当患者被诊断出患有癌症时,最重要的步骤之一是病理学家在显微镜下检查肿瘤,以确定癌症分期并描述肿瘤的特征。这些信息对于了解临床预后(即可能的患者结果)和确定最合适的治疗方法(例如单独进行手术还是手术加化疗)至关重要。开发病理学中的机器学习 (ML) 工具来协助显微镜检查是一个引人注目的研究领域,具有许多潜在的应用。
先前的研究表明,ML 可以准确识别和分类病理图像中的肿瘤,甚至可以使用已知的病理特征(例如腺体外观与正常的偏差程度)预测患者的预后。虽然这些努力主要集中在使用 ML 检测或量化已知特征,但替代方法提供了识别新特征的潜力。通过提取当前工作流程中尚未考虑的信息,新特征的发现反过来可以进一步改善癌症预测和患者的治疗决策。
今天,我们想分享过去几年来与奥地利格拉茨医科大学和意大利米兰比可卡大学(UNIMIB) 的团队合作,在识别结直肠癌的新特征方面取得的进展。下面,我们将介绍这项工作的几个阶段:(1) 训练一个模型,从病理图像中预测预后,而无需指定要使用的特征,以便它可以了解哪些特征是重要的;(2) 使用可解释性技术探测该预后模型;(3) 识别一个新特征并验证其与患者预后的关联。我们在最近发表的论文“病理学家对机器学习特征用于结肠癌风险分层的验证”中描述了这一特征并评估了病理学家对它的使用。据我们所知,这是首次证明医学专家可以从机器学习中学习新的预后特征,为这种“从深度学习中学习”范式的未来开了个好头。
训练预测模型以了解哪些特征是重要的
识别新特征的一种潜在方法是训练 ML 模型,使其仅使用图像和配对结果数据直接预测患者结果。这与训练模型预测已知病理特征的“中间”人工注释标签,然后使用这些特征预测结果形成对比。
我们团队的初步工作表明,使用公开的TCGA 数据集, 训练模型可以直接预测各种癌症类型的预后。特别令人兴奋的是,对于某些癌症类型,在控制了可用的病理和临床特征后,该模型的预测具有预后意义。随后,我们与格拉茨医科大学和格拉茨生物库的合作者一起,使用大量未识别的结肠直肠癌队列扩展了这项工作。解释这些模型预测成为一个有趣的下一步,但常见的可解释性技术很难应用于这种背景下,并且没有提供清晰的见解。
解释模型学习的特征
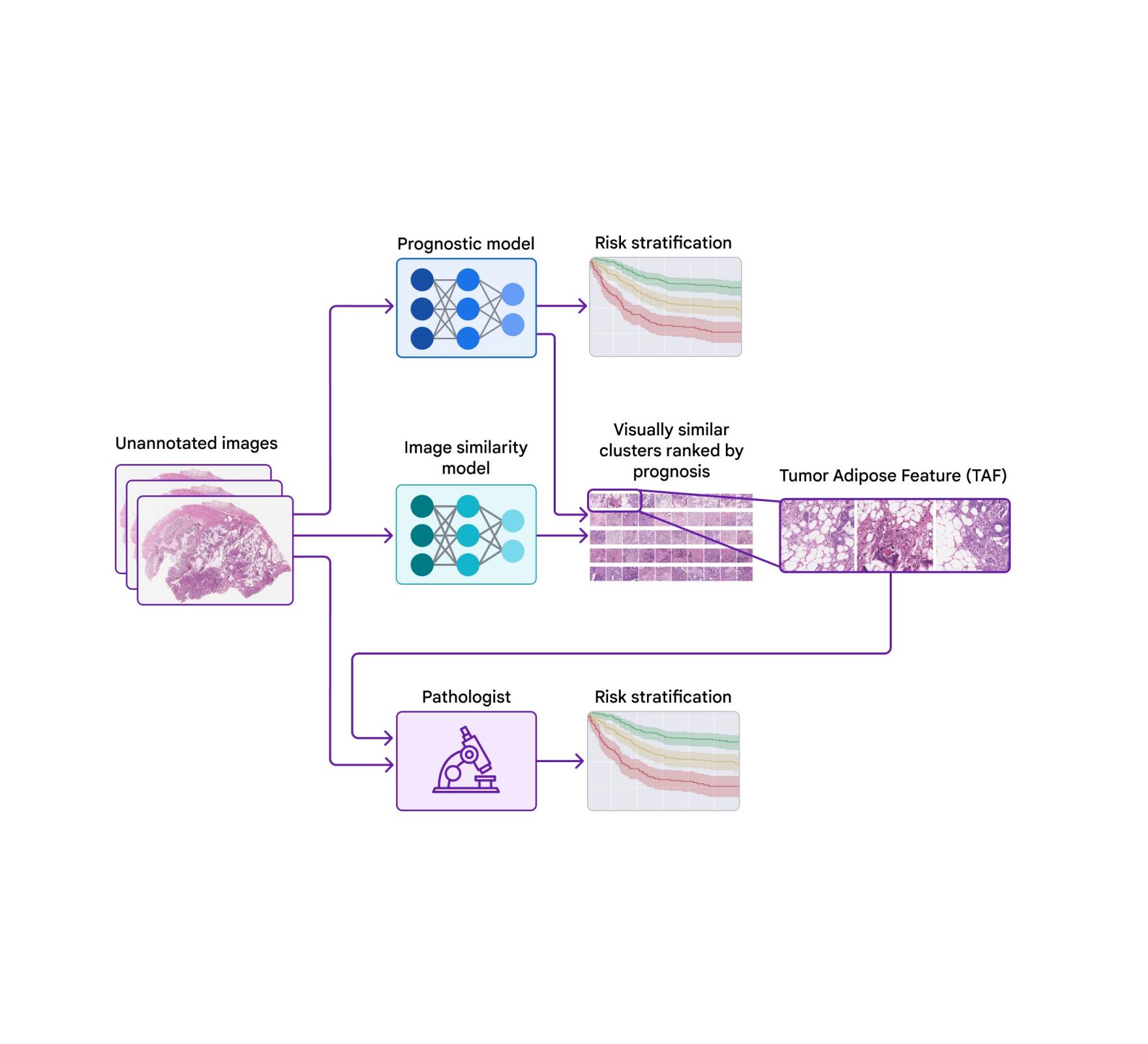
为了探究预后模型所使用的特征,我们使用了第二个模型(经过训练以识别图像相似性)对大型病理图像的裁剪块进行聚类。然后,我们使用预后模型计算每个聚类的平均 ML 预测风险评分。
其中一个簇因其高平均风险评分(与不良预后相关)和独特的视觉外观而引人注目。病理学家将图像描述为高级别肿瘤(即最不像正常组织)靠近脂肪组织,这导致我们将该簇称为“肿瘤脂肪特征”(TAF);有关此特征的详细示例,请参见下图。进一步分析表明,TAF 的相对数量本身具有高度且独立的预后性。
开发了一种预后 ML 模型,可直接从未注释的千兆像素病理图像预测患者的生存率。第二个图像相似性模型用于对病理图像的裁剪块进行聚类。预后模型用于计算每个聚类的平均模型预测风险评分。一个被称为“肿瘤脂肪特征”(TAF)的聚类因其高平均风险评分(与较差的生存率相关)和独特的视觉外观而脱颖而出。病理学家学会了识别 TAF,病理学家对 TAF 的评分被证明具有预后意义。
左图:H&E 病理切片,叠加热图显示肿瘤脂肪特征 (TAF) 的位置。与以绿色/蓝色突出显示的区域或根本没有突出显示的区域相比,图像相似性模型认为以红色/橙色突出显示的区域更有可能是 TAF。右图:多个病例中 TAF 斑块的代表性集合。
