现实世界中的机器学习模型通常是在有限的数据上进行训练的,这些数据可能包含意想不到的统计偏差。例如,在CELEBA名人图像数据集中,金发女名人的数量不成比例,导致分类器错误地将“金发”预测为大多数女性面孔的头发颜色——在这里,性别是预测头发颜色的虚假特征。这种不公平的偏见可能会对医疗诊断等关键应用产生重大后果。
令人惊讶的是,最近的研究还发现了深度网络的固有倾向,即通过所谓的深度学习简单性偏差来放大这种统计偏差。这种偏差是指深度网络倾向于在训练早期识别弱预测特征,并继续锚定这些特征,而无法识别更复杂且可能更准确的特征。
考虑到上述情况,我们提出了通过应用早期读出和特征遗忘来简单有效地解决虚假特征和简单性偏差这一双重挑战的办法。首先,在“使用早期读出调解蒸馏中的特征偏差”中,我们表明,从深度网络的早期层(称为“早期读出”)进行预测可以自动发出与学习到的表示的质量有关的信号。具体来说,当网络依赖于虚假特征时,这些预测更容易出错,而且错误的可能性更大。我们利用这种错误的信心来改善模型蒸馏的结果,模型蒸馏是一种使用较大的“老师”模型指导较小的“学生”模型训练的设置。然后在“使用特征筛选器克服深度网络中的简单性偏差”中,我们通过让网络“忘记”有问题的特征并从而寻找更好、更具预测性的特征来直接干预这些指示信号。与之前的方法相比,这大大提高了模型推广到未知领域的能力。我们的AI 原则和负责任的 AI 实践指导我们如何研究和开发这些高级应用程序,并帮助我们应对统计偏差带来的挑战。
动画比较了使用和不使用特征筛选训练的两个模型的假设响应。
消除蒸馏偏差的早期读数
我们首先说明早期读数 的诊断价值及其在去偏蒸馏中的应用,即确保学生模型通过蒸馏继承教师模型对特征偏差的适应性。我们从标准的蒸馏框架开始,其中学生通过标签匹配(最小化学生输出和真实标签之间的交叉熵损失)和教师匹配(最小化任何给定输入的学生和教师输出之间的KL 散度损失)的混合进行训练。
假设有人在学生模型的中间表示之上训练一个线性解码器,即一个名为Aux的小型辅助神经网络。我们将此线性解码器的输出称为网络表示的早期读数。我们发现,早期读数在包含虚假特征的实例上会犯更多错误,而且这些错误的置信度高于与其他错误相关的置信度。这表明,早期读数的误差置信度是模型对潜在虚假特征依赖性的一个相当强的自动化指标。
说明早期读数(即辅助层的输出)在去偏蒸馏中的使用情况。在早期读数中被准确预测错误的实例在蒸馏损失中被加权。
我们利用这个信号来调节教师在蒸馏损失中的贡献,结果发现训练后的学生模型有显著的改善。
我们在已知包含虚假相关的标准基准数据集(Waterbirds、CelebA、CivilComments、MNLI)上评估了我们的方法。每个数据集都包含数据分组,这些数据分组共享一个可能与标签以虚假方式相关的属性。例如,上面提到的 CelebA 数据集包括{金发男性、金发女性、非金发男性、非金发女性} 等组,而模型在预测头发颜色时通常在{非金发女性} 组上表现最差。因此,衡量模型性能的一个标准是其最差组准确率,即数据集中所有已知组中的最低准确率。我们在所有数据集上提高了学生模型的最差组准确率;此外,我们还提高了四个数据集中的三个的整体准确率,这表明我们对任何一个组的改进都不会以牺牲其他组的准确率为代价。更多细节请参阅我们的论文。
不同蒸馏技术与 Teacher 模型的最差组准确率比较。我们的方法在所有数据集上都优于其他方法。
使用特征筛选克服简单性偏见
