我们提出了一个音乐推荐排名系统,该系统使用 Transformer 模型来根据当前用户上下文更好地理解用户操作的顺序性。
用户在听音乐方面拥有比以往更多的选择。热门服务拥有大量且种类繁多的目录。例如,YouTube Music 目录在全球范围内拥有超过 1 亿首歌曲。因此,项目推荐是这些产品的核心部分。推荐系统可以理解项目目录,并且对于根据用户的品味和需求调整目录至关重要。在提供推荐的产品中,用户对推荐项目的操作(例如跳过、喜欢或不喜欢)提供了有关用户偏好的重要信号。观察和学习这些操作可以带来更好的推荐系统。在YouTube Music中,利用此信号对于了解用户的音乐品味至关重要。
假设用户通常喜欢慢节奏的歌曲。当向用户展示一首快节奏的歌曲时,用户通常会跳过它。然而,在健身房锻炼时,他们更喜欢快节奏的音乐。在这种情况下,我们希望继续从他们之前的历史中学习,以了解他们的音乐偏好。同时,我们希望在推荐锻炼音乐时忽略之前跳过快节奏歌曲的情况。
下面我们展示了用户的音乐聆听体验,歌曲显示为项目,用户的操作显示为下方的文本。在当前不考虑更广泛背景的推荐系统中,我们会预测用户会跳过一首快节奏的歌曲,从而导致一首可能相关且有价值的歌曲被降级。
TransformersMusic1-Journey1final
下图显示了与之前相同的用户旅程,但情况有所不同,其中欢快的音乐可能更相关。我们仍然利用他们之前的音乐收听情况,同时推荐与他们通常的音乐收听情况接近的欢快音乐。实际上,我们正在了解哪些先前的操作与当前对音乐进行排名的任务相关,哪些操作不相关。
TransformersMusic2-Journey2final
典型用户会执行数百个喜欢、不喜欢和跳过操作,而这一系列输入数据虽然信息丰富,但很快就会变得难以处理。为了增加这种复杂性,用户执行的操作数量各不相同。虽然典型用户可能会执行数百个操作,但用户行为可能在少量操作到大量操作之间变化,而良好的排名系统必须能够灵活处理不同大小的输入。
在本文中,我们将讨论如何应用非常适合处理输入数据序列的Transformer来改进 YouTube Music 中的推荐系统。该推荐系统包含三个关键阶段:项目检索、项目排名和过滤。之前的用户操作通常作为输入特征添加到排名模型中。我们的方法改编了生成模型中的 Transformer 架构,以理解用户操作的顺序性,并将其与针对该用户个性化的排名模型相结合。使用 Transformer 根据当前用户上下文合并不同的用户操作有助于将音乐推荐直接引向用户当前的需求。对于已登录用户,这种方法使我们能够合并用户的历史记录,而不必明确识别用户历史记录中哪些内容对排名任务有价值。
检索、排名和过滤
在现有模型中,很难确定哪些用户操作与用户当前需求相关。要理解此类模型,我们需要了解典型的推荐系统。这些系统通常分为三个不同的阶段。首先,检索系统从大型语料库中检索数千个相关项目(文档、歌曲等)。其次,排名系统评估检索到的结果,以便为与用户需求更相关和更重要的项目分配更高的分数。排名的关键复杂性来自相关性、重要性、新颖性等概念之间的价值判断,以及为这些模糊概念分配数值。最后,过滤阶段按分数对排名列表进行排序,并将排序后的列表缩减为显示给用户的简短列表。在设计和部署排名模型时,很难从数百或数千个用户可能采取的常见操作中手动选择并应用相对权重到特定用户操作。
Transformer 理解序列
Transformer非常适合解决需要理解输入数据序列的一类问题。虽然 Transformer 已用于改进排名功能,但以前的方法并未关注用户操作:RankFormer等 Transformer 模型使用项目候选(而不是用户操作)作为输入,BERT 等经典语言 Transformer用于对语言输出进行排名,或 BERT 类模型用于推荐,如Bert4Rec。
