引入一个通用的以用户为中心的界面,帮助放射科医生利用机器学习模型进行肺癌筛查。该系统以计算机断层扫描 (CT) 成像作为输入,并输出癌症疑似评级以及相应的感兴趣区域。
肺癌是全球癌症相关死亡的主要原因, 2020 年报告的死亡人数为 180 万人。诊断过晚会大大降低存活率。通过计算机断层扫描(CT) 进行肺癌筛查,可以提供肺部的详细 3D 图像,研究表明,通过及早发现潜在的癌症迹象,可将高危人群的死亡率降低至少 20%。在美国,筛查需要每年进行一次扫描,但有些国家或案例建议扫描频率更高或更低。
美国预防服务工作组最近将肺癌筛查建议扩大了约 80%,这有望增加女性和种族及少数民族群体的筛查机会。然而,假阳性(即错误地报告无癌症患者患有潜在癌症)可能会引起焦虑,并导致患者接受不必要的检查,同时增加医疗保健系统的成本。此外,筛查大量个体的效率可能具有挑战性,这取决于医疗保健基础设施和放射科医生的可用性。
在 Google,我们之前开发过用于肺癌检测的机器学习 (ML) 模型,并评估了它们自动检测和分类显示潜在癌症迹象的区域的能力。事实证明,它们在检测潜在癌症方面的表现堪比专家。虽然它们的表现很出色,但要在现实环境中有效地传达发现结果,就必须充分发挥它们的潜力。
为此,在《放射学人工智能》杂志发表的《肺癌筛查中的辅助人工智能:美国和日本的一项回顾性跨国研究》中,我们研究了机器学习模型如何有效地将研究结果传达给放射科医生。我们还引入了一个可通用的以用户为中心的界面,帮助放射科医生利用此类模型进行肺癌筛查。该系统以 CT 影像作为输入,并使用四个类别(无怀疑、可能良性、可疑、高度可疑)以及相应的感兴趣区域输出癌症怀疑评级。我们通过美国和日本的随机读者研究评估了该系统在提高临床医生表现方面的效用,使用当地癌症评分系统(Lung-RADSs V1.1和仙台评分)和模拟现实环境的图像查看器。我们发现,在两项读者研究中,读者的特异性都会随着模型的辅助而增加。为了加快使用机器学习模型进行类似研究的进展,我们提供了开源代码来处理 CT 图像并生成与放射科医生使用的图像归档和通信系统(PACS)兼容的图像。
开发界面来传达模型结果
将 ML 模型集成到放射科医生的工作流程中需要了解其任务的细微差别和目标,以便为其提供有意义的支持。在肺癌筛查方面,医院遵循定期更新的各个国家/地区指南。例如,在美国,Lung-RADs V1.1 会分配一个字母数字分数来指示肺癌风险和后续建议。在评估患者时,放射科医生将 CT 加载到他们的工作站中以阅读病例,查找肺结节或病变,并应用既定的指南来确定后续决策。
我们的第一步是通过额外的训练数据和架构改进(包括自注意力)来改进之前开发的 ML 模型。然后,我们不再针对特定的指南,而是尝试了一种独立于指南或其特定版本的互补方式来传达 AI 结果。具体来说,系统输出提供了怀疑评级和定位(感兴趣区域),供用户结合他们自己的特定指南进行考虑。界面生成与 CT 研究直接相关的输出图像,无需对用户的工作站进行任何更改。放射科医生只需查看一小部分额外的图像。他们的系统或与系统的交互无需进行其他更改。
计算机辅助诊断-1
辅助肺癌筛查系统输出示例。放射科医生的评估结果在发现可疑病变的 CT 体积位置上可视化。总体怀疑程度显示在 CT 图像的顶部。圆圈突出显示可疑病变,而方块显示从不同角度呈现的同一病变,称为矢状图。
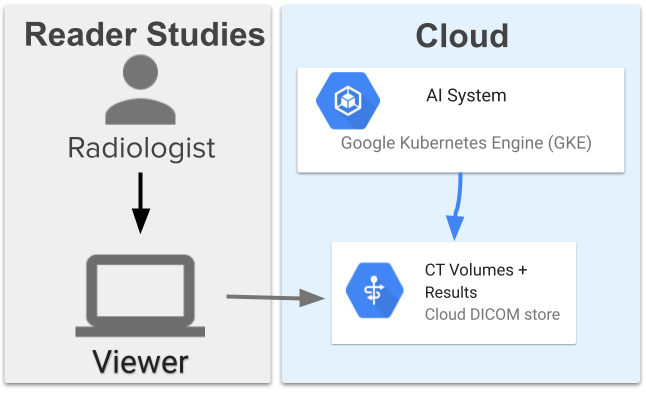
辅助肺癌筛查系统包含 13 个模型,其高级架构与之前工作中使用的端到端系统类似。这些模型相互协调,首先分割肺部,获得整体评估,找到三个可疑区域,然后使用这些信息为每个区域分配可疑等级。该系统部署在 Google Cloud 上,使用Google Kubernetes Engine (GKE) 提取图像、运行 ML 模型并提供结果。这允许可扩展性并直接连接到将图像存储在DICOM 存储中的服务器。
计算机辅助诊断-4
辅助肺癌筛查系统的 Google Cloud 部署概述以及提供图像和计算结果的各个组件的定向调用流程。使用 Google Cloud 服务将图像提供给查看器和系统。该系统在 Google Kubernetes Engine 上运行,该引擎会提取图像、对其进行处理并将其写回到 DICOM 存储中。
