 人机交互是一种统一的方法,它使用自我中心视觉、多模态感知和 LLM 推理来检测情境障碍并评估用户在特定情况下用手、视觉、听觉或言语交互的能力。
人机交互是一种统一的方法,它使用自我中心视觉、多模态感知和 LLM 推理来检测情境障碍并评估用户在特定情况下用手、视觉、听觉或言语交互的能力。
每天,我们都会遇到暂时的挑战,这些挑战会影响我们应对不同情况的能力。这些挑战被称为情境诱发的损伤和残疾(SIID),可能由各种环境因素引起,如噪音、灯光、温度、压力,甚至社会规范。例如,想象一下你在一家喧闹的餐厅里,你错过了一个重要的电话,因为你根本听不到电话铃声。或者想象一下你在洗碗时试图回复短信;你的湿手和手头的任务让你很难打字回复。这些日常场景表明,我们的周围环境会暂时降低我们的身体、认知或情感能力,导致令人沮丧的经历。
此外,情境障碍可能千差万别且频繁变化,因此很难应用一刀切的解决方案来实时满足用户的需求。例如,想象一下一个典型的早晨例行程序:刷牙时,有人可能无法使用语音命令控制智能设备。洗脸时,可能很难看到和回复重要的短信。使用吹风机时,可能很难听到任何电话通知。尽管各种努力已经为这些特定情况量身定制了解决方案,但为每种可能的情况和挑战组合创建手动解决方案并不实际可行,而且在大规模上效果不佳。
在获得CHI 2024最佳论文荣誉奖的“人类输入/输出:迈向检测情境障碍的统一方法”中,我们介绍了一种用于检测 SIID 的可推广和可扩展的框架。人类输入/输出 (Human I/O) 不是为洗脸、刷牙或吹干头发等活动设计单独的模型,而是普遍评估用户的视觉(例如,阅读短信、观看视频)、听觉(例如,听取通知、电话)、声音(例如,进行对话、使用 Google 助理)和手(例如,使用触摸屏、手势控制)输入/输出交互通道的可用性。我们描述了 Human I/O 如何利用自我中心视觉、多模态感知和大型语言模型 (LLM) 推理,在 32 种不同场景的 60 个野外自我中心视频录制中实现 82% 的可用性预测准确率,并在一项有 10 名参与者的实验室研究中将其验证为交互式系统。我们还开放了代码。
Human-I:O-图1
利用多模态人工智能和大型语言模型,我们构建了一条管道来计算模拟这些人类输入/输出通道,并实现了良好的实时性能。
形成性研究
