成为一名科学家是一件非常令人兴奋的事情。随着机器学习 (ML) 和量子计算的惊人进步,我们现在拥有强大的新工具,这些工具使我们能够满足好奇心、以新的方式进行协作,并从根本上加速突破性科学发现的进程。
自八年前加入 Google Research 以来,我很荣幸能成为一群才华横溢的研究人员中的一员,他们热衷于应用尖端计算来突破应用科学的极限。我们的团队正在探索物理和自然科学领域的主题。因此,在今年的博客文章中,我想重点介绍我们最近在生物学和物理学领域取得的重大进展,从帮助整理世界蛋白质和基因组信息以造福人们的生活,到利用量子计算机提高我们对宇宙本质的理解。这项工作的巨大潜力令我们深受启发。
利用机器学习解开生物学之谜
我们的许多研究人员都对生物学的非凡复杂性着迷,从大脑的奥秘到蛋白质的潜力,再到编码生命语言的基因组。我们一直与来自世界各地其他领先组织的科学家合作,应对连接组学、蛋白质功能预测和基因组学领域的重要挑战,并使我们的创新成果能够为广大科学界所用。
神经生物学
我们由Google 开发的机器学习方法 的一个令人兴奋的应用是探索信息如何通过斑马鱼大脑中的神经通路传播,这可以深入了解鱼类如何进行群体等社会行为。通过与马克斯·普朗克生物智能研究所的研究人员合作,我们能够通过计算重建使用 3D 电子显微镜成像的斑马鱼大脑的一部分 - 这是使用成像和计算管道绘制小脑中神经回路的一项令人兴奋的进步,也是我们在连接组学领域的 长期贡献的又一步。
斑马鱼幼虫大脑神经回路的重建,由马克斯普朗克生物智能研究所提供。
这项工作所需的技术进步甚至会应用于神经科学以外的领域。例如,为了解决处理如此庞大的连接组学数据集的困难,我们开发并发布了TensorStore,这是一个开源 C++ 和 Python 软件库,专为存储和操作n维数据而设计。我们期待看到它在其他领域用于存储大型数据集的方式。
我们还通过比较人类语言处理和自回归深度语言模型(DLM) ,使用 ML 阐明人类大脑如何完成语言等非凡技能。在这项研究中,我们与普林斯顿大学和纽约大学格罗斯曼医学院的同事合作,参与者收听了 30 分钟的播客,同时使用皮层脑电图记录他们的大脑活动。记录表明,人类大脑和 DLM 共享处理语言的计算原理,包括连续的下一个词预测、对上下文嵌入的依赖,以及基于单词匹配计算发作后的惊讶程度(我们可以测量人类大脑对单词的惊讶程度,并将惊讶信号与 DLM 对该单词的预测程度相关联)。这些结果为人类大脑的语言处理提供了新的见解,并表明 DLM 可用于揭示有关语言神经基础的宝贵见解。
生物化学
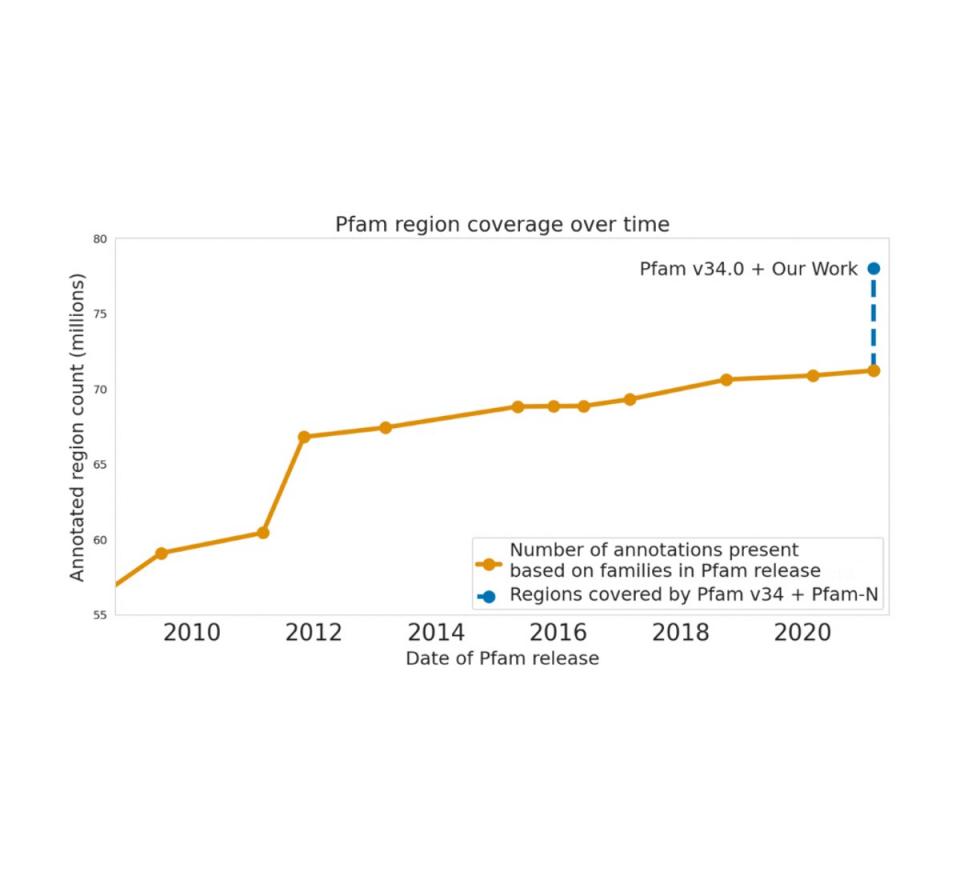
机器学习还使我们在理解生物序列方面取得了重大进展。2022 年,我们利用深度学习的最新进展,根据原始氨基酸序列准确预测蛋白质功能。我们还与欧洲分子生物学实验室的欧洲生物信息学研究所(EMBL-EBI) 密切合作,仔细评估模型性能,并向公共蛋白质数据库UniProt、Pfam/InterPro和MGnify添加数亿个功能注释。蛋白质数据库的人工注释可能是一个费力而缓慢的过程,我们的机器学习方法实现了巨大的飞跃——例如,将 Pfam 注释的数量增加到比过去十年所有其他努力的总和还要多。每年访问这些数据库的全球数百万科学家现在可以将我们的注释用于他们的研究。
Google Research 对 Pfam 的贡献在规模上超过了过去十年对该数据库所做的所有扩展努力。
