自然语言处理 (NLP) 的目标是开发能够理解和生成自然语言的计算模型。通过捕获基于文本的自然语言的统计模式和结构,语言模型可以预测并生成连贯且有意义的单词序列。得益于大获成功的Transformer模型架构的广泛使用以及对大量文本的训练(计算量和模型大小成比例),大型语言模型 (LLM) 在 NLP 任务中取得了显著的成功。
然而,对口语进行建模仍然是一个具有挑战性的前沿。口语对话系统通常被构建为自动语音识别(ASR)、自然语言理解(NLU)、响应生成和文本转语音(TTS) 系统的级联。然而,到目前为止,很少有能够对口语进行建模的端到端系统:即可以接受语音输入并生成其后续内容作为语音输出的单一模型。
今天,我们介绍了一种新的口语建模方法,称为 Spectron,发表于“使用声谱图驱动的 LLM 进行口语问答和语音延续”。Spectron 是第一个经过端到端训练的口语模型,可直接将声谱图作为输入和输出进行处理,而无需学习离散的语音表示。仅使用预先训练的文本语言模型,就可以对其进行微调以生成高质量、语义准确的口语。此外,所提出的模型在直接初始化的基础上进行了改进,保留了原始 LLM 的知识,如口语问答数据集所示。
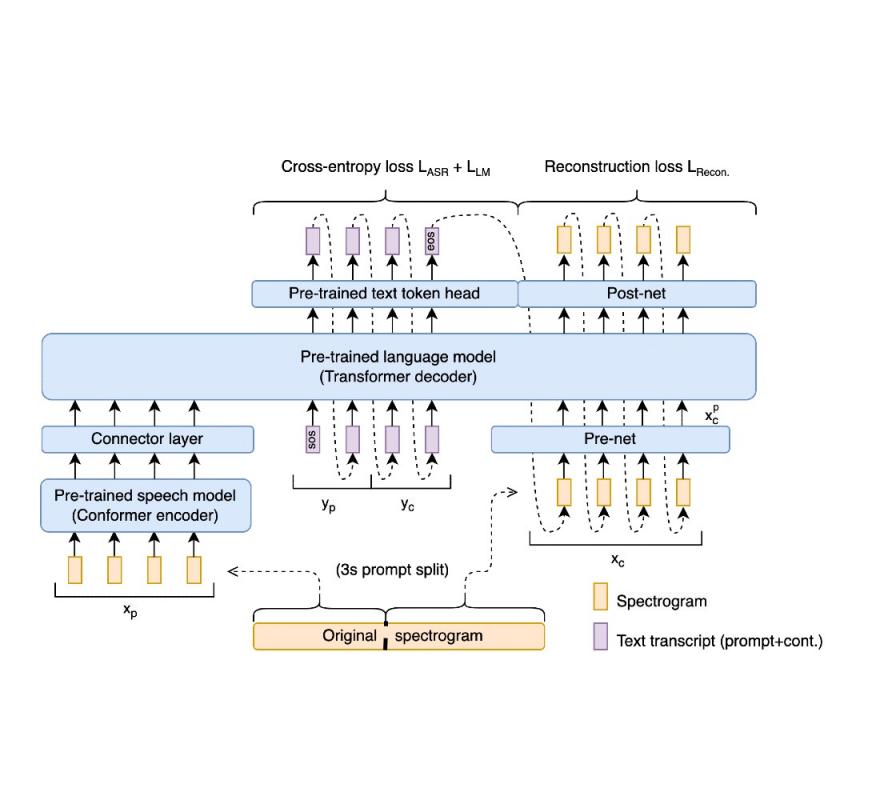
我们表明,预训练的语音编码器和语言模型解码器能够实现端到端训练和最先进的性能,而不会牺牲表征保真度。关键在于一种新颖的端到端训练目标,它以联合方式隐式监督语音识别、文本延续和条件语音合成。新的频谱图回归损失还监督模型以匹配时域和频域中频谱图的高阶导数。这些导数一次表达从多个帧聚合的信息。因此,它们表达了有关信号形状的丰富、更长距离的信息。我们的整体方案总结如下图所示:
Spectron 模型将语音识别模型的编码器与基于 Transformer 的预训练解码器语言模型连接起来。在训练时,语音话语分为提示和其延续。然后重建完整的转录本(提示和延续)以及延续的语音特征。在推理时,仅提供提示;提示的转录、文本延续和语音延续均由模型生成。
Spectron 架构
该架构由预训练的语音编码器和预训练的解码器语言模型初始化。编码器以语音作为输入,将其编码为连续的语言特征。这些特征作为前缀输入到解码器中,整个编码器-解码器经过优化,以共同最小化交叉熵损失(用于语音识别和转录延续)和新的重构损失(用于语音延续)。在推理过程中,提供语音提示,对其进行编码,然后解码以提供文本和语音延续。
语音编码器
语音编码器是一个 600M 参数的一致性编码器,已在大规模数据(12M 小时)上进行预训练。它将源语音的声谱图作为输入,生成一个包含语言和声学信息的隐藏表示。输入声谱图首先使用卷积层进行子采样,然后由一系列一致性块进行处理。每个一致性块由一个前馈层、一个自注意力层、一个卷积层和第二个前馈层组成。输出通过投影层,将隐藏表示与语言模型的嵌入维度进行匹配。
语言模型
我们使用 350M 或 1B 参数解码器语言模型(分别用于延续和问答任务),以PaLM 2的方式进行训练。该模型接收提示的编码特征作为前缀。请注意,这是语音编码器和 LM 解码器之间的唯一连接;即编码器和解码器之间没有交叉注意力。与大多数口语语言模型不同,在训练期间,解码器由老师强制预测文本转录、文本延续和语音嵌入。为了将语音嵌入转换为频谱图或从频谱图转换为语音嵌入,我们在网络前和网络后引入了轻量级模块。
通过让相同的架构解码中间文本和声谱图,我们获得了两个好处。首先,在文本域中对 LM 进行预训练,可以在合成语音之前继续在文本域中提示。其次,预测文本可作为中间推理,提高合成语音的质量,类似于使用中间暂存器或思路链(CoT) 推理时基于文本的语言模型的改进。
声学投影层
为了使语言模型解码器能够对声谱图帧进行建模,我们采用了多层感知器“预网络”将真实声谱图语音连续性投射到语言模型维度。该预网络将声谱图输入压缩到较低维度,从而创建有助于解码过程的瓶颈。这种瓶颈机制可防止模型在解码过程中重复生成相同的预测。为了将 LM 输出从语言模型维度投射到声谱图维度,该模型采用了“后网络”,这也是一个多层感知器。预网络和后网络都是两层的多层感知器。
培训目标