在开发 Human I/O 之前,我们进行了一项涉及 10 名参与者的形成性研究,以更好地了解不同的障碍如何影响他们与技术的互动。我们的研究结果强调,需要一个能够动态适应不同级别通道可用性的系统,而不是将可用性视为二元状态。具体而言,Human I/O 区分了四个级别的通道可用性,这对于了解用户与其设备的互动程度至关重要。这些级别包括:
可用的
该通道目前不参与任何活动,也不受任何环境因素的制约。使用该通道完成新任务所需的努力很少甚至为零。
示例:用户坐在桌前,双手空闲,眼睛没有专注于任务,也没有背景噪音干扰他们的听力或说话。
轻微影响
该通道参与某项活动或受到环境因素的限制。当有新任务需要该通道时,用户可以同时执行多项任务,轻松暂停和恢复当前活动,或轻松克服困境。
示例:用户正在拿着遥控器,可以将其放在一边以腾出手来执行其他任务。
做作的
该渠道参与某项活动或受到环境因素的限制。对于新任务,用户可能会感到不便或需要付出一些努力才能使用该渠道。
示例:用户用双手搬运杂货,如果不先放下袋子,就很难用手做其他事情。
不可用
由于活动或环境因素导致通道完全不可用,并且用户无法在没有进行实质性更改、重大调整或改变环境的情况下将其用于新任务。
示例:用户正在参加一场喧闹的音乐会,这导致他们无法听到传入的通知或进行对话。
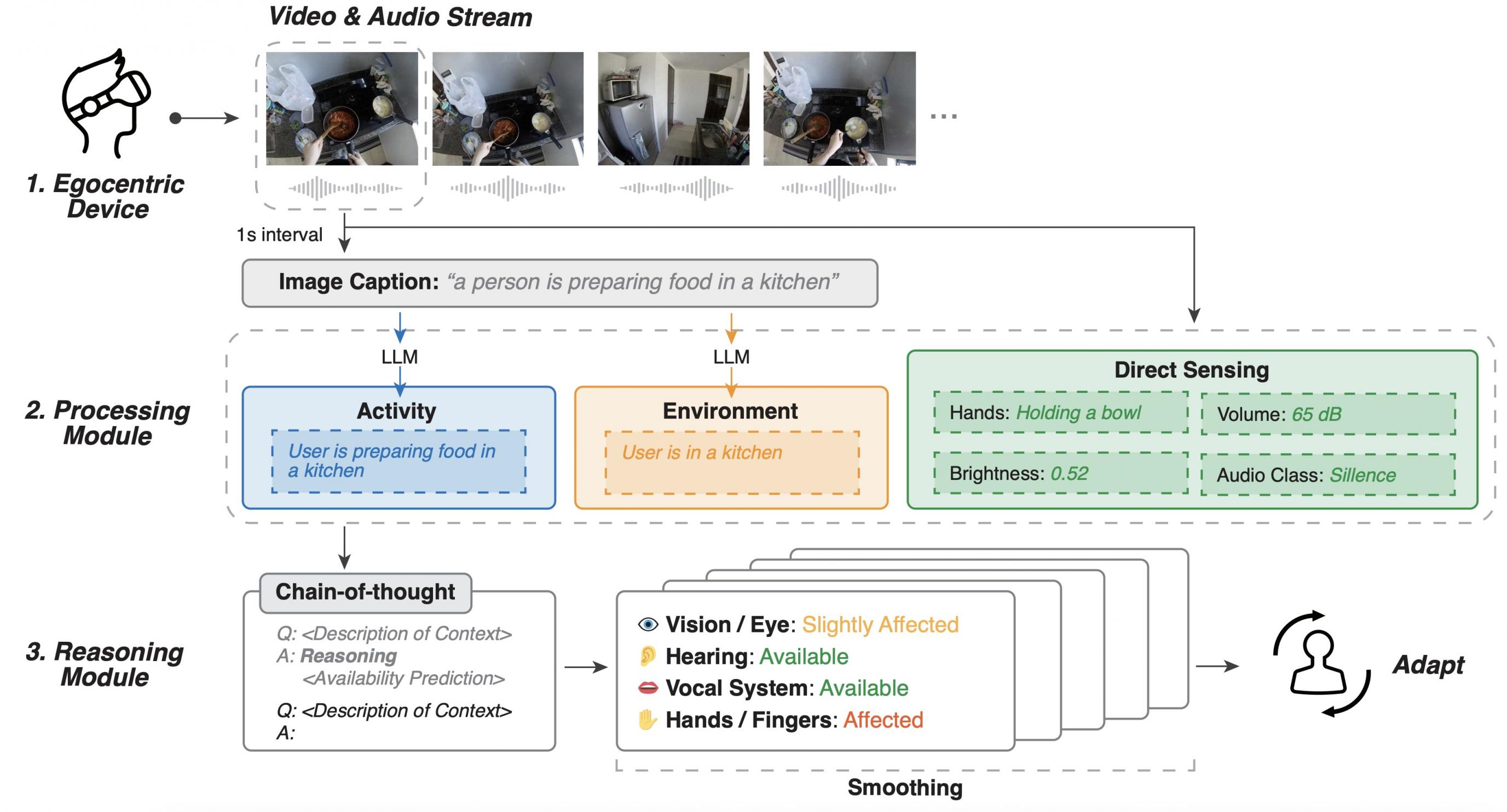
人类 I/O 系统管道
Human I/O 系统集成了一个管道,该管道可传输实时数据、处理数据以了解上下文,并使用 LLM 进行推理以预测通道可用性。下面深入了解该系统的三个核心组件:数据流、处理模块和推理模块。
数据流
该系统首先通过一个带有摄像头和麦克风的自我中心设备传输实时视频和音频数据。此设置提供了用户环境的第一人称视角,捕捉评估环境所需的视觉和听觉细节。
处理模块
该模块处理原始数据以提取以下信息:
活动识别:利用计算机视觉来识别用户当前的活动,例如做饭或洗碗。
环境评估:使用音频和视觉数据确定设置,例如嘈杂或安静的环境。
直接感应:检测更精细的细节,例如用户的手是否被占用、环境噪音水平和照明条件。
推理模块
最后阶段涉及分析来自处理模块的结构化数据,使用具有思路链推理的LLM 预测输入/输出通道的可用性。该模块处理上下文信息并确定每个通道的受损程度,从而指导设备如何相应地调整其交互。通过集成数据流、处理和推理,Human I/O 可以动态预测用户输入和输出通道的可用性。我们还采用了平滑算法来增强系统稳定性。
Human-I:O-图 2
人机 I/O 管道由一个以自我为中心的设备、获取活动、环境和传感器数据的处理模块以及预测人类通道可用性的推理模块组成。
