时间序列预测是一个重要的研究领域,对零售供应链优化、能源和交通预测以及天气预报等多项科学和工业应用至关重要。例如,在零售用例中,人们观察到,提高需求预测准确性可以显著降低库存成本并增加收入。
现代时间序列应用可能涉及预测数十万个相关时间序列(例如,零售商对不同产品的需求),预测范围很长(例如,以每日粒度预测一个季度或一年)。因此,时间序列预测模型需要满足以下关键标准:
处理辅助特征或协变量的能力:大多数用例可以从有效使用协变量中获得巨大收益,例如在零售预测中,假期和产品特定属性或促销活动会影响需求。
适用于不同的数据模式:它应该能够处理稀疏计数数据,例如,对销售量较低的产品的间歇性需求,同时还能够在流量预测中模拟稳健的连续季节性模式。
许多基于神经网络的解决方案在基准测试中表现出色,并支持上述标准。然而,这些方法通常训练速度较慢,推理成本较高,尤其是对于较长的预测范围。
在“使用 TiDE 进行长期预测:时间序列密集编码器”中,我们介绍了一种用于时间序列预测的全多层感知器(MLP) 编码器-解码器架构,与基于Transformer的解决方案相比,该架构在长期时间序列预测基准上实现了卓越的性能,同时速度提高了 5-10 倍。然后在“关于最大似然估计对回归和预测的好处”中,我们证明了使用基于最大似然估计(MLE) 的精心设计的训练损失函数可以有效处理不同的数据模态。这两项工作是互补的,可以作为同一模型的一部分应用。事实上,它们很快就会在Google Cloud AI 的 Vertex AutoML Forecasting中推出。
TiDE:一种用于快速准确预测的简单 MLP 架构
深度学习在时间序列预测方面显示出良好的前景,其表现优于传统的统计方法,尤其是对于大型多元数据集。在Transformer在自然语言处理(NLP) 领域取得成功后,已有多项研究评估了 Transformer 架构的变体,以用于长期(未来的时间量)预测,例如FEDformer和PatchTST。然而,其他研究表明,即使是线性模型也可以在时间序列基准上胜过这些 Transformer 变体。尽管如此,简单的线性模型还不足以表达辅助特征(例如,用于零售需求预测的假日特征和促销活动)和对过去的 非线性依赖关系。
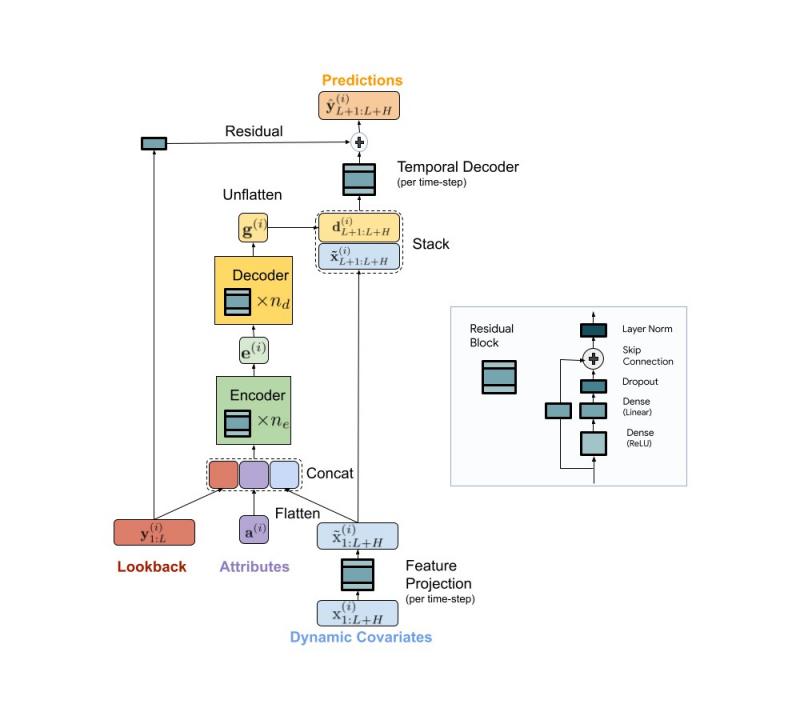
我们提出了一种可扩展的基于 MLP 的编码器-解码器模型,用于快速准确地进行多步预测。我们的模型使用 MLP 编码器对时间序列的过去和所有可用特征进行编码。随后,使用 MLP 解码器将编码与未来特征相结合,以得出未来预测。架构如下所示。
用于多步预测的 TiDE 模型架构。
与基于 Transformer 的基线相比,TiDE 的训练速度提高了 10 倍以上,同时在基准测试中也更准确。在推理中也可以观察到类似的增益,因为它仅与上下文的长度(模型回顾的时间步长数)和预测范围成线性比例。在左下方,我们展示了我们的模型在流行的流量预测基准上,就测试均方误差 (MSE)而言,比最好的基于 Transformer 的基线(PatchTST)好10.6%。在右侧,我们展示了我们的模型同时可以比 PatchTST 具有更快的推理延迟。
