随着虚拟助手变得无处不在,用户越来越多地与它们互动,以了解新话题或获得建议,并期望它们能够提供超越一两轮狭隘对话的功能。动态规划,即根据对话流程展望未来并重新规划的能力,是进行引人入胜的对话的必要因素,能够满足用户期望的更深入、开放式的互动。
虽然大型语言模型 (LLM) 在许多自然语言处理基准测试中都超越了最先进的方法,但它们通常被训练为输出下一个最佳响应,而不是提前规划,而这是多轮交互所必需的。然而,在过去几年中,强化学习(RL) 在解决涉及动态规划的特定问题(例如获胜游戏和蛋白质折叠)方面取得了令人难以置信的成果。
今天,我们将分享我们在人机对话动态规划方面的最新进展,其中我们采用基于 RL 的方法,使助手能够朝着目标规划多轮对话,并实时调整该计划。在这里,我们将研究如何通过应用 RL 根据从可靠来源提取的信息撰写答案来改善长时间交互,而不是依赖于语言模型生成的内容。我们预计这项工作的未来版本可以在多轮对话中结合 LLM 和 RL。由于建模复杂性、巨大的状态和动作空间以及设计奖励函数的微妙性,在大型对话系统中“实地”部署 RL 被证明是一项艰巨的挑战。
什么是动态规划?
从收集信息到提供建议,许多类型的对话都需要灵活的方法和根据对话流程修改原始计划的能力。这种在对话中途转换话题的能力称为动态规划,与静态规划相对,后者指的是一种更固定的方法。例如,在下面的对话中,目标是通过分享有关酷动物的有趣事实来吸引用户。首先,助手通过声音测验将对话引向鲨鱼。考虑到用户对鲨鱼不感兴趣,助手随后制定了更新计划,并将对话转向海狮、狮子,然后是猎豹。
该助手动态修改了原来谈论鲨鱼的计划,并分享了有关其他动物的事实。
动态合成
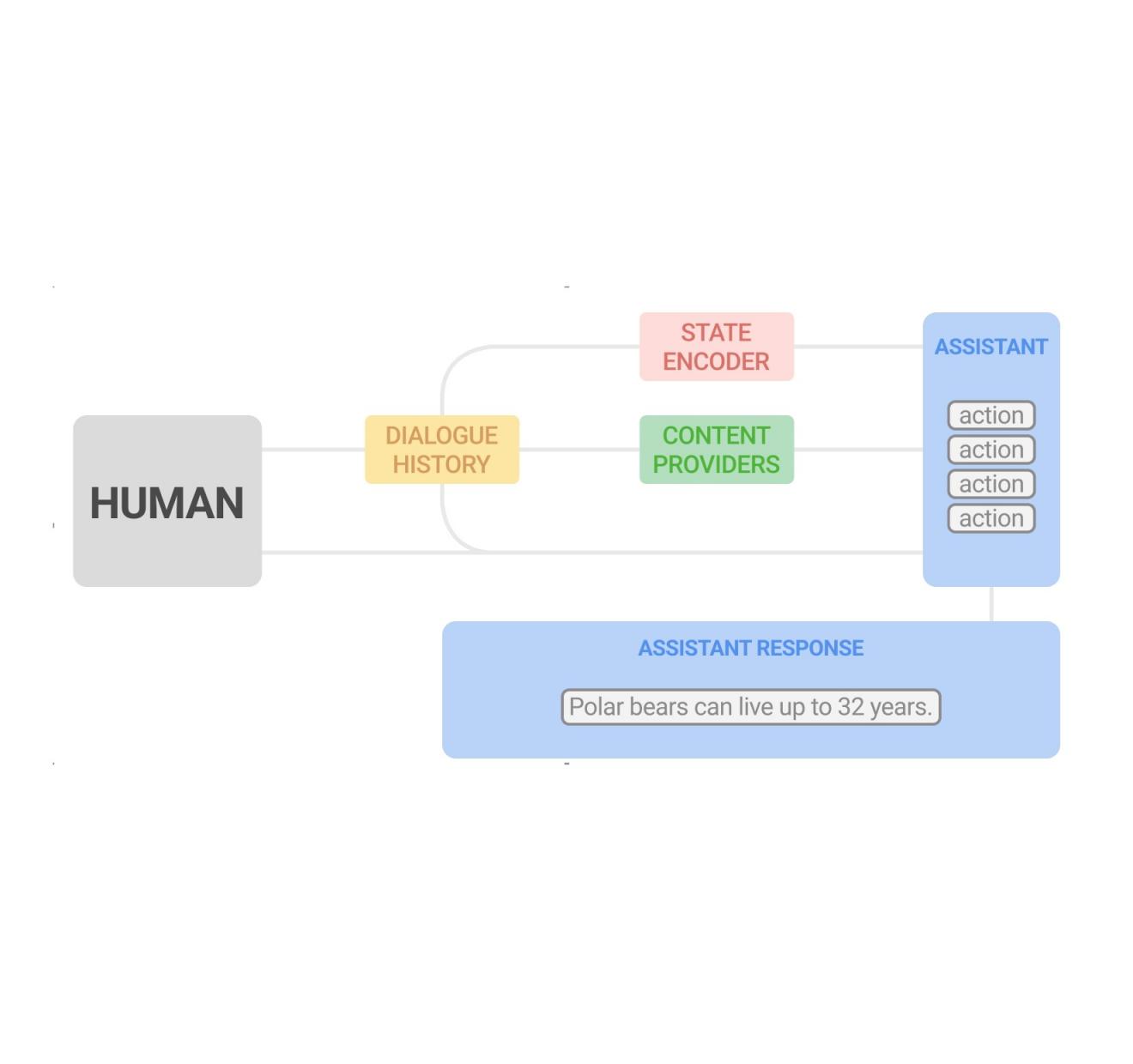
为了应对对话探索的挑战,我们将助手响应的生成分为两个部分:1)内容生成,从可靠来源提取相关信息; 2)将这些内容灵活地组合成助手响应。我们将这种两部分方法称为动态组合。与 LLM 方法不同,这种方法使助手能够完全控制其可能提供的内容的来源、正确性和质量。同时,它可以通过学习对话管理器实现灵活性,选择和组合最合适的内容。
在之前的一篇论文《对话领域探索的动态组合》中,我们描述了一种新方法,它包括:(1) 一组内容提供商,它们提供来自不同来源的候选词,例如新闻片段、知识图谱事实和问题;(2) 对话管理器;(3) 句子融合模块。每个助理响应都由对话管理器逐步构建,对话管理器选择内容提供商提出的候选词。然后将选定的话语序列融合成一个有凝聚力的响应。
使用 RL 进行动态规划
助手响应组合循环的核心是使用离策略强化学习训练的对话管理器,即评估和改进与代理使用的策略不同的策略的算法(在我们的例子中,后者基于监督模型)。将强化学习应用于对话管理面临多项挑战,包括大状态空间(因为状态代表对话状态,需要考虑整个对话历史)和实际上无界的动作空间(可能包括自然语言中所有现有的单词或句子)。
