在努力了解量子世界的过程中,科学家面临一个巨大的障碍:他们对世界的经典体验。每当测量一个量子系统时,测量行为就会破坏状态的“量子性”。例如,如果量子态处于两个位置的叠加态,它似乎可以同时出现在两个地方,一旦测量它,它就会随机出现在“这里”或“那里”,但不会同时出现。我们只能看到这个奇怪的量子世界投射出的经典阴影。
越来越多的实验正在实施机器学习 (ML) 算法来帮助分析数据,但这些算法与它们想要帮助的人一样具有局限性:它们无法直接访问和学习量子信息。但如果有一种量子机器学习算法可以直接与这些量子数据交互,情况会怎样呢?
在《科学》杂志上发表的一篇与加州理工学院、哈佛大学、伯克利大学和微软研究人员合作的论文 《从实验中学习的量子优势》中,我们表明量子学习代理在许多任务上的表现可以比传统学习代理好得多。使用谷歌的量子计算机Sycamore ,我们展示了量子机器学习(QML) 算法相对于最佳传统算法的巨大优势。与之前的量子优势演示不同,传统计算能力的任何进步都无法弥补这一差距。这是首次展示出在学习量子系统方面可证明的指数优势,即使在当今嘈杂的硬件上也具有鲁棒性。
量子加速
QML 结合了量子计算和鲜为人知的量子传感领域的优点。
对于某些问题, 量子计算机可能会比传统系统带来指数级的改进,但要发挥其潜力,研究人员首先需要扩大量子比特的数量并改进量子纠错。更重要的是,量子计算机承诺的比传统算法更快的指数级加速依赖于一个关于所谓问题“复杂性类别”的未经证实的假设——即量子计算机上可以解决的问题类别比传统计算机上可以解决的问题类别要大。这似乎是一个合理的假设,但却没有人证明过它。在得到证实之前,每一项量子优势的说法都会带有一个星号:它可以比任何已知的传统算法做得更好。
另一方面,量子传感器已经用于一些高精度测量,并且比传统传感器具有一定(且已被证明的)优势。一些量子传感器通过利用粒子之间的量子相关性来提取有关系统的更多信息。例如,科学家可以使用N 个原子的集合来测量原子环境的各个方面,例如周围的磁场。通常,原子可以测量的场的灵敏度与N的平方根成比例。但如果使用量子纠缠在原子之间创建复杂的关联网络,则可以将缩放比例改善为与N成比例。但与大多数量子传感协议一样,这种相对于传统传感器的二次加速是迄今为止最好的。
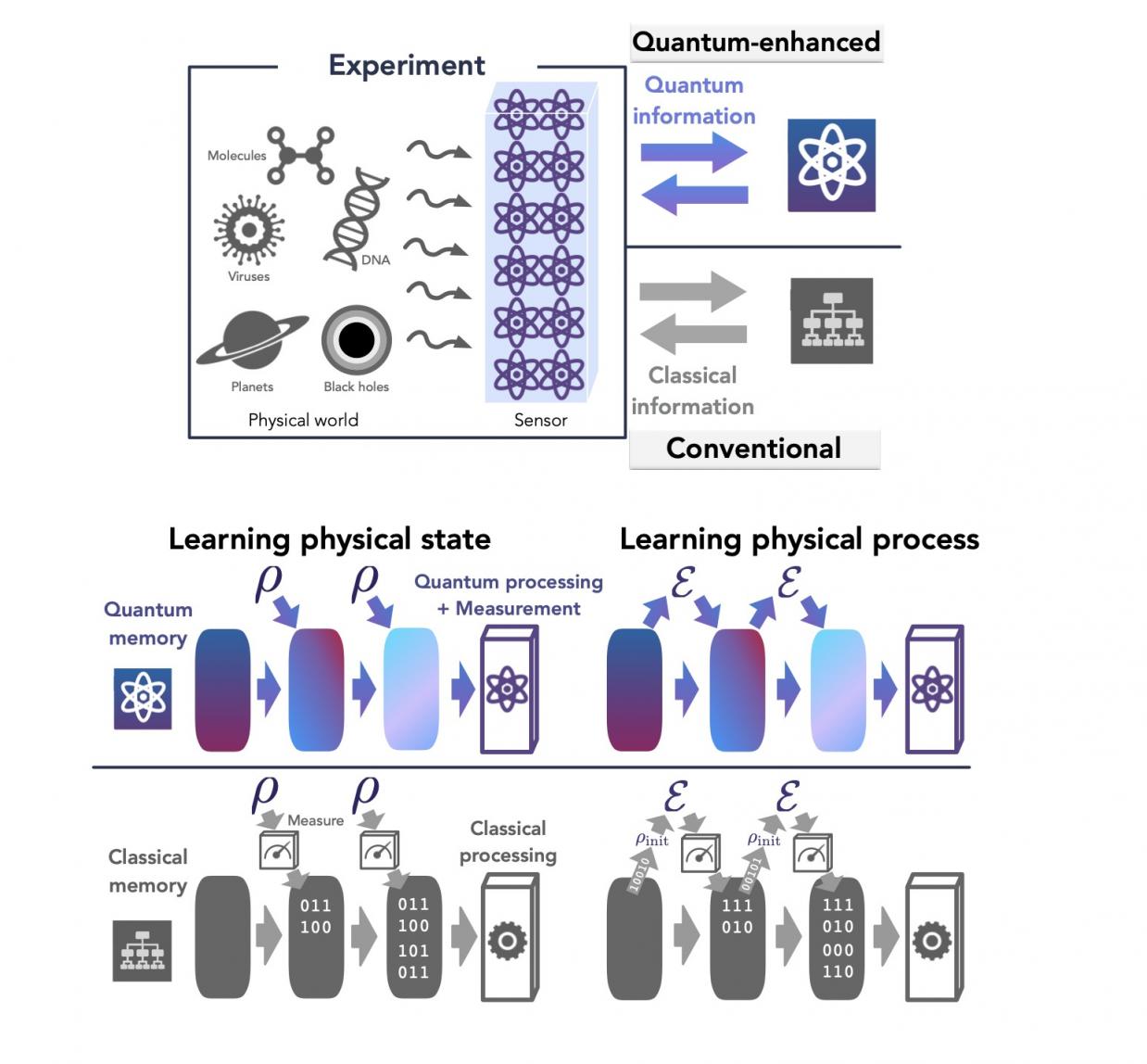
QML 是一种介于量子计算机和量子传感器之间的技术。QML 算法利用量子数据进行计算。量子计算机无需测量量子状态,而是可以存储量子数据并实施 QML 算法来处理数据而不会破坏数据。当这些数据有限时,QML 算法在考虑特定任务时可以从收到的每一块数据中挤出更多的信息。