左图: 流行交通预测基准测试集上的MSE 。右图: TiDE 和 PatchTST 的推理时间与回溯长度的关系。
我们的研究表明,我们可以利用 MLP 的线性计算缩放与回顾和水平大小,而不会牺牲准确性,而在这种情况下,Transformer 的缩放是二次的。
概率损失函数
在大多数预测应用中,最终用户对常见的目标指标感兴趣,例如平均绝对百分比误差(MAPE)、加权绝对百分比误差(WAPE) 等。在这种情况下,标准方法是在训练时使用相同的目标指标作为损失函数。在ICLR接受的“论最大似然估计对回归和预测的好处”中,我们表明这种方法可能并非总是最好的。相反,我们主张对精心选择的分布系列(下面将详细讨论)使用最大似然损失,该分布系列可以在训练期间捕获数据集的归纳偏差。换句话说,预测神经网络不是直接输出最小化目标指标的点预测,而是预测所选系列中能够最有效地解释目标数据的分布的参数。在推理时,我们可以从学习到的预测分布中预测最小化感兴趣的目标指标的统计数据(例如,平均值最小化 MSE 目标指标,而中位数最小化 WAPE)。此外,我们还可以轻松获得预测的不确定性估计,即我们可以通过估计预测分布的分位数来提供分位数预测。在一些用例中,准确的分位数至关重要,例如,在需求预测中,零售商可能希望为第 90 个百分位数备货,以防范最坏情况并避免收入损失。
在这种情况下,分布族的选择至关重要。例如,在稀疏计数数据的背景下,我们可能希望有一个分布族,可以将更多的概率放在零上,这通常称为零膨胀。我们提出了一种混合不同分布的方法,并学习了混合权重,可以适应不同的数据模态。在论文中,我们表明,使用零和多个负二项分布的混合在各种设置中效果很好,因为它可以适应稀疏性、多模态、计数数据和具有亚指数尾部的数据。
零个和两个负二项分布的混合。三个分量 a 1、 a 2和 a 3的权重可以在训练过程中学习。
我们使用该损失函数在M5 预测竞赛数据集上训练 Vertex AutoML 模型,并表明这一简单的变化可以带来 6% 的收益,并在竞赛指标加权均方根缩放误差(WRMSSE) 中超越其他基准。
M5 预测 西门子功率谱
Vertex AutoML 0.639 +/- 0.007
具有概率损失的 Vertex AutoML 0.581 +/- 0.007
DeepAR 0.789 +/- 0.025
美联储前任 0.804 +/- 0.033
结论
我们展示了 TiDE 如何与概率损失函数结合,实现快速准确的预测,自动适应不同的数据分布和模态,并为其预测提供不确定性估计。它为大型企业预测应用提供了基于神经网络的解决方案中最先进的准确度,而成本仅为以前基于 Transformer 的预测架构的一小部分。我们希望这项工作也能激发人们对重新审视(理论和经验上)基于 MLP 的深度时间序列预测模型的兴趣。
致谢
这项工作是 Google Research 和 Google Cloud 的多位人员合作的成果,包括(按字母顺序排列):Pranjal Awasthi、Dawei Jia、Weihao Kong、Andrew Leach、Shaan Mathur、Petros Mol、Shuxin Nie、Ananda Theertha Suresh 和 Rose Yu。
评论