我们使用一种新颖的 RL 结构来解决这些挑战。首先,我们利用强大的监督模型(具体来说,循环神经网络(RNN) 和Transformer )来提供简洁有效的对话状态表示。这些状态编码器接收由一系列用户和助手轮流组成的对话历史记录,并以潜在向量的形式输出对话状态的表示。
其次,我们利用这样一个事实:内容提供商在每次对话中可以生成一组相对较小的合理候选话语或动作,并将动作空间限制在这些话语或动作上。虽然动作空间在 RL 设置中通常是固定的,因为所有状态共享相同的动作空间,但我们的动作空间是一个非标准空间,其中候选动作可能因每个状态而异,因为内容提供商会根据对话上下文生成不同的动作。这使我们处于随机动作集的领域,该框架形式化了每个状态下可用的动作集受外生随机过程控制的情况,我们使用随机动作 Q 学习(Q 学习方法的变体)来解决这个问题。Q 学习是一种流行的离策略 RL 算法,它不需要环境模型来评估和改进策略。我们使用监督对话管理器获得的众包计算评级对话语料库来训练我们的模型。
根据当前对话历史和新的用户查询,内容提供商会生成候选词,助手会从中选择一个。此过程循环运行,最后选定的话语会融合成一个连贯的响应。
强化学习模型评估
我们在一项使用 Google Assistant 的实验中将我们的 RL 对话管理器与已启动的监督式 Transformer 模型进行了比较,该模型与用户谈论动物。当用户通过询问与动物相关的问题(例如,“狮子的声音怎么样?”)触发体验时,对话就开始了。实验采用A/B 测试协议进行,其中随机抽取一小部分 Assistant 用户与基于 RL 的助手进行交互,而其他用户则与标准助手进行交互。
我们发现,RL 对话管理器可以进行更长、更吸引人的对话。它将对话长度增加了 30%,同时提高了用户参与度指标。我们发现对助手问题的合作性回应增加了 8%——例如,在回答“你接下来想听哪种动物?”时,回答“告诉我关于狮子的事”。虽然名义上的“不合作”回应也有很大的增加(例如,在回答提出更多内容的问题时,如“你想听更多吗?”,回答“不”,但这是意料之中的,因为 RL 代理通过提出转向问题承担了更多风险。虽然用户可能对助手提出的对话方向不感兴趣(例如转向另一种动物),但用户通常会继续参与有关动物的对话。
从第三轮的不合作用户反应(“不”)和第五轮的疑问“发出狗的声音”中,助手识别出用户最感兴趣的是动物的声音,并修改其计划,提供声音和声音测验。
此外,一些用户查询包含明确的正面反馈(例如“谢谢,Google”或“我很高兴”)或负面反馈(例如“闭嘴”或“停止”)。虽然它们比其他查询少一个数量级,但它们提供了用户(不)满意度的直接衡量标准。RL 模型将明确的正面反馈增加了 32%,并将负面反馈减少了 18%。