经典机器学习算法与量子机器学习算法的比较。经典机器学习算法测量量子系统,然后对其获取的经典数据执行经典计算以了解该系统。另一方面,量子机器学习算法与系统产生的量子态相互作用,使其比 CML 具有量子优势。
要了解 QML 算法的工作原理,将其与标准量子实验进行对比很有用。如果科学家想要了解量子系统,他们可能会发送量子探针,例如原子或其他量子物体,其状态对感兴趣的系统敏感,让它与系统交互,然后测量探针。然后他们可以设计新的实验或根据测量结果做出预测。经典机器学习 (CML) 算法使用 ML 模型遵循相同的过程,但操作原理是相同的 - 它是一种处理经典信息的经典设备。
QML 算法则使用人工“量子学习器”。量子学习器发送探测器与系统交互后,可以选择存储量子状态而不是测量它。这就是 QML 的强大之处。它可以收集这些量子探测器的多个副本,然后将它们纠缠在一起,以更快地了解有关系统的更多信息。
例如,假设感兴趣的系统通过从某个可能状态分布中抽样,以概率方式产生量子叠加状态。每个状态由n 个量子比特或量子位组成,每个量子位都是“0”和“1”的叠加——所有学习者都可以知道状态的一般形式,但必须学习其细节。
在标准实验中,只能获取经典数据,每次测量都会提供量子态分布的快照,但由于这只是一个样本,因此需要测量该状态的许多副本才能重建它。事实上,它将需要 2 n 个副本的数量级。
QML 代理则更加聪明。通过保存n 个量子比特状态 的副本,然后将其与下一个副本纠缠在一起,它可以更快地了解全局量子状态,从而更快地了解状态是什么样子。
QML 算法的基本原理。保存量子态的两个副本,然后进行“贝尔测量”,其中每对量子态都相互纠缠,并测量它们的相关性。
经典重建就像试图在一片嘈杂的像素海洋中找到一幅图像——可能需要很长时间才能平均所有噪声才能知道图像代表什么。另一方面,量子重建利用量子力学通过同时寻找两幅不同图像之间的相关性来更快地分离出真实图像。
结果
为了更好地理解 QML 的强大功能,我们首先研究了三种不同的学习任务,并从理论上证明,在每种情况下,量子学习代理的表现都会比传统学习代理好得多。每个任务都与上面给出的示例相关:
了解量子态的不相容可观测量——即由于海森堡不确定性原理而无法同时以任意精度知道的可观测量,如位置和动量。但我们表明,可以通过纠缠多个状态副本来克服这一限制。
