近年来,语言模型 (LM) 在自然语言处理 (NLP) 研究中变得越来越突出,并且在实践中也变得越来越有影响力。事实证明,扩大 LM 可以提高一系列 NLP 任务的性能。例如,扩大语言模型可以将困惑度提高七个数量级,并且已经观察到由于模型规模扩大而产生的多步推理等新功能。然而,持续扩大的挑战之一是训练新的、更大的模型需要大量的计算资源。此外,新模型通常是从头开始训练的,不会利用以前存在的模型的权重。
在这篇博文中,我们探讨了两种互补的方法,用于在不使用大量计算资源的情况下大幅改进现有的语言模型。首先,在“通过 0.1% 的额外计算超越扩展定律”中,我们介绍了 UL2R,这是一个轻量级的第二阶段预训练,使用混合降噪器目标。UL2R 可在一系列任务中提高性能,甚至可以在以前接近随机性能的任务上释放新兴性能。其次,在“扩展指令微调语言模型”中,我们探索在以指令形式表达的数据集集合上对语言模型进行微调,我们将这个过程称为“Flan”。这种方法不仅可以提高性能,而且还可以在不设计提示的情况下提高语言模型对用户输入的可用性。最后,我们表明,Flan 和 UL2R 可以作为互补技术结合在名为 Flan-U-PaLM 540B 的模型中,该模型在一系列具有挑战性的评估基准上的表现比未适应的 PaLM 540B 模型高出 10%。
UL2R 培训
传统上,大多数语言模型都是在因果语言建模目标 上进行预训练的,因果语言建模目标使模型能够预测序列中的下一个单词(例如GPT-3或PaLM),或去噪目标使模型学习从损坏的单词序列中恢复原始句子(例如 T5)。尽管在语言建模目标方面存在一些权衡,因为因果语言模型更适合长格式生成,而针对去噪目标训练的语言模型更适合微调,但在之前的工作中,我们证明了包含这两个目标的混合去噪器目标在两种情况下都能获得更好的性能。
然而,从头开始对大型语言模型进行不同目标的预训练可能会耗费大量计算资源。因此,我们提出了 UL2 修复 (UL2R),这是使用 UL2 目标继续进行预训练的附加阶段,只需要相对较少的计算量。我们将 UL2R 应用于 PaLM,并将生成的新语言模型称为 U-PaLM。
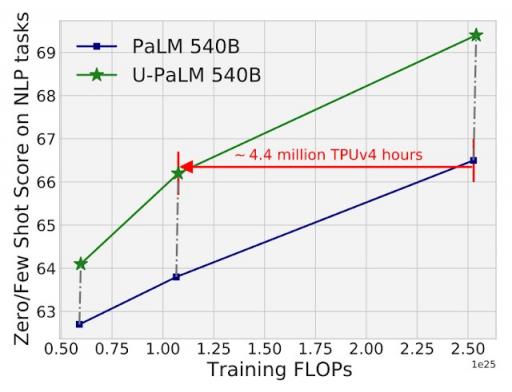
在实证评估中,我们发现仅需少量 UL2 训练,扩展曲线便会得到显著改善。例如,我们表明,通过在 PaLM 540B 的中间检查点上使用 UL2R,我们达到了最终 PaLM 540B 检查点的性能,同时使用的计算量减少了 2 倍(或相差 440 万 TPUv4 小时)。当然,如论文所述,将 UL2R 应用于最终 PaLM 540B 检查点也会带来显著的改进。
在 26 个 NLP 基准上对 PaLM 540B 和 U-PaLM 540B 的计算与模型性能进行了比较(列于本文表 8 中)。U-PaLM 540B 继续对 PaLM 进行少量计算训练,但性能却有显著提升。
我们观察到使用 UL2R 的另一个好处是,在某些任务上,其性能远优于纯粹针对因果语言建模目标进行训练的模型。例如,许多BIG-Bench任务被描述为“新兴能力”,即只有在足够大的语言模型中才能观察到的能力。虽然最常见的新兴能力发现方式是通过扩大语言模型的规模,但我们发现 UL2R 实际上可以在不增加语言模型规模的情况下引发新兴能力。
例如,在BIG-Bench 的Navigate任务中,该任务衡量模型执行状态跟踪的能力,除 U-PaLM 之外,所有训练 FLOP 少于 10 23的模型都实现了近似随机的性能。U-PaLM 的性能比 U-PaLM 高出 10 多分。另一个例子是BIG-Bench 的Snarks任务,该任务衡量模型检测讽刺的能力。同样,所有训练 FLOP 少于 10 24 的模型都实现了近似随机的性能,而 U-PaLM 甚至在 8B 和 62B 模型中也取得了远超预期的成绩。
对于BIG-Bench中展示新兴任务性能的两项能力,U-PaLM 由于使用了 UL2R 目标,因此可以在较小的模型尺寸下实现新兴任务。
指令微调
在我们的第二篇论文中,我们探索了指令微调,这涉及在以指令形式表达的 NLP 数据集上微调 LM。在之前的工作中,我们将指令微调应用于 62 个 NLP 任务上的 137B 参数模型,例如回答琐事问题、对电影的情感进行分类或将句子翻译成西班牙语。
