视频理解是一个具有挑战性的问题,需要推理空间信息(例如,场景中的对象,包括它们的位置和关系)和视频中显示的活动或事件的时间信息。有许多视频理解应用程序和任务,例如理解网络视频的语义内容和机器人感知。然而,当前的研究,如ViViT和TimeSFormer,对视频进行密集处理,需要大量计算,尤其是随着模型大小以及视频长度和分辨率的增加。
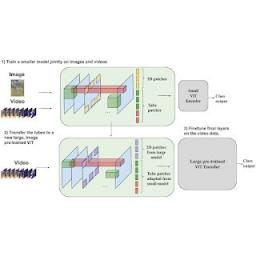
在CVPR 2023上发表的 “重新思考视频 ViT:用于联合图像和视频学习的稀疏视频管”中,我们介绍了一种简单的技术,该技术使用稀疏视频管(视频样本的可学习视觉表示)将Vision Transformer (ViT) 模型图像编码器转变为高效的视频主干,以减少模型的计算需求。这种方法可以无缝处理图像和视频,从而使其能够在训练期间同时利用图像和视频数据源。这种训练进一步使我们的稀疏管 ViT 模型能够将图像和视频主干合并在一起,根据输入的不同,充当图像或视频主干(或两者兼有)的双重角色。我们证明该模型是可扩展的,可以适应大型预训练的 ViT,而无需进行完全微调,并且在许多视频分类基准中取得了最先进的结果。
使用稀疏视频管对视频进行采样,结合标准 ViT 编码器,可实现高效的视觉表现,并可与图像输入无缝共享。
构建联合图像视频主干网
我们的稀疏管 ViT 使用标准 ViT 主干,由一堆Transformer层组成,用于处理视频信息。以前的方法,例如 ViViT,对视频进行密集标记,然后应用因式分解注意力,即,分别针对时间和空间维度计算每个标记的注意力权重。在标准 ViT 架构中,自注意力是在整个标记序列上计算的。当使用视频作为输入时,标记序列会变得非常长,这会使此计算变慢。相反,在我们提出的方法中,使用视频管对视频进行稀疏采样,视频管是来自视频的各种形状和大小的 3D 可学习视觉表示(如下所述)。这些管用于使用大时间步长对视频进行稀疏采样,即,当管核仅应用于视频中的几个位置而不是每个像素时。
通过稀疏地对视频管进行采样,我们可以使用相同的全局自注意力模块,而不是像 ViViT 那样的分解注意力。我们通过实验表明,由于未初始化的权重,添加分解注意力层可能会损害性能。ViT 主干中的这种单一变压器层堆栈还可以更好地共享权重并提高性能。稀疏视频管采样是通过使用较大的空间和时间步长来完成的,该步长在固定网格上选择标记。大步长减少了整个网络中的标记数量,同时仍然捕获空间和时间信息并实现所有标记的有效处理。
稀疏的视频管
视频管是基于 3D 网格的长方体,可以具有不同的形状或类别,并捕获具有可重叠的步幅和起始位置的不同信息。在模型中,我们使用三种不同的管形状来捕获:(1) 仅空间信息(产生一组 2D 图像块)、(2) 长时间信息(在一小块空间区域上)和 (3) 空间和时间信息相等。仅捕获空间信息的管可以应用于图像和视频输入。捕获长时间信息或时间和空间信息相等的管仅适用于视频输入。根据输入视频大小,三种管形状会多次应用于模型以生成标记。
将固定位置嵌入应用于视频管,该嵌入可捕获每个管相对于所有其他管的全局位置(包括任何步幅、偏移等)。与以前学习的位置嵌入不同,这种固定嵌入可以更好地实现稀疏重叠采样。捕获管的全局位置有助于模型了解每个管的来源,这在管重叠或从远处的视频位置采样时尤其有用。接下来,将管特征连接在一起以形成一组N 个标记。这些标记由标准 ViT 编码器处理。最后,我们应用注意力池将所有标记压缩为单个表示并输入到完全连接 (FC) 层以进行分类(例如,踢足球、游泳等)。
我们的视频 ViT 模型通过从视频中采样稀疏视频管(显示在底部)来工作,以便无缝处理图像或视频输入。这些管具有不同的形状并捕获不同的视频特征。管 1(黄色)仅捕获空间信息,从而产生一组可应用于图像输入的 2D 补丁。管 2(红色)捕获时间信息和一些空间信息,管 3(绿色)同样捕获时间和空间信息(即,管x和y的空间大小与帧数t相同)。管 2 和 3 只能应用于视频输入。位置嵌入被添加到所有管特征中。
缩放视频 ViT
构建视频主干的过程需要大量计算,但我们的稀疏管状 ViT 模型能够利用之前训练过的图像主干,以计算效率高效地扩展视频模型。由于图像主干可以适应视频主干,因此大型图像主干可以转变为大型视频主干。更具体地说,人们可以将学习到的视频特征表示从小型管状 ViT 转移到大型预训练图像 ViT,然后仅用几个步骤用视频数据训练生成的模型,而不是从头开始进行完整训练。
我们的方法能够以更高效的方式扩展稀疏管 ViT。具体来说,小型视频 ViT(顶部网络)的视频特征可以转移到大型、预先训练的图像 ViT(底部网络),并进一步微调。这需要更少的训练步骤才能使用大型模型实现强大的性能。这是有益的,因为从头开始训练大型视频模型的成本可能过高。
结果
我们使用Kinetics-400 (如下所示)、Kinetics-600 和 Kinetics-700 数据集 评估了我们的稀疏管 ViT 方法,并将其性能与一系列先前方法进行了比较。我们发现我们的方法优于所有先前方法。重要的是,它优于所有在图像+视频数据集上联合训练的最先进的方法。
与流行的 Kinetics-400 视频数据集上的几项先前研究相比,性能有所提升。我们的稀疏管 ViT 性能优于最先进的方法。
此外,我们在Something-Something V2数据集 上测试了我们的稀疏管 ViT 模型,该数据集通常用于评估更动态的活动,并且还报告其优于所有先前的最先进的方法。
Something-Something V2 视频数据集上的表现。
可视化一些学习到的内核
了解所提出的模型正在学习哪些基本特征是很有趣的。我们在下面将它们可视化,显示了图像和视频共享的 2D 补丁和视频管。这些可视化显示了投影层捕获的 2D 或 3D 信息。例如,在 2D 补丁中,检测到各种常见特征,如边缘和颜色,而 3D 管捕获基本形状以及它们如何随时间变化。
补丁和管的可视化学习了稀疏管 ViT 模型。顶行是 2D 补丁,其余两行是学习的视频管的快照。管显示应用它们的 8 帧或 4 帧的每个补丁。
结论
我们提出了一种新的稀疏管 ViT,它可以将 ViT 编码器转变为高效的视频模型,并且可以无缝处理图像和视频输入。我们还展示了大型视频编码器可以从小型视频编码器和纯图像 ViT 引导。我们的方法在几个流行的视频理解基准测试中优于之前的方法。我们相信,这种简单的表示可以促进更高效的输入视频学习,无缝整合图像或视频输入,并有效消除图像和视频模型的分歧,以实现未来的多模式理解。
致谢
这项工作由 AJ Piergiovanni、Weicheng Kuo 和 Anelia Angelova 完成,他们目前就职于 Google DeepMind。我们感谢 Abhijit Ogale、Luowei Zhou、Claire Cui 以及 Google Research 的同事们提供的有益讨论、评论和支持。
评论