最近的进展扩展了语言模型 (LM) 在下游任务中的适用性。一方面,通过思路链提示得到适当提示的现有语言模型展示了新兴能力,即执行自我调节的推理轨迹从问题中得出答案,擅长各种算术、常识和符号推理任务。然而,在思路链提示下,模型不扎根于外部世界,而是使用自己的内部表示来生成推理轨迹,从而限制了其被动探索和推理或更新知识的能力。另一方面,最近的研究使用预先训练的语言模型在各种交互式环境(例如,文本游戏、网页导航、体现任务、机器人技术)中进行规划和行动,重点是通过语言模型的内部知识将文本上下文映射到文本动作。但是,它们不会抽象地推理高级目标,也不会维持工作记忆来支持长远的行动。
在“ ReAct:语言模型中推理和行动的协同作用”中,我们提出了一种通用范式,将推理和行动的进步结合起来,使语言模型能够解决各种语言推理和决策任务。我们证明,在推动更大的语言模型和微调较小的语言模型时, Reason+Act (ReAct) 范式系统地优于仅推理和行动的范式。推理和行动的紧密结合还呈现出与人类一致的任务解决轨迹,从而提高了可解释性、可诊断性和可控制性。
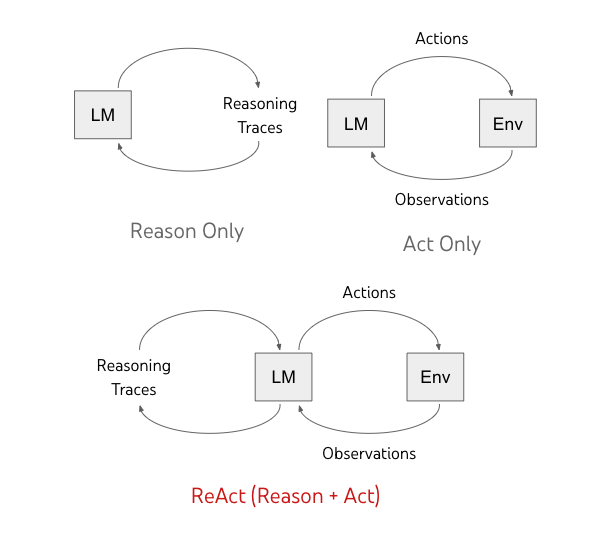
模型概述
ReAct 使语言模型能够以交错方式生成口头推理轨迹和文本动作。虽然动作会导致来自外部环境(下图中的“Env”)的观察反馈,但推理轨迹不会影响外部环境。相反,它们通过推理上下文并使用有用的信息更新模型来影响模型的内部状态,以支持未来的推理和行动。
先前的方法促使语言模型 (LM) 生成自调节的推理轨迹或特定于任务的操作。我们提出了 ReAct,这是一种结合语言模型中的推理和动作进步的新范式。
反应提示
我们重点关注这样一个设置:使用冻结语言模型PaLM-540B,通过少量上下文示例来提示,以生成特定于领域的操作(例如,问答中的“搜索”和房间导航中的“前往”)和自由形式的语言推理痕迹(例如,“现在我需要找到一个杯子,并把它放在桌子上”)以解决任务。
对于推理是首要任务的任务,我们交替生成推理轨迹和动作,以便任务解决轨迹由多个推理-动作-观察步骤组成。相反,对于可能涉及大量动作的决策任务,推理轨迹只需稀疏地出现在轨迹最相关的位置,因此我们编写具有稀疏推理的提示,并让语言模型自行决定推理轨迹和动作的异步发生。
如下所示,有用的推理痕迹有各种类型,例如,分解任务目标以创建行动计划、注入与任务解决相关的常识性知识、从观察中提取重要部分、跟踪任务进度同时保持计划执行、通过调整行动计划来处理异常等等。
推理和行动之间的协同作用使得模型能够进行动态推理,以创建、维护和调整行动的高级计划(行动的理由),同时还可以与外部环境(例如维基百科)进行交互,将其他信息纳入推理(行动推理)。
ReAct 微调
我们还探索使用 ReAct 格式轨迹微调较小的语言模型。为了减少对大规模人工注释的需求,我们使用 ReAct 提示的 PaLM-540B 模型来生成轨迹,并使用任务成功的轨迹来微调较小的语言模型 (PaLM-8/62B)。
比较四种提示方法:(a) 标准、(b) 思路链 (CoT,仅推理)、(c) 仅行动和 (d) ReAct,解决HotpotQA问题。省略了上下文示例,仅显示任务轨迹。ReAct 能够检索信息以支持推理,同时还使用推理来确定下一步要检索的内容,展示了推理和行动的协同作用。