在本研究中,我们在超过 1.8K 个任务上对 540B 参数语言模型进行了微调。此外,之前的努力仅对具有少样本(例如MetaICL)或无样本(例如FLAN、T0)的 LM 进行了微调,而我们则对两者的结合进行了微调。我们还加入了思路链微调数据,这使模型能够执行多步推理。我们将改进后的语言模型微调方法称为“Flan”。值得注意的是,即使在 1.8K 个任务上进行微调,与预训练相比,Flan 也仅使用一小部分计算(例如,对于 PaLM 540B,Flan 仅需要 0.2% 的预训练计算)。
我们对 1.8K 项以指令形式表达的任务进行语言模型微调,并对未见任务(未包含在微调中)进行评估。我们在有和没有样本(即零样本和少样本)以及有和没有思路链的情况下进行微调,从而能够在一系列评估场景中进行泛化。
在本文中,我们通过指令微调各种规模的 LM,以研究同时扩展 LM 规模和微调任务数量的联合效果。例如,对于 PaLM 类 LM,其包括 8B、62B 和 540B 参数的模型。我们在四个具有挑战性的基准评估套件(MMLU、BBH、TyDiQA和MGSM)上评估了我们的模型,发现扩展参数数量和微调任务数量都可以提高未见任务的性能。
扩展到 540B 参数模型并使用 1.8K 微调任务均可提高未见任务的性能。y 轴是四个评估套件(MMLU、BBH、TyDiQA和MGSM)的归一化平均值。
除了性能更佳之外,指令微调 LM 还使其能够在推理时响应用户指令,而无需少样本或快速工程。这使得 LM 在各种输入中都更加用户友好。例如,没有指令微调的 LM 有时会重复输入或无法遵循指令,但指令微调可以减轻此类错误。
与没有指令微调的 PaLM 模型相比,我们的指令微调语言模型 Flan-PaLM 对指令的响应更好。
将它们放在一起
最后,我们展示了 UL2R 和 Flan 可以结合起来训练 Flan-U-PaLM 模型。由于 Flan 使用来自 NLP 任务的新数据并启用零样本指令跟踪,我们将 Flan 作为 UL2R 之后的第二种方法。我们再次在四个基准套件上进行评估,发现 Flan-U-PaLM 模型的表现优于仅使用 UL2R(U-PaLM)或仅使用 Flan(Flan-PaLM)的 PaLM 模型。此外,当与思路链和自洽相结合时,Flan-U-PaLM 在MMLU 基准上取得了新的最佳成绩,得分为 75.4% 。
与仅使用 UL2R (U-PaLM) 或仅使用 Flan (Flan-U-PaLM) 相比,结合使用 UL2R 和 Flan (Flan-U-PaLM) 可获得最佳性能。性能是四个评估套件(MMLU、BBH、TyDiQA和MGSM)的标准化平均值。
总体而言,UL2R 和 Flan 是两种用于改进预训练语言模型的互补方法。UL2R 使用相同的数据将 LM 调整为混合降噪器目标,而 Flan 利用来自超过 1.8K 个 NLP 任务的训练数据来教模型遵循指令。随着 LM 变得越来越大,诸如 UL2R 和 Flan 之类的无需大量计算即可提高总体性能的技术可能会变得越来越有吸引力。
致谢
我很荣幸能与 Hyung Won Chung、Vinh Q. Tran、David R. So、Siamak Shakeri、Xavier Garcia、Huaixiu Steven Zheng、Jinfeng Rao、Aakanksha Chowdhery、Denny Zhou、Donald Metzler、Slav Petrov、Neil Houlsby、Quoc V. Le、Mostafa Dehghani、Le Hou、Shayne Longpre、Barret Zoph、Yi Tay、William Fedus、Yunxuan Li、Xuezhi Wang、Mostafa Dehghani、Siddhartha Brahma、Albert Webson、Shixiang Shane Gu、Zhuyun Dai、Mirac Suzgun、Xinyun Chen、Sharan Narang、Gaurav Mishra、Adams Yu、Vincent Zhao、Yanping Huang、Andrew Dai、Hongkun Yu、Ed H. Chi、Jeff Dean、Jacob Devlin 和 Adam Roberts 合作撰写这两篇论文。
评论