读者研究
为了评估该系统在改善临床表现方面的效用,我们与 12 位放射科医生进行了两项读者研究(即旨在评估临床表现的实验,比较在有和没有技术帮助下的专家表现),使用预先存在的、去识别的 CT 扫描。我们向 6 位美国放射科医生和 6 位日本放射科医生展示了 627 个具有挑战性的病例。在实验设置中,读者被分成两组,每个病例阅读两次,有和没有模型的帮助。要求读者应用他们在临床实践中通常使用的评分指南,并报告他们对每个病例的总体癌症怀疑程度。然后,我们比较了读者的回答结果,以衡量模型对他们的工作流程和决策的影响。根据个体的实际癌症结果来判断分数和怀疑程度,以测量灵敏度、特异性和ROC 曲线下面积(AUC) 值。在有和没有帮助的情况下对这些进行了比较。
计算机辅助诊断-3
在多案例多读者研究中,每个读者对每个案例进行两次审阅,一次是在 ML 系统的帮助下,一次是在没有帮助的情况下。在这个可视化中,一位读者首先在没有帮助的情况下审阅 A 组(蓝色),然后在洗脱期后在帮助下审阅(橙色)。第二个读者组遵循相反的路径,首先在帮助下阅读同一组案例 A 组。读者被随机分配到这些组以消除排序的影响。
使用相同界面开展这些研究的能力凸显了其对完全不同的癌症评分系统的通用性,以及模型和辅助能力对不同患者群体的推广。我们的研究结果表明,当放射科医生在临床评估中使用该系统时,与不使用辅助系统相比,他们正确识别没有可操作的肺癌发现的肺部图像的能力(即特异性)提高了 5-7%。这可能意味着每筛查 15-20 名患者,就有一名能够避免不必要的后续程序,从而减轻他们的焦虑和医疗保健系统的负担。这反过来可以帮助提高肺癌筛查计划的可持续性,特别是随着越来越多的人有资格接受筛查。
计算机辅助诊断-2
在美国和日本的读者研究中,随着 ML 模型的帮助,读者特异性有所提高。特异性值来自读者对可操作发现(发现可疑情况)与无可操作发现的评分,并与个人的真实癌症结果进行比较。在模型的帮助下,读者标记的癌症阴性个体更少,需要进行随访。对癌症阳性个体的敏感性保持不变。
通过合作将其转化为现实影响
该系统结果表明,可以减少随访次数、减轻焦虑并降低肺癌筛查的总体成本。为了将这项研究转化为现实世界的临床影响,我们正在与领先的 AI 驱动的健康信息学提供商DeepHealth和印度领先的放射学服务提供商Apollo Radiology International合作,探索将该系统整合到未来产品的途径。此外,我们希望通过开源代码用于读者研究并结合本博客中描述的见解,帮助其他研究人员研究如何将 ML 模型结果最好地整合到临床工作流程中。我们希望这将有助于加速医学成像研究人员为他们的 AI 模型开展读者研究,并催化该领域的转化研究。
致谢
该项目的主要贡献者包括 Corbin Cunningham、Zaid Nabulsi、Ryan Najafi、Jie Yang、Charles Lau、Joseph R. Ledsam、Wenxing Ye、Diego Ardila、Scott M. McKinney、Rory Pilgrim、Hiroaki Saito、Yasuteru Shimamura、Mozziyar Etemadi、Yun Liu、David Melnick、Sunny Jansen、Nadia Harhen、David P. Nadich、Mikhail Fomitchev、Ziyad Helali、Shabir Adeel、Greg S. Corrado、Lily Peng、Daniel Tse、Shravya Shetty、Shruthi Prabhakara、Neeral Beladia 和 Krish Eswaran。感谢 Arnav Agharwal 和 Andrew Sellergren 的开源支持,以及 Vivek Natarajan 和 Michael D. Howell 的反馈。我们还要向在整个研究过程中通过图像解释和注释使这项工作得以进行的放射科医生以及协调读者研究的 Jonny Wong 和 Carli Sampson 表示诚挚的感谢。
评论