Google 地图中的路线规划仍然是我们最有用和最常用的功能之一。确定从 A 到 B 的最佳路线需要在各种因素之间进行复杂的权衡,包括预计到达时间(ETA)、通行费、直达性、路面状况(例如铺装道路、非铺装道路)和用户偏好,这些因素会因交通方式和当地地理环境的不同而有所差异。通常,我们最自然地了解旅行者偏好的方式是通过分析现实世界的旅行模式。
从观察到的顺序决策行为中学习偏好是逆向强化学习(IRL) 的经典应用。给定一个马尔可夫决策过程(MDP)(道路网络的形式化)和一组演示轨迹(行进路线),IRL 的目标是恢复用户的潜在奖励函数。尽管过去的研究已经创建了越来越通用的 IRL 解决方案,但这些解决方案尚未成功扩展到世界规模的 MDP。扩展 IRL 算法具有挑战性,因为它们通常需要在每个更新步骤中求解 RL 子程序。乍一看,由于路段数量众多且高带宽内存有限,即使尝试将世界规模的 MDP 放入内存中以计算单个梯度步骤似乎也是不可行的。将 IRL 应用于路线时,需要考虑每个演示的出发地和目的地之间的所有合理路线。这意味着任何将世界规模的 MDP 分解为更小组件的尝试都不能考虑小于大都市区的部分。
为此,在“ Google 地图中的大规模可扩展逆向强化学习”中,我们分享了 Google Research、地图和 Google DeepMind 多年合作的成果,以突破 IRL 可扩展性限制。我们重新审视了该领域的经典算法,并介绍了图形压缩和并行化的进展,以及一种称为“后退地平线逆向规划”(RHIP)的新 IRL 算法,该算法可对性能权衡进行细粒度控制。最终的 RHIP 策略实现了 16-24% 的全球路线匹配率相对提升,即与 Google 地图中建议路线完全匹配的去识别行进路线的百分比。据我们所知,这是迄今为止现实世界中最大的 IRL 实例。
当使用 RHIP 逆向强化学习策略时,Google Maps 的路线匹配率相对于现有基线有所提高。
IRL 的好处
关于路由问题的一个微妙但关键的细节是,它是目标条件的,这意味着每个目的地状态都会引发略有不同的 MDP(具体来说,目的地是终端、零奖励状态)。 IRL 方法非常适合这些类型的问题,因为学习到的奖励函数可以在 MDP 之间转移,并且只有目的地状态被修改。这与直接学习策略的方法形成对比,后者通常需要额外的S 个参数因子,其中S是 MDP 状态的数量。
一旦通过 IRL 学习了奖励函数,我们就会利用强大的推理时间技巧。首先,我们在离线批处理设置中对整个图的奖励进行一次评估。此计算完全在服务器上执行,无需访问单个行程,并且仅对图中的一批路段进行操作。然后,我们将结果保存到内存数据库中,并使用快速在线图搜索算法来查找任何出发地和目的地之间路由请求的最高奖励路径。这避免了对深度参数化的模型或策略进行在线推理的需要,并大大改善了服务成本和延迟。
使用批量推理和快速在线规划器奖励模型部署。
后退视野逆向规划
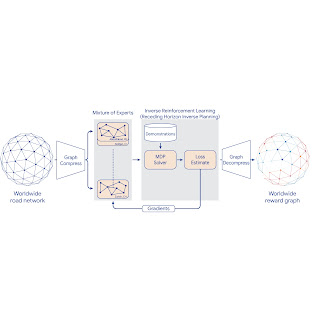
为了将 IRL 扩展到世界 MDP,我们压缩了图表并使用基于地理区域的稀疏混合专家(MoE) 对全局 MDP 进行分片。然后,我们应用经典 IRL 算法来解决局部 MDP、估计损失并将梯度发送回 MoE。通过解压缩最终的 MoE 奖励模型来计算全球奖励图表。为了更好地控制性能特征,我们引入了一种称为“滚动视界逆向规划” (RHIP) 的新广义 IRL 算法。
使用 MoE 并行化、图形压缩和 RHIP 进行 IRL 奖励模型训练。
RHIP 的灵感来源于人们倾向于进行广泛的局部规划(“我接下来一个小时要做什么?”)和近似的长期规划(“我 5 年后的生活会是什么样子?”)。为了利用这一洞察力,RHIP 在演示路径周围的局部区域使用稳健但昂贵的随机策略,并在某个范围之外切换到更便宜的确定性规划器。调整范围H可以控制计算成本,并且通常可以发现性能最佳点。有趣的是,RHIP 概括了许多经典的 IRL 算法,并提供了新颖的洞察力,即它们可以沿着随机与确定性频谱来查看(具体而言,对于H =∞,它简化为MaxEnt,对于H =1,它简化为BIRL,对于H =0,它简化为MMP)。
给定从 s o到 s d的演示,(1) RHIP 在演示周围的局部区域(蓝色区域)遵循稳健但昂贵的随机策略。 (2) 超出某个范围 H 后,RHIP 切换到遵循更便宜的确定性规划器(红线)。调整范围可以实现对性能和计算成本的细粒度控制。
路由获胜
RHIP 策略分别将驾驶和两轮车(例如踏板车、摩托车、轻便摩托车)的全球路线匹配率提升了 15.9% 和 24.1%,与经过良好调整的 Maps 基线相比。我们对可持续交通方式的好处尤其感到兴奋,因为除了行程时间之外,其他因素也发挥着重要作用。通过调整 RHIP 的视野H,我们能够实现比所有其他 IRL 策略更准确且比 MaxEnt 快 70% 的策略。
我们的 360M 参数奖励模型在实时A/B 实验中为 Google Maps 用户提供了直观的胜利。检查学习到的奖励和基线奖励之间绝对差异较大的路段有助于改善某些 Google Maps 路线。例如:
英国诺丁汉。首选路线(蓝色)之前被标记为私有财产,因为那里有一扇大门,这向我们的系统表明这条路可能有时会关闭,对司机来说并不理想。因此,谷歌地图改为引导司机绕行一条更长的替代路线(红色)。然而,由于现实世界的驾驶模式表明用户经常选择首选路线而不会出现问题(因为大门几乎从不关闭),IRL 现在学会通过对这段路段给予较大的正奖励来引导司机沿着首选路线行驶。
结论
通过增加规模来提高性能(无论是在数据集大小还是模型复杂度方面)已被证明是机器学习的一个持续趋势。历史上,逆向强化学习问题一直难以实现类似的提升,这主要是因为处理实际大小的 MDP 存在挑战。通过将可扩展性改进引入经典 IRL 算法,我们现在能够针对具有数亿个状态、演示轨迹和模型参数的问题训练奖励模型。据我们所知,这是迄今为止在现实世界中最大的 IRL 实例。请参阅论文以了解有关这项工作的更多信息。
致谢
这项工作是 Google 多个团队合作的成果。该项目的贡献者包括 Matthew Abueg、Oliver Lange、Matt Deeds、Jason Trader、Denali Molitor、Markus Wulfmeier、Shawn O'Banion、Ryan Epp、Renaud Hartert、Rui Song、Thomas Sharp、Rémi Robert、Zoltan Szego、Beth Luan、Brit Larabee 和 Agnieszka Madurska。
我们还要感谢 Arno Eigenwillig、Jacob Moorman、Jonathan Spencer、Remi Munos、Michael Bloesch 和 Arun Ahuja 的宝贵讨论和建议。
评论