学习动态规划的特点和策略
我们观察到(未见过的)RL 计划的几个特点,这些特点可以在进行较长的对话时提高用户参与度。首先,基于 RL 的助手结束的问题轮次增加了 20%,提示用户选择其他内容。它还可以更好地利用内容多样性,包括事实、声音、测验、是非问题、开放式问题等。平均而言,RL 助手在每次对话中使用的内容提供者比监督模型多 26%。
观察到的两种 RL 规划策略与具有不同特征的子对话的存在有关。关于动物声音的子对话内容较差,并且每次都表现出实体转向(即,在播放给定动物的声音后,我们可以建议不同动物的声音或询问用户有关其他动物的声音)。相比之下,涉及动物事实的子对话通常包含更丰富的内容,并且对话深度更大。我们观察到 RL 更倾向于后者的丰富体验,选择了 31% 以上的事实相关内容。最后,当将分析限制在与事实相关的对话时,RL 助手表现出 60% 以上的焦点转向转折,即改变对话焦点的对话转折。
下面,我们展示了两个示例对话,一个由监督模型进行(左),另一个由 RL 模型进行(右),其中前三个用户轮次是相同的。使用监督对话管理器,在用户拒绝听“今天的动物”后,助手会转回动物声音以最大限度地提高用户的即时满意度。虽然 RL 模型进行的对话开头相同,但它展示了一种不同的规划策略来优化整体用户参与度,引入更多不同的内容,例如趣闻轶事。
在左侧由监督模型进行的对话中,助手最大限度地提高了即时用户满意度。右侧由 RL 模型进行的对话展示了不同的规划策略,以优化整体用户参与度。
未来的研究和挑战
过去几年,经过语言理解和语言生成训练的 LLM 在对话等多项任务中取得了令人瞩目的成绩。我们目前正在探索使用 RL 框架为 LLM 提供动态规划能力,以便它们能够动态地提前规划,并为用户提供更具吸引力的体验。
致谢
所述作品的共同作者包括:Moonkyung Ryu、Yinlam Chow、Orgad Keller、Ido Greenberg、Avinatan Hassidim、Michael Fink、Yossi Matias、Idan Szpektor 和 Gal Elidan。我们要感谢:Roee Aharoni、Moran Ambar、John Anderson、Ido Cohn、Mohammad Ghavamzadeh、Lotem Golany、Ziv Hodak、Adva Levin、Fernando Pereira、Shimi Salant、Shachar Shimoni、Ronit Slyper、Ariel Stolovich、Hagai Taitelbaum、Noam Velan、Avital Zipori 和 Ashwin Kakarla 领导的 CrowdCompute 团队。我们感谢 Sophie Allweis 对这篇博文的反馈以及 Tom Small 提供的可视化。
评论