神经网络吸收信息的能力受限于其参数的数量,因此,寻找更有效的方法来增加模型参数已成为深度学习研究的一种趋势。混合专家(MoE) 是一种条件计算,其中网络的某些部分根据每个示例进行激活,它被提出作为一种在不按比例增加计算量的情况下大幅提高模型容量的方法。在稀疏激活的 MoE 模型变体(例如Switch Transformer、GLaM、V-MoE)中,会根据每个标记或每个示例选择一组专家,从而在网络中创建稀疏性。此类模型已证明在多个领域具有更好的扩展能力,在持续学习设置中具有更好的保留能力(例如Expert Gate)。但是,不良的专家路由策略可能导致某些专家训练不足,从而导致专家专业化不足或过度。
在NeurIPS 2022上发表的 “混合专家与专家选择路由”中,我们介绍了一种名为专家选择 (EC) 的新型 MoE 路由算法。我们讨论了这种新方法如何在 MoE 系统中实现最佳负载平衡,同时允许令牌到专家映射中的异构性。与传统 MoE 网络中基于令牌的路由和其他路由方法相比,EC 表现出非常强的训练效率和下游任务得分。我们的方法与Pathways的愿景之一产生了共鸣,即通过 Pathways MPMD(多程序、多数据)支持实现异构专家混合。
MoE 路由概述
MoE 的运作方式是采用多个专家,每个专家作为一个子网络,并为每个输入标记仅激活一个或几个专家。必须选择和优化一个门控网络,以便将每个标记路由到最适合的专家。根据标记映射到专家的方式,MoE 可以是稀疏的,也可以是密集的。稀疏 MoE 在路由每个标记时仅选择专家子集,与密集 MoE 相比,可降低计算成本。例如,最近的研究已经通过k 均值聚类、线性分配以最大化标记专家亲和力或散列实现了稀疏路由。谷歌最近还宣布了GLaM和V-MoE ,它们都通过具有前k 个标记路由的稀疏门控 MoE 推动了自然语言处理和计算机视觉的最新发展,展示了使用稀疏激活的 MoE 层更好的性能扩展。许多先前的研究都使用了标记选择路由策略,其中路由算法为每个标记选择最好的一两个专家。
Token 选择路由。路由算法为每个 token 挑选出亲和力得分最高的前 1 名或前 2 名专家。亲和力得分可以与模型参数一起训练。
独立令牌选择方法通常会导致专家负载不平衡和利用率不足。为了缓解这种情况,以前的稀疏门控网络引入了额外的辅助损失作为正则化,以防止过多的令牌被路由到单个专家,但效果有限。因此,令牌选择路由需要大幅增加专家容量(计算容量的 2 倍至 8 倍),以避免在发生缓冲区溢出时丢失令牌。
除了负载不平衡之外,大多数先前的工作都使用 top- k函数为每个 token 分配固定数量的专家,而不考虑不同 token 的相对重要性。我们认为,不同的 token 应该由可变数量的专家接收,这取决于 token 的重要性或难度。
专家选择路由
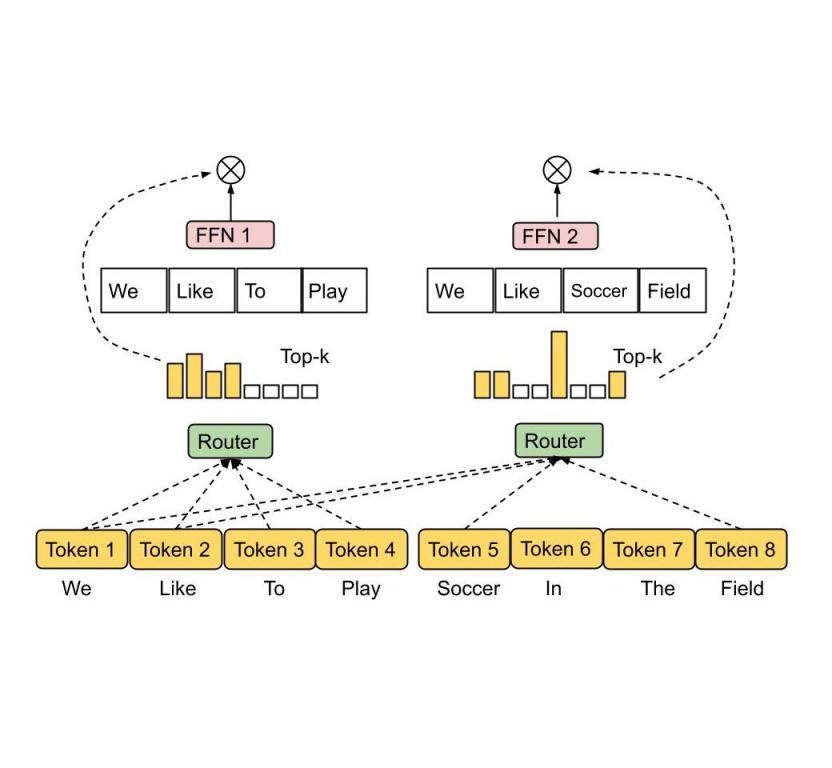
为了解决上述问题,我们提出了一种异构 MoE,它采用了如下所示的专家选择路由方法。不是让令牌选择前k个专家,而是将具有预定缓冲容量的专家分配给前k 个令牌。此方法可保证均匀的负载平衡,允许每个令牌有可变数量的专家,并在训练效率和下游性能方面实现显着提升。与Switch Transformer、GShard和GLaM中的前 1 和前 2 门控对应者相比,EC 路由在 8B/64E(80 亿激活参数,64 位专家)模型中将训练收敛速度提高了 2 倍以上。
专家选择路由。具有预定缓冲容量的专家被分配前k 个令牌,从而保证负载均衡。每个令牌可以由可变数量的专家接收。
在 EC 路由中,我们将专家容量k设置为一批输入序列中每个专家的平均标记乘以容量因子,这决定了每个标记可以接收的平均专家数量。为了了解标记到专家的亲和力,我们的方法生成了一个用于制定路由决策的标记到专家得分矩阵。得分矩阵表示一批输入序列中给定标记被路由到给定专家的可能性。