Transformer 架构由自注意力层组成,用于理解顺序输入。Transformer 模型在翻译或分类任务上表现出色,即使输入文本有歧义。自注意力层可以捕捉句子中文本单词之间的关系,这表明它们也可能能够解决用户操作之间的关系。Transformer 中的注意力层学习输入片段(token)之间的注意力权重,这类似于输入句子中的单词关系。
TransformerMusic3-Transformer
生成模型中的变压器。
这就是我们如何利用 Transformer 架构对YouTube Music上的用户操作进行编码。在上述涉及快节奏音乐的用户旅程中,我们看到某些操作的重要性不如其他操作。例如,当用户在健身房听音乐时,用户可能更喜欢他们通常会跳过的高能量快节奏音乐,因此相关操作(例如,此示例中的跳过操作)应获得较低的注意力权重。但是,当用户在其他环境中听音乐时,用户操作应该得到更多关注。根据用户正在执行的活动,应用于音乐环境与用户音乐历史的注意力权重应该有所不同。例如,当用户在健身房时,他们可能会听节奏更欢快的音乐,但不会与他们通常听的音乐相差太远。或者当他们开车时,他们可能更喜欢探索更多新音乐。
YouTube 音乐排名的 Transformers
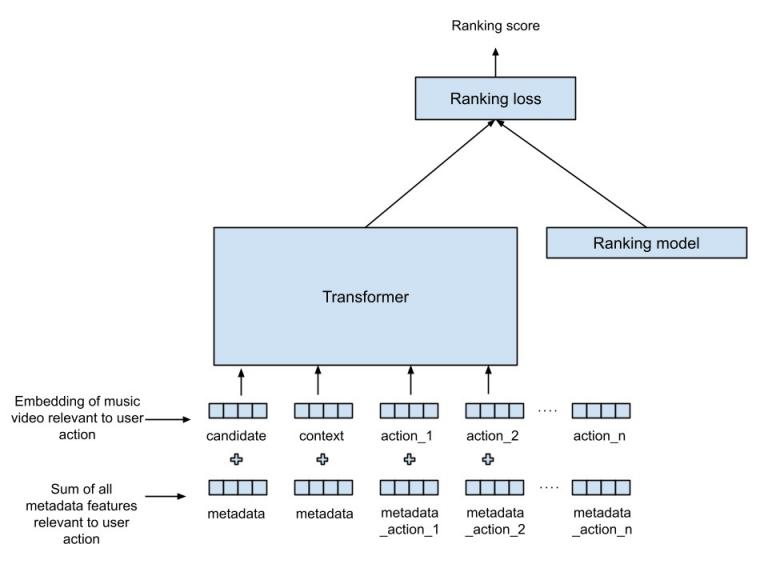
我们的架构将 Transformer 与现有的排名模型相结合,以学习将用户操作与收听历史完美融合的组合排名(见下图)。在此图中,信息从底部流向顶部:Transformer 的输入显示在底部,而生成的排名分数显示在顶部。这里的“项目”是我们想要排名的音乐曲目,目标是为每个提供给它的音乐“项目”生成一个排名分数,并提供其他信号(也称为特征)作为输入。
TransformerMusic4-英雄
Transformers 与 Ranker 在联合音乐推荐任务中的应用。
以下是描述每个时间步骤的用户操作的信号:
动作意图:中断音乐曲目、选择要收听的音乐曲目、自动播放。
动作的显著性:已播放音乐曲目的百分比,自上次用户动作以来的时间。
其他元数据:艺术家、音乐语言。
音乐曲目:与用户动作对应的音乐曲目标识符。
与用户操作相对应的音乐曲目由称为曲目嵌入的数字向量表示。此音乐曲目嵌入用作 Transformer 和现有排名模型的输入。用户操作信号(如意图和元数据)被转换为与曲目嵌入长度相同的向量。此操作称为投影,它允许我们通过添加两个向量(用户操作信号和曲目嵌入)来组合信号,从而为 Transformer 生成输入向量(称为标记)。作为 Transformer 输入提供的标记用于对检索到的音乐项目进行评分。在考虑用户的历史记录时,我们会包括之前的用户操作和用户当前正在听的音乐,因为两者都捕捉到了有价值的用户上下文。使用多层神经网络将 Transformer 的输出向量与现有排名模型输入相结合。Transformer 与排名模型共同训练,以实现多个排名目标。
离线分析和现场实验表明,使用此 Transformer 可显著提高排名模型的性能,从而降低跳过率并增加用户听音乐的时间。跳过频率降低表明用户平均更喜欢推荐。会话长度增加表明用户对整体体验更满意。这两个指标表明 YouTube Music 的用户满意度有所提高。
未来工作
我们认为,这项工作有两个主要的发展机会。第一个机会是将该技术应用于推荐系统的其他部分,例如检索模型。此外,我们还在探索将各种非序列特征纳入其中,这些特征可用作先前排名模型的输入。目前,这些特征在 Transformer 阶段之后合并,我们预测,将它们纳入 Transformer 中将能够提高序列特征(如用户操作)和非序列特征(如艺术家受欢迎程度、用户语言、音乐受欢迎程度等)之间的自注意力。
致谢
感谢同事 Reza Mirghaderi、Li Yang、Chieh Lo、Jungkhun Byun、Gergo Varady 和 Sally Goldman 对此项工作的合作。
评论