视觉语言基础模型建立在单次预训练和随后适应多个下游任务的前提下。两种主要的、不相交的训练场景很流行:CLIP风格的对比学习和下一个标记预测。对比学习训练模型预测图像-文本对是否正确匹配,有效地为相应的图像和文本输入构建视觉和文本表示,而下一个标记预测预测序列中最可能的下一个文本标记,从而根据所需任务学习生成文本。对比学习支持图像-文本和文本-图像检索任务,例如查找最符合某个描述的图像,而下一个标记学习支持文本生成任务,例如图像字幕和视觉问答(VQA)。虽然这两种方法都表现出强大的效果,但当模型经过对比预训练时,它通常在文本生成任务上表现不佳,反之亦然。此外,适应其他任务通常需要复杂或低效的方法。例如,为了将视觉语言模型扩展到视频,一些模型需要对每个视频帧分别进行推理。这将可处理的视频大小限制为几帧,并且无法充分利用跨帧的运动信息。
受此启发,我们提出了“一种用于多模态任务联合学习的简单架构”,称为 MaMMUT,它能够针对这些相互竞争的目标进行联合训练,并为许多视觉语言任务提供直接或通过简单调整的基础。MaMMUT 是一个紧凑的 2B 参数多模态模型,可跨对比、文本生成和本地化感知目标进行训练。它由一个图像编码器和一个文本解码器组成,允许直接重用这两个组件。此外,直接适应视频文本任务只需要使用一次图像编码器,并且可以处理比以前的工作多得多的帧。与最近的语言模型(例如PaLM、GLaM、GPT3)一致,我们的架构使用仅解码器的文本模型,可以被视为语言模型的简单扩展。尽管规模不大,我们的模型的表现却超越了最先进的水平,或在图像-文本和文本-图像检索、视频问答(VideoQA)、视频字幕、开放词汇检测和VQA 方面取得了具有竞争力的性能。
MaMMUT 模型支持多种任务,例如图像-文本/文本-图像检索(左上和右上)、VQA(中左)、开放词汇检测(中右)和 VideoQA(底部)。
仅解码器的模型架构
一个令人惊讶的发现是,单个语言解码器足以完成所有这些任务,从而无需之前提出的复杂构造和训练程序。例如,我们的模型(下图左侧显示)由单个视觉编码器和单个文本解码器组成,通过交叉注意连接,并同时训练对比和文本生成类型的损失。相比之下,以前的工作要么无法处理图像文本检索任务,要么仅对模型的某些部分应用某些损失。为了启用多模式任务并充分利用仅解码器模型,我们需要联合训练对比损失和文本生成字幕类损失。
MaMMUT 架构(左)是一个简单的结构,由单个视觉编码器和单个文本解码器组成。与其他流行的视觉语言模型(例如PaLI(中)和ALBEF、CoCa(右))相比,它针对多个视觉语言任务进行联合且高效的训练,同时具有对比和文本生成损失,完全共享任务之间的权重。
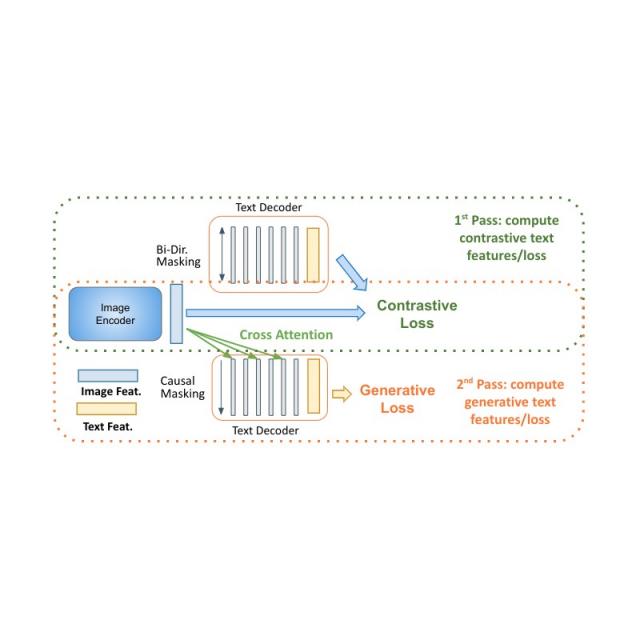
解码器两遍学习
用于语言学习的仅解码器模型在模型尺寸较小(几乎减少一半的参数)的情况下表现出明显的性能优势。将它们应用于多模态设置的主要挑战是将对比学习(使用无条件序列级表示)与字幕(优化以先前标记为条件的标记的可能性)统一起来。我们提出了一种两遍方法,在解码器中联合学习这两种相互冲突的文本表示类型。在第一遍中,我们利用交叉注意和因果掩蔽来学习字幕生成任务——文本特征可以关注图像特征并按顺序预测标记。在第二遍中,我们禁用交叉注意和因果掩蔽来学习对比任务。文本特征将看不到图像特征,但可以同时双向关注所有文本标记以生成最终的基于文本的表示。在同一个解码器中完成这种两遍方法可以同时完成以前难以协调的两种类型的任务。虽然简单,但我们表明该模型架构能够为多种多模式任务提供基础。
MaMMUT 仅解码器的两遍学习可通过同一模型实现对比学习路径和生成学习路径。
我们的架构的另一个优点是,由于它是针对这些不相交的任务进行训练的,因此它可以无缝地应用于多个应用程序,例如图像文本和文本图像检索、VQA 和字幕。