与 Switch Transformer 和 GShard 类似,我们在密集前馈(FFN) 层 中应用了 MoE 和门控函数,因为它是基于 Transformer 的网络中计算成本最高的部分。在生成 token-to-expert 分数矩阵后,沿 token 维度为每个专家应用 top- k函数来挑选最相关的 token。然后根据 token 的生成索引应用置换函数,以创建具有额外专家维度的隐藏值。数据被拆分到多个专家,以便所有专家都可以在 token 子集上同时执行相同的计算内核。由于可以确定固定的专家容量,我们不再因负载不平衡而过度配置专家容量,因此与 GLaM 相比,训练和推理步骤时间显著减少了约 20%。
评估
为了说明 Expert Choice 路由的有效性,我们首先研究训练效率和收敛性。我们使用容量因子为 2 的 EC(EC-CF2)将激活的参数大小和每个令牌的计算成本与 GShard top-2 门控相匹配,并运行固定数量的步骤。EC-CF2 在不到一半的步骤中达到与 GShard top-2 相同的困惑度,此外,我们发现每个 GShard top-2 步骤都比我们的方法慢 20%。
我们还扩展了专家数量,同时将 EC 和 GShard top-2 方法的专家规模固定为 100M 参数。我们发现,在预训练期间,这两种方法在评估数据集的困惑度方面都表现良好——拥有更多专家可以持续改善训练困惑度。
训练收敛的评估结果:与 GShard 和 GLaM 中使用的 top-2 门控相比,EC 路由在 8B/64E 规模下收敛速度提高了 2 倍(顶部)。EC 训练困惑度随着专家数量的增加而更好地扩展(底部)。
为了验证困惑度的提高是否能直接转化为下游任务的更好表现,我们对GLUE和SuperGLUE中选定的 11 个任务进行了微调。我们比较了三种 MoE 方法,包括 Switch Transformer top-1 门控 (ST Top-1)、GShard top-2 门控 (GS Top-2) 以及我们的方法的一个版本 (EC-CF2),该版本与 GS Top-2 的激活参数和计算成本相匹配。EC-CF2 方法始终优于相关方法,在大型 8B/64E 设置中平均准确率提高了 2% 以上。将我们的 8B/64E 模型与其密集模型进行比较,我们的方法实现了更好的微调结果,平均得分提高了 3.4 分。
我们的实证结果表明,限制每个代币的专家数量平均会使微调得分降低 1 分。这项研究证实,允许每个代币拥有可变数量的专家确实很有帮助。另一方面,我们计算了代币到专家路由的统计数据,特别是已路由到一定数量专家的代币比例。我们发现大多数代币已路由给一到两个专家,而 23% 的代币已路由给三到四个专家,只有约 3% 的代币已路由给四个以上的专家,从而验证了我们的假设,即专家选择路由学会为代币分配可变数量的专家。
最后的想法
我们提出了一种用于稀疏激活混合专家模型的新路由方法。该方法解决了传统 MoE 方法中的负载不平衡和专家利用不足问题,并允许为每个 token 选择不同数量的专家。与最先进的 GShard 和 Switch Transformer 模型相比,我们的模型的训练效率提高了 2 倍以上,并且在 GLUE 和 SuperGLUE 基准中的 11 个数据集上进行微调时实现了强劲的收益。
我们的专家选择路由方法通过简单的算法创新实现了异构 MoE。我们希望这可以在应用和系统层面推动该领域的更多进步。
致谢
谷歌研究部门的许多合作者都支持这项工作。我们特别感谢 Nan Du、Andrew Dai、Yanping Huang 和 Zhifeng Chen 在 MoE 基础设施和 Tarzan 数据集上所做的初步基础工作。我们非常感谢 Hanxiao Liu 和 Quoc Le 提供的初步想法和讨论。Tao Lei、Vincent Zhao、Da Huang、Chang Lan、Daiyi Peng 和 Yifeng Lu 在实施和评估方面做出了重大贡献。Claire Cui、James Laudon、Martin Abadi 和 Jeff Dean 提供了宝贵的反馈和资源支持。
评论