验证模型学习的特征可供病理学家使用
这些研究提供了一个令人信服的例子,展示了 ML 模型预测患者结果的潜力,以及获得模型预测见解的方法。然而,仍然存在一些有趣的问题:病理学家是否可以学习和评分模型识别的特征,同时保持可证明的预后价值。
在我们最近的论文中,我们与UNIMIB的病理学家合作研究了这些问题。UNIMIB 病理学家使用以前出版物中的 TAF 示例图像来学习和理解这一感兴趣的特征,制定了 TAF 的评分指南。如果未看到 TAF,则将病例评为“缺失”,如果观察到 TAF,则使用“单灶”、“多灶”和“广泛”类别来表示相对数量。我们的研究表明,病理学家可以重现地识别 ML 衍生的 TAF,并且他们对 TAF 的评分在独立的回顾性数据集上提供了具有统计学意义的预后价值。据我们所知,这是病理学家首次学习识别和评分最初由基于 ML 的方法识别的特定病理特征。
把事物放在上下文中:以深度学习为范式
我们的工作是人们“从深度学习中学习”的一个例子。在传统的机器学习中,模型从基于现有领域知识的手工设计特征中学习。最近,在深度学习时代,大规模模型架构、计算和数据集的结合使得人们能够直接从原始数据中学习,但这往往以牺牲人类的可解释性为代价。我们的工作将使用深度学习预测患者结果与可解释性方法结合起来,以提取可供病理学家应用的新知识。我们认为这一过程是将机器学习应用于医学和科学问题的自然发展,从使用机器学习来提炼现有的人类知识转变为人们使用机器学习作为知识发现的工具。
传统机器学习侧重于利用人类现有的知识从原始数据中设计特征。深度学习使模型能够直接从原始数据中学习特征,但牺牲了人类的可解释性。将深度学习与可解释性方法相结合,为通过深度学习学习来拓展科学知识的前沿提供了一条途径。
致谢
如果没有合著者 Vincenzo L'Imperio、Markus Plass、Heimo Muller、Nicolò' Tamini、Luca Gianotti、Nicola Zucchini、Robert Reihs、Greg S. Corrado、Dale R. Webster、Lily H. Peng、Po-Hsuan Cameron Chen、Marialuisa Lavitrano、David F. Steiner、Kurt Zatloukal 和 Fabio Pagni 的努力,这项工作就不可能实现。我们还要感谢 Verily Life Sciences 和 Google Health Pathology 团队的支持 - 特别是 Timo Kohlberger、Yunnan Cai、Hongwu Wang、Kunal Nagpal、Craig Mermel、Trissia Brown、Isabelle Flament-Auvigne 和 Angela Lin。我们还感谢 Akinori Mitani、Rory Sayres 和 Michael Howell 的手稿反馈,以及 Abi Jones 的插图帮助。如果没有 Christian Guelly、Andreas Holzinger、Robert Reihs、Farah Nader、Melissa Moran、Robert Nagle、格拉茨生物库的支持,格拉茨医科大学和谷歌的幻灯片数字化团队的努力,在模型开发过程中审查和注释病例的病理学家的参与,以及 UNIMIB 团队的技术人员的支持,这项工作也不可能实现。
评论