尽管人类基因组的初稿于 2003 年发布,但由于测序技术的技术限制,该初稿并不完整且存在许多空白。2022 年,我们庆祝了端粒-2-端粒 (T2T) 联盟在解决这些以前无法获得的区域方面取得的卓越成就——包括五个完整的染色体臂和近 2 亿个碱基对的新 DNA 序列——这对于人类生物学、进化和疾病问题来说非常有趣且重要。我们的开源基因组变异调用器DeepVariant是T2T 联盟用于准备发布完整的 30.55 亿个碱基对人类基因组序列的工具之一。T2T 联盟还在他们最新的研究中使用了我们较新的开源方法DeepConsensus,该方法为 Pacific Biosciences 长读测序仪器提供设备上纠错功能,旨在获得能够代表人类遗传多样性广度的综合泛基因组资源。
利用量子计算进行新的物理发现
在科学发现方面,量子计算仍处于起步阶段,但潜力巨大。我们正在探索提高量子计算能力的方法,以便它成为科学发现和突破的工具。通过与来自世界各地的物理学家合作,我们也开始使用现有的量子计算机来创造有趣的新物理实验。
作为此类实验的一个例子,考虑这样一个问题:传感器测量某物,然后计算机处理来自传感器的数据。传统上,这意味着传感器的数据在我们的计算机上被处理为经典信息。相反,量子计算的一个想法是直接处理来自传感器的量子数据。将量子传感器的数据直接输入量子算法而不经过经典测量可能会带来很大的优势。在最近与多所大学的研究人员合作撰写的一篇《科学》论文中,我们表明,只要量子计算机直接耦合到量子传感器并运行学习算法,量子计算就可以从比传统计算少得多的实验中提取信息。这种“量子机器学习”可以在数据集大小方面产生指数级优势,即使使用当今嘈杂的中型量子计算机也是如此。由于实验数据通常是科学发现的限制因素,因此量子机器学习有可能为科学家释放量子计算机的巨大潜力。更妙的是,这项工作的见解也适用于学习量子计算的输出,例如可能难以提取的量子模拟的输出。
即使没有量子 ML,量子计算机的一个强大应用也是通过实验探索原本不可能观察或模拟的量子系统。2022 年,量子人工智能团队使用这种方法观察到了使用超导量子比特处于束缚态的多个微波光子的第一个实验证据。光子通常不会相互作用,需要额外的非线性元素才能使它们相互作用。我们对这些相互作用的量子计算机模拟结果令我们感到惊讶——我们原以为这些束缚态的存在依赖于脆弱的条件,但相反,我们发现它们即使对我们施加的相对较强的扰动也具有鲁棒性。
n 光子束缚态的占有概率与离散时间步长的关系。我们观察到大多数光子(深色)仍然束缚在一起。
鉴于我们在应用量子计算实现物理突破方面取得的初步成功,我们对这项技术未来可能实现突破性发现充满希望,这些发现可能对社会产生与晶体管或GPS一样重大的影响。量子计算作为科学工具的未来令人兴奋!
致谢
我要感谢为本文所述进展付出辛勤努力的所有人,包括 Google 应用科学、量子 AI、基因组学和 Brain 团队以及他们在 Google Research 和外部的合作者。最后,我要感谢在本文撰写过程中提供反馈的许多 Google 员工,包括 Lizzie Dorfman、Erica Brand、Elise Kleeman、Abe Asfaw、Viren Jain、Lucy Colwell、Andrew Carroll、Ariel Goldstein 和 Charina Chou。
评论