了解量子态的主要成分。当噪声存在时,它会干扰量子态。但通常“主成分”——叠加中概率最高的部分——对这种噪声具有很强的鲁棒性,因此我们仍然可以通过找到这个主要部分来收集有关原始状态的信息。
了解作用于量子系统或探测器的物理过程。有时,状态本身并不是感兴趣的对象,而是演变该状态的物理过程。我们可以通过分析状态随时间的变化来了解各种领域和相互作用。
除了理论工作外,我们还在 Sycamore 量子处理器上进行了一些原理验证实验。我们首先实施 QML 算法来执行第一项任务。我们将未知的量子混合状态输入算法,然后询问该状态的两个可观测量中哪一个更大。在使用模拟数据训练神经网络后,我们发现量子学习代理需要的实验次数呈指数级减少,即可达到 70% 的预测准确率——当系统大小为 20 个量子比特时,相当于测量次数减少了 10,000 倍。由于一次存储了两个副本,因此使用的量子比特总数为 40。
用于预测量子态可观测量的 QML 与 CML 算法的实验比较。虽然使用 CML 算法(上文中的“C”)实现 70% 准确度所需的实验次数会随着量子态 n 的大小呈指数增长,但 QML 算法(“Q”)所需的实验次数仅与 n 呈线性关系。标有“严格 LB (C)”的虚线表示经典机器学习算法的理论下限(LB)——最佳性能。
在第二个实验中,与上述任务 3 相关,我们让算法学习算子的对称性,该算子会演化其量子比特的量子态。具体来说,如果量子态可能经历完全随机或随机但时间反转对称的演化,那么经典学习者很难分辨出两者的区别。在此任务中,QML 算法可以将算子分为两个不同的类别,代表两个不同的对称类,而 CML 算法则完全失败。QML 算法是完全无监督的,因此这让我们有希望,该方法可用于发现新现象,而无需事先知道正确答案。
对 QML 与 CML 算法进行实验比较,以预测运算符的对称性类别。虽然 QML 成功分离了两个对称性类别,但 CML 未能完成这项任务。
结论
这项实验工作代表了量子机器学习中首次展现出的指数优势。与计算优势不同的是,当限制量子态的样本数量时,这种量子学习优势是无法挑战的,即使使用无限的传统计算资源也是如此。
到目前为止,该技术仅用于人为的“原理验证”实验,即故意产生量子态,研究人员假装不知道它是什么。要在实际实验中使用这些技术进行量子增强测量,我们首先需要研究当前的量子传感器技术和方法,以将量子态忠实地传输到量子计算机。但事实上,当今的量子计算机已经可以处理这些信息,从而在学习中取得指数级优势,这对量子机器学习的未来来说是一个好兆头。
致谢
我们要感谢我们的量子科学传播者 Katherine McCormick 撰写了这篇博文。
评论