聚类是数据挖掘和无监督机器学习中一个基本且普遍存在的问题,其目标是将相似的项目归为一组。聚类的标准形式是度量聚类和图聚类。在度量聚类中,给定的度量空间定义数据点之间的距离,并根据数据点之间的间隔将它们分组。在图聚类中,给定的图通过边连接相似的数据点,聚类过程根据数据点之间的连接将它们分组。这两种聚类形式对于无法定义类标签的大型语料库特别有用。此类语料库的例子是各种互联网平台不断增长的数字文本集合,其应用包括组织和搜索文档、识别文本中的模式以及向用户推荐相关文档(请参阅以下帖子中的更多示例:根据用户意图对相关查询进行聚类和实用的差异隐私聚类)。
文本聚类方法的选择通常会带来一个难题。一种方法是使用嵌入模型(例如BERT或RoBERTa)来定义度量聚类问题。另一种方法是利用交叉注意(CA) 模型(例如PaLM或GPT)来定义图聚类问题。CA 模型可以提供高度准确的相似度分数,但构建输入图可能需要对模型进行二次方的推理调用。另一方面,度量空间可以通过嵌入模型产生的嵌入距离来有效地定义。然而,与 CA 模型的相似度信号相比,这些相似度距离的质量通常要低得多,因此产生的聚类质量可能要低得多。
概述基于嵌入和基于交叉注意的相似度评分函数及其可扩展性与质量困境。
受此启发,在ICLR 2023 上发表的“KwikBucks:使用廉价弱信号和昂贵强信号进行相关聚类”中,我们描述了一种新颖的聚类算法,该算法有效地结合了嵌入模型的可扩展性优势和 CA 模型的质量。这种图聚类算法可以查询 CA 模型和嵌入模型,但是,我们对对 CA 模型的查询数量进行了预算。该算法使用 CA 模型来回答边缘查询,并受益于对嵌入模型的相似度得分的无限制访问。我们描述了这种提议的设置如何将算法设计和实际考虑联系起来,并且可以应用于具有类似可用评分函数的其他聚类问题,例如图像和媒体上的聚类问题。我们展示了该算法如何通过几乎线性数量的对 CA 模型的查询调用来产生高质量的聚类。我们还开源了实验中使用的数据。
聚类算法
KwikBucks 算法是著名的KwikCluster 算法(Pivot 算法)的扩展。其高层思想是首先选择一组彼此之间没有相似性边的文档(即中心),然后围绕这些中心形成聚类。为了获得 CA 模型的质量和嵌入模型的运行效率,我们引入了新颖的组合相似性预言机制。在这种方法中,我们利用嵌入模型来指导要发送到 CA 模型的查询的选择。当给定一组中心文档和一个目标文档时,组合相似性预言机制会从该集合中输出一个与目标文档相似的中心(如果存在)。组合相似性预言通过在选择中心和形成聚类时限制对 CA 模型的查询调用次数,使我们能够节省预算。它通过首先根据中心与目标文档的嵌入相似性对中心进行排名,然后查询 CA 模型以获取该对(即目标文档和排名中心)来实现此目的,如下所示。
对于一组文档和一个目标文档的组合相似性预言机,如果存在则返回该集合中的相似文档。
然后,如果两个簇之间存在强连接,即当连接边的数量高于两个簇之间缺失边的数量时,我们将执行后处理步骤来合并簇。此外,我们应用以下步骤进一步节省对 CA 模型的查询的计算量,并提高运行时的性能:
我们利用查询高效的相关聚类从一组随机选择的文档中形成一组中心,而不是从所有文档中选择这些中心(在下图中,中心节点为红色)。
我们应用组合相似性预言机机制对所有非中心文档并行执行集群分配步骤,并将没有相似中心的文档保留为单例。下图中,分配由蓝色箭头表示,最初两个(非中心)节点由于没有分配而保留为单例。
在后处理步骤中,为了确保可扩展性,我们使用嵌入相似度分数来筛选出潜在的合并(在下图中,绿色虚线边界显示这些合并的集群)。
说明给定图实例上的聚类算法的进展。
结果
我们使用不同的基于嵌入和基于交叉注意的模型,在具有不同属性的各种数据集上评估了这种新型聚类算法。我们将聚类算法的性能与两个性能最佳的基线进行了比较(有关更多详细信息,请参阅论文):
仅访问 CA 的预算聚类的 查询高效相关聚类算法。
通过根据基于嵌入的相似性 查询 CA 模型以获取每个顶点的k 个最近邻,形成k 个最近邻图(kNN)上的谱聚类。
为了评估聚类的质量,我们使用精度和召回率。精度用于计算所有同聚类对中相似对的百分比,而召回率是所有相似对中同聚类的相似对的百分比。为了衡量从实验中获得的解决方案的质量,我们使用F1 分数,它是精度和召回率的调和平均值,其中 1.0 是表示完美的精度和召回率的最高可能值,0 是表示精度或召回率为零的最低可能值。下表报告了在我们只允许对 CA 模型进行线性数量的查询的情况下 Kwikbucks 和各种基线的 F1 分数。我们表明,与所有数据集的平均最佳基线相比,Kwikbucks 的性能大幅提升,相对提高了 45%。
使用各种公共数据集将聚类算法与两种基线算法进行比较:(1)仅访问 CA 的预算聚类的查询高效相关聚类算法,以及(2)通过查询 CA 模型以获得基于嵌入的相似性中每个顶点的k 个最近邻而形成的k-最近邻 (kNN) 图上的谱聚类。预处理数据集可以在此处下载。
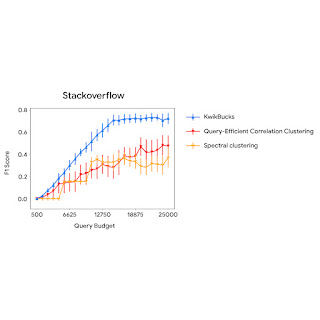
下图比较了使用不同查询预算的聚类算法与基线的性能。我们观察到,KwikBucks 在各种预算下的表现始终优于其他基线。
当允许使用不同的预算来查询交叉注意力模型时,KwikBucks 与前 2 个基线进行比较。
结论
文本聚类在相似度函数的选择上经常会出现两难境地:嵌入模型可扩展但质量欠佳,而交叉注意力模型质量高但可扩展性却大打折扣。我们提出了一种聚类算法,它兼具了两方面的优点:嵌入模型的可扩展性和交叉注意力模型的质量。KwikBucks 还可以应用于具有多个不同准确度水平的相似度预言机的其他聚类问题。通过对具有不同属性的各种数据集进行一系列详尽的实验,可以验证这一点。有关更多详细信息, 请参阅论文。
致谢
该项目是在 Sandeep Silwal 于 2022 年在 Google 暑期实习期间发起的。我们要感谢我们的合著者 Andrew McCallum、Andrew Nystrom、Deepak Ramachandran 和 Sandeep Silwal 对这项工作的宝贵贡献。我们还要感谢 Ravi Kumar 和 John Guilyard 对这篇博文的帮助。
评论