此外,MaMMUT 可轻松适应视频语言任务。以前的方法使用视觉编码器单独处理每个帧,这需要多次应用。这很慢,并且限制了模型可以处理的帧数,通常只有 6-8 帧。使用 MaMMUT,我们直接通过视频中的时空信息使用稀疏视频管进行轻量级自适应。此外,只需通过对象检测头进行训练以检测边界框,即可 将模型适应开放词汇检测。
MaMMUT 架构对视频任务的适应(左)很简单,并且完全重用了模型。这是通过生成类似于图像块的视频“管”特征表示来实现的,这些特征表示被投影到较低维度的标记并通过视觉编码器运行。与需要通过视觉编码器运行多个单独图像的先前方法(右)不同,我们只使用它一次。
结果
我们的模型在无需任何调整的情况下,在图像-文本和文本-图像检索中实现了出色的零样本结果,超越了所有之前最先进的模型。VQA 上的结果与最先进的结果相媲美,而最先进的结果是由更大的模型实现的。PaLI模型(17B 参数)和Flamingo 模型(80B)在VQA2.0 数据集上表现最佳,但 MaMMUT(2B)的准确率与 15B PaLI 相同。
MaMMUT 在MS-COCO(顶部)和Flickr(底部)基准测试中的零样本图像-文本 (I2T) 和文本-图像 (T2I) 检索方面均超越了最新技术 (SOTA) 。
VQA2.0 数据集上的性能具有竞争力,但并不优于 Flamingo-80B 和 PalI-17B 等大型模型。在更具挑战性的开放式文本生成设置中评估性能。
MaMMUT 在 VideoQA 上的表现也优于最先进的模型,如下图MSRVTT-QA和MSVD-QA数据集所示。请注意,我们的表现优于Flamingo等更大的模型,该模型专为图像+视频预训练而设计,并使用图像文本和视频文本数据进行预训练。
MaMMUT 在 VideoQA 任务(MSRVTT-QA 数据集,顶部,MSVD-QA 数据集,底部)上的表现优于 SOTA 模型,甚至优于更大的模型,例如 5B GIT2 或 Flamingo,它们使用 80B 参数并针对图像语言和视觉语言任务进行了预训练。
我们的结果在开放词汇检测微调方面优于最先进的技术,如下所示。
MAMMUT在LVIS数据集上的开放词汇检测结果与最新方法进行了比较。我们报告了稀有类别(APr) 的平均精度,如文献中先前采用的那样。
主要成分
我们表明,联合训练对比和文本生成目标并非易事,在我们的消融中,我们发现不同的设计选择可以更好地完成这些任务。我们发现,交叉注意力连接越少,检索任务就越好,但 VQA 任务则更喜欢交叉注意力连接越多。然而,虽然这表明我们的模型的设计选择对于单个任务来说可能不是最优的,但我们的模型比更复杂或更大的模型更有效。
消融研究表明,较少的交叉注意连接(1-2)更适合检索任务(顶部),而较多的连接则有利于文本生成任务,例如 VQA(底部)。
结论
我们提出了 MaMMUT,这是一个简单而紧凑的视觉编码器语言解码器模型,它联合训练了多个相互冲突的目标,以协调对比类任务和文本生成任务。我们的模型还为更多视觉语言任务奠定了基础,在图像文本和文本图像检索、视频问答、视频字幕、开放词汇检测和 VQA 方面取得了最先进或具有竞争力的表现。我们希望它可以进一步用于更多多模式应用。
致谢
所描述的作品的合著者为:Wei Cheng Kuo、AJ Piergiovanni、Dahun Kim、Xiyang Luo、Ben Caine、Wei Li、Abhijit Ogale、Luowei Zhou、Andrew Dai、Zhifeng Chen、Claire Cui 和 Anelia Angelova。我们要感谢 Mojtaba Seyedhosseini、Vijay Vasudevan、Priya Goyal、Jiahui Yu、Zirui Wang、Yonghui Wu、Runze Li、Jie Mei、Radu Soricut、Qingqing Huang、Andy Ly、Nan Du、Yuxin Wu、Tom Duerig、Paul Natsev、感谢 Zoubin Ghahramani 的帮助和支持。
评论