相对应。在整个测试过程中,我们已确定 VDTTS 无法生成任意文本,因此不太容易被滥用(例如生成虚假内容)。
质量
为了在这篇文章中展示 VDTTS 的独特优势,我们从VoxCeleb2测试数据集中选择了两个推理示例,并将 VDTTS 的性能与标准文本转语音 (TTS) 模型进行了比较。在这两个示例中,视频帧都提供了韵律和单词时间线索,这是 TTS 模型无法提供的视觉信息。
在第一个例子中,说话者以特定的速度说话,这可以看作是真实梅尔频谱图中的周期性间隙(如下所示)。VDTTS 保留了这一特性,并且生成的音频比标准 TTS 在没有视频的情况下生成的音频更接近真实情况。
同样,在第二个例子中,说话者在某些单词之间停顿了很长时间。这些停顿被 VDTTS 捕获,并反映在下面的视频中,而 TTS 并没有捕捉到说话者节奏的这个方面。
我们还绘制了基频(F0) 图表,以比较每个模型生成的音调与真实音调。在这两个示例中,VDTTS 的 F0 曲线比 TTS 曲线更符合真实音调,无论是语音和静音的对齐,还是音调随时间的变化。查看更多原始视频和 VDTTS 生成的视频。
我们从 VoxCeleb2 测试集中提供了两个示例 (a) 和 (b)。从上到下:输入人脸图像、真实 (GT) 梅尔频谱图、VDTTS 的梅尔频谱图输出、标准 TTS 模型的梅尔频谱图输出,以及两张图,显示 VDTTS 和 TTS 与真实信号相比的归一化 F0(按平均非零音高归一化,即平均值仅在有声周期内)。
视频样本
原来的 虚拟模拟测试系统 VDTTS 仅限视频 语音合成
原始显示原始视频剪辑。VDTTS显示使用视频帧和文本作为输入预测的音频。 VDTTS 纯视频显示仅使用视频帧的音频预测。TTS显示仅使用文本的音频预测。顶部文字记录:“为人们做出自己的判断和得出自己的判断提供了空间”。底部文字记录:“绝对喜欢跳舞,我没有任何舞蹈经验,但就是这样”。
模型性能
我们使用 VoxCeleb2 数据集测量了 VDTTS 模型的性能,并将其与 TTS 和带长度提示的 TTS(接收场景长度的 TTS)模型进行了比较。我们证明,在我们测量的大多数方面,VDTTS 的表现都远胜于这两个模型:更高的同步视频质量(通过SyncNet Distance 测量)和更好的语音质量(通过梅尔倒谱距离(MCD) 测量),以及更低的总音调误差(GPE),后者衡量在预测和参考音频中都有语音的帧中音调相差超过 20% 的帧的百分比。
SyncNet 比较 VDTTS、TTS 和带有长度提示的 TTS 之间的距离(度量越低越好)。
VDTTS、TTS 和带有长度提示的 TTS 之间的梅尔倒谱距离比较(度量越低越好)。
VDTTS、TTS 和带有长度提示的 TTS 之间的总音高误差比较(指标越低越好)。
讨论和未来工作
值得注意的是,有趣的是,VDTTS 可以产生视频同步语音,而无需任何明确的损失或限制来促进这一点,这表明同步损失或明确建模等复杂性是不必要的。
虽然这只是一个概念验证演示,但我们相信,未来 VDTTS 可以升级,用于输入文本与原始视频信号不同的场景。这种模型对于翻译配音等任务来说将是一个有价值的工具。
致谢
我们要感谢本研究的合著者:Michelle Tadmor Ramanovich、Ye Jia、Brendan Shillingford 和 Miaosen Wang。我们还感谢 Nadav Bar、Jay Tenenbaum、Zach Gleicher、Paul McCartney、Marco Tagliasacchi 和 Yoni Tzafir 的宝贵贡献、讨论和反馈。
评论