结果
我们对 ReAct 和最先进的基线进行了实证评估,涉及四个不同的基准:问答 (HotPotQA)、事实验证 ( Fever )、基于文本的游戏 ( ALFWorld ) 和网页导航 ( WebShop )。对于 HotPotQA 和 Fever,通过访问可与模型交互的Wikipedia API,ReAct 的表现优于原始动作生成模型,同时在思路链推理 (CoT) 性能方面也具有竞争力。效果最好的方法是 ReAct 和 CoT 的组合,它在推理过程中同时使用内部知识和外部获取的信息。
HotpotQA(精确匹配,6 次) FEVER(准确度,3 发)
标准 28.7 57.1
仅理由 (CoT) 29.4 56.3
仅限行动 25.7 58.9
反应 27.4 60.9
最佳 ReAct + CoT 方法 35.1 64.6
监督式 SoTA 67.5(使用约 140k 个样本) 89.5(使用约 90k 个样本)
PaLM-540B 在 HotpotQA 和 Fever 上的提示结果。
在 ALFWorld 和 WebShop 上,采用一次性和两次提示的 ReAct 表现优于使用约 105 个任务实例训练的模仿和强化学习方法,与现有基线相比,成功率分别绝对提高了 34% 和 10%。
AlfWorld(2 张) 网上商店 (1 次)
仅限行动 四十五 30.1
反应 71 40
模仿学习基线 37(使用约 10 万个样本) 29.1(使用约 90k 个样本)
PaLM-540B 在 AlfWorld 和 WebShop 上提示任务成功率结果。
使用 ReAct 和不同基线对 HotPotQA 进行提示和微调的扩展结果。ReAct 始终实现最佳微调性能。
我们还通过允许人类检查员编辑 ReAct 的推理轨迹,探索了 ReAct 的人机交互。我们证明,只需用检查员提示替换幻觉句子,ReAct 就可以改变其行为以与检查员编辑保持一致并成功完成任务。使用 ReAct 解决任务变得容易得多,因为它只需要手动编辑一些想法,从而实现了新形式的人机协作。
AlfWorld 上使用 ReAct 进行人机交互行为矫正的示例。 (a) ReAct 轨迹由于幻觉推理轨迹而失败(第 17 幕)。 (b) 人类检查员编辑两个推理轨迹(第 17 幕、第 23 幕),然后 ReAct 产生理想的推理轨迹和动作来完成任务。
结论
我们提出了 ReAct,这是一种简单而有效的方法,用于协同语言模型中的推理和行动。通过专注于多跳问答、事实核查和交互式决策任务的各种实验,我们表明 ReAct 具有可解释的决策轨迹,可带来卓越的性能。
ReAct 证明了在语言模型中联合建模思维、行为和环境反馈的可行性,使其成为能够解决需要与环境交互的任务的多功能代理。我们计划进一步扩展这方面的研究,并利用语言模型的强大潜力来解决更广泛的具体任务,方法是通过大规模多任务训练和将 ReAct 与同样强大的奖励模型相结合等方法。
致谢
我们非常感谢 Jeffrey Zhao、Dian Yu、Nan Du、Izhak Shafran 和 Karthik Narasimhan 在本项工作中做出的巨大贡献。我们还要感谢 Google Brain 团队和普林斯顿 NLP 小组的共同支持和反馈,包括项目范围确定、建议和富有洞察力的讨论。
评论