在第二个密切相关的项目中,我们直接干预早期读数提供的信息,以改进特征学习和泛化。工作流程在识别有问题的特征和从网络中删除已识别的特征之间交替进行。我们的主要假设是早期特征更容易出现简单性偏差,通过删除(“筛选”)这些特征,我们可以学习更丰富的特征表示。
使用特征筛选进行训练的工作流程。我们交替进行识别问题特征(使用训练迭代)和从网络中删除它们(使用遗忘迭代)。
我们更详细地描述了识别和删除步骤:
识别简单特征:我们通过前向和反向传播以常规方式训练主模型和读出模型(上面的 AUX)。请注意,辅助层的反馈不会反向传播到主网络。这是为了迫使辅助层从已有的特征中学习,而不是在主网络中创建或强化它们。
应用特征筛选:我们的目标是利用一种新的遗忘损失L f来消除神经网络早期层中已识别的特征,该损失只是读数与标签上均匀分布之间的交叉熵。本质上,导致非平凡读数的所有信息都会从主网络中删除。在此步骤中,辅助网络和主网络的上层保持不变。
我们可以通过少量配置参数来具体控制特征筛选如何应用于给定数据集。通过改变辅助网络的位置和复杂性,我们可以控制已识别和已擦除特征的复杂性。通过修改学习和遗忘步骤的混合,我们可以控制模型学习更复杂特征的挑战程度。这些选择取决于数据集,是通过超参数搜索做出的,以最大化验证准确率,这是泛化的标准衡量标准。由于我们在搜索空间中包含了“不遗忘”(即基线模型),因此我们希望找到至少与基线一样好的设置。
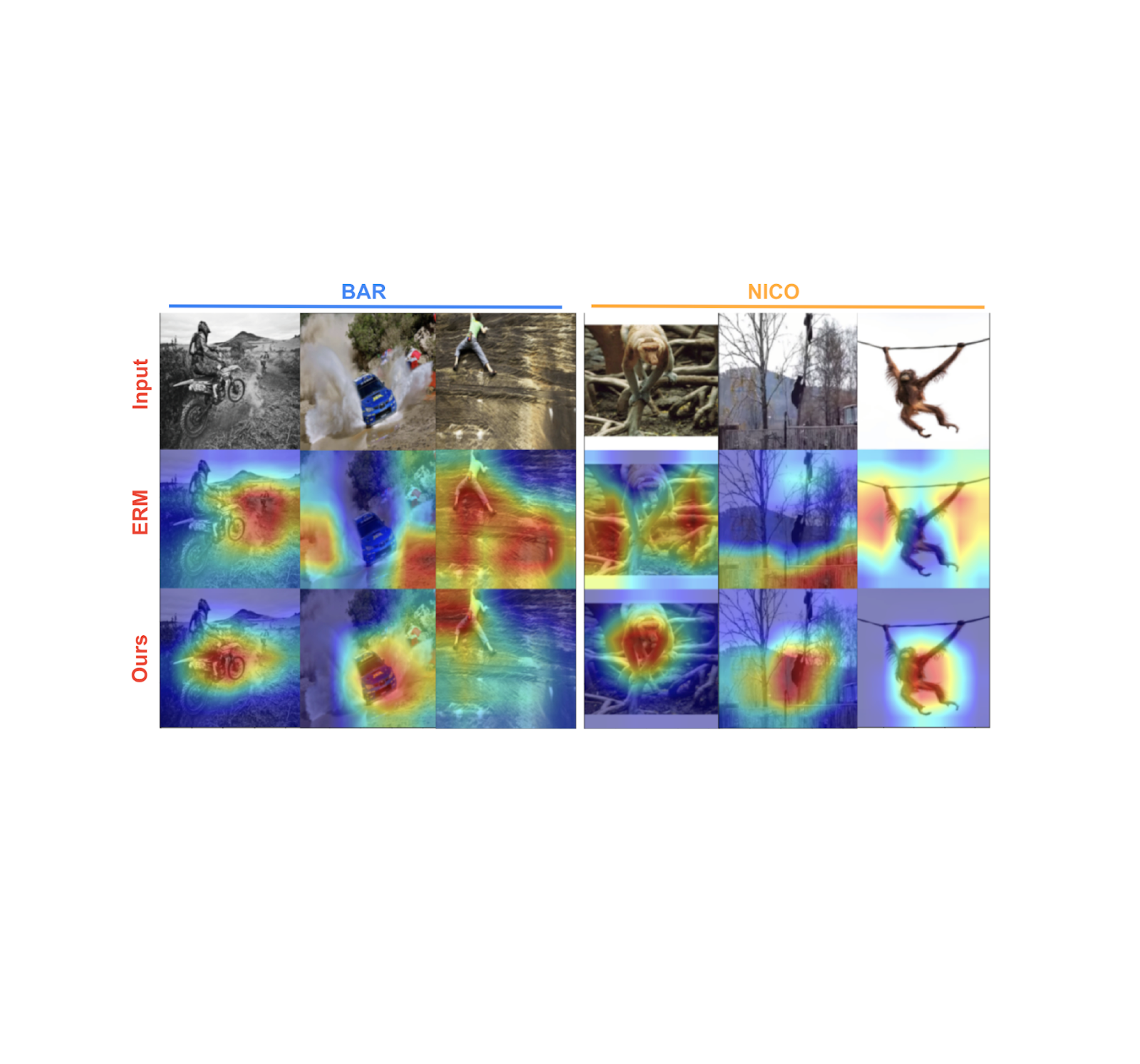
下面我们展示了基线模型(中间一行)和我们的模型(底行)在两个基准数据集(有偏活动识别 ( BAR ) 和动物分类 ( NICO ))上学习到的特征。特征重要性使用事后梯度重要性评分 ( GRAD-CAM ) 进行估计,光谱的橙红色端表示重要性高,而绿蓝色端表示重要性低。如下所示,我们训练的模型专注于主要感兴趣的对象,而基线模型倾向于关注更简单且与标签虚假相关的背景特征。
使用 GRAD-CAM 在活动识别 (BAR) 和动物分类 (NICO) 泛化基准上对特征重要性进行评分。我们的方法(最后一行)侧重于图像中的相关对象,而基线(ERM;中间行)依赖于与标签虚假相关的背景特征。
通过这种学习更好、更通用的特征的能力,我们在现实世界的虚假特征基准数据集上显示出一系列相关基线的显著提升:BAR、CelebA Hair、NICO和ImagenetA,幅度高达 11%(见下图)。更多详细信息请参阅我们的论文。
对于一系列特征泛化基准数据集,我们的特征筛选方法相对于最近的基线显著提高了准确度。
结论
我们希望我们在早期读数方面的工作及其在特征筛选以进行泛化方面的应用,既能促进新一类对抗性特征学习方法的发展,又有助于提高深度学习系统的泛化能力和鲁棒性。
致谢
将早期读数应用于去偏蒸馏的工作是与我们的学术合作伙伴 Durga Sivasubramanian、Anmol Reddy 和孟买印度理工学院的 Ganesh Ramakrishnan 教授合作进行的。我们衷心感谢 Praneeth Netrapalli 和 Anshul Nasery 的反馈和建议。我们还感谢 Nishant Jain、Shreyas Havaldar、Rachit Bansal、Kartikeya Badola、Amandeep Kaur 以及 Google 印度研究院的全体博士前研究员参与研究讨论。特别感谢 Tom Small 制作了本文中使用的动画。
评论