Spectron 的训练方法使用两种不同的损失函数:(i)交叉熵损失,用于语音识别和转录延续;(ii)回归损失,用于语音延续。在训练期间,所有参数都会更新(语音编码器、投影层、LM、预网络和后网络)。
音频样本
为了从经验上评估所提出方法的性能,我们在Libri-Light 数据集上进行了实验。Libri-Light 是一个 60k 小时的英语数据集,包含来自 LibriVox 有声读物的未标记语音读数。我们使用名为WaveFit的冻结神经声码器将预测的声谱图转换为原始音频。我们尝试了两个任务,语音延续和口头问答 (QA)。语音延续质量在 LibriSpeech 测试集上进行测试。口头 QA 在 Spoken WebQuestions 数据集和我们创建的名为 LLama 问题的新测试集上进行测试。对于所有实验,我们使用 3 秒音频提示作为输入。我们将我们的方法与现有的口语语言模型进行了比较:AudioLM、GSLM、TWIST和SpeechGPT。对于语音延续任务,我们使用 350M 参数版本的 LM 和 1B 版本用于口语 QA 任务。
对于语音连续任务,我们使用三个指标来评估我们的方法。第一个指标是对数困惑度,它使用 LM 来评估所生成语音的凝聚力和语义质量。第二个指标是平均意见得分(MOS),它衡量语音在人类评估者看来的自然程度。第三个指标是说话人相似度,它使用说话人编码器来衡量输出中的说话人与输入中的说话人的相似程度。所有 3 个指标的表现可以在下图中看到。
在 3 秒提示下完成 LibriSpeech 话语的对数困惑度。越低越好。
提示语音和使用说话人编码器生成的语音之间的说话人相似度。值越高越好。
人类用户对语音自然度给出的 MOS。评分者对语音自然度进行 5 级主观平均意见分数 (MOS) 评分,范围在 0 - 5 之间。分数越高越好。
从第一张图可以看出,我们的方法在对数困惑度指标上明显优于 GSLM 和 TWIST,并且略优于最先进的方法 AudioLM 和 SpeechGPT。在 MOS 方面,Spectron 的表现超过了除 AudioLM 之外的所有其他方法。在说话人相似度方面,我们的方法优于所有其他方法。
为了评估模型执行问答的能力,我们使用了两个口头问答数据集。第一个是 LLama Questions 数据集,它使用使用 LLama2 70B LLM 生成的不同领域的常识问题。第二个数据集是 WebQuestions数据集,它是一个通用问答数据集。为了进行评估,我们只使用适合 3 秒提示长度的问题。为了计算准确率,答案被转录并与文本形式的标准答案进行比较。
LLama 问题和口语 WebQuestions 数据集上问答的准确率。准确率是使用口语答案的 ASR 记录来计算的。
首先,我们观察到所有方法在回答 Spoken WebQuestions 数据集中的问题时都比在回答 LLama 问题数据集中的问题时更困难。其次,我们观察到以口语建模为中心的方法(如 GSLM、AudioLM 和 TWIST)具有以完成为中心的行为,而不是直接回答问题,这阻碍了它们执行 QA 的能力。在 LLama 问题数据集上,我们的方法优于所有其他方法,而 SpeechGPT 的性能非常接近。在 Spoken WebQuestions 数据集上,我们的方法优于除 SpeechGPT 之外的所有其他方法,而 SpeechGPT 的表现略好一些。
致谢
该项目由 Michelle Tadmor Ramanovich 构思和发起,此外 Eliya Nachmani、Alon Levkovitch、Roy Hirsch ( Verily )、Julian Salazar、Chulayutsh Asawaroengchai、Soroosh Mariooryad、Ehud Rivlin ( Verily ) 和 RJ Skerry-Ryan 也做出了重要贡献。我们还要感谢 Heiga Zhen、Yifan Ding、Yu Zhang、Yuma Koizumi、Neil Zeghidour、Christian Frank、Marco Tagliasacchi、Nadav Bar、Benny Schlesinger 和 Blaise Aguera-Arcas。
评论