评估
为了验证 Human I/O,我们从 60 个野外以自我为中心的视频录制中选取了 300 个剪辑,并进行了评估。该系统在预测频道可用性方面的平均绝对误差(MAE) 为 0.22,准确率为 82%,其中 96% 的预测与实际可用性水平相差无几。这些较低的 MAE 值表明,我们系统的预测与实际可用性非常吻合,平均偏差不到实际水平的三分之一。
此外,我们通过引入 Human I/O Lite 进行了一项消融研究,该模型用一次性提示取代了思路链推理模块。对于 Human I/O Lite,我们观察到其整体性能略逊于完整模型。然而,Human I/O Lite 的 MAE 仍然处于较低水平,约为 0.44,表明即使在计算资源减少的情况下,它也能很好地预测 SIID。
Human-I:O-图 3
Human I/O 和 Human I/O Lite 的技术评估。我们报告了四个通道的 MAE、 平均分类准确度(ACC) 和 平均视频内方差(VAR) 以及总体结果。我们的系统以较小的误差和方差估计可用性水平。在 Human I/O 中,96.0% 的预测与实际可用性值的差异在 1 步以内。
此外,一项有十名参与者的用户研究表明,在存在 SIID 的情况下,Human I/O 显著减少了工作量并增强了用户体验。参与者特别看重系统如何适应他们的实时环境,使数字交互更加无缝且干扰更少。参与者完成了NASA 任务负荷指数问卷,以 7 分制(从 1 最低到 7 最高)评估了心理需求、身体需求、时间需求、总体表现、工作量和挫折程度。结果表明,在存在 SIID 的情况下,Human I/O 显著减少了工作量并改善了用户体验。此外,Human I/O 用户报告称,他们对 SIID 的认识有所提高,这开辟了新的交互可能性。
Human-I:O-图 4
参与者对任务负荷指数问题的评分(从 1 低到 7 高),以了解他们在用户研究中使用带有和不带有人工 I/O 的 SIID 的经验。通过 Wilcoxon 符号秩检验,所有评分差异均具有统计学意义,𝑝 < 0.001 。
结论与未来工作
人机 I/O 代表着我们以情境感知和自适应方式与技术交互的能力的飞跃。通过理解和预测输入和输出通道的可用性,它为更智能、更直观的用户界面铺平了道路,无论人们面临何种情境挑战,都可以提高每个人的生产力和可访问性。
同时,在可穿戴设备上设计和部署带有主动摄像头和麦克风的 SIID 系统时,维护隐私和遵守道德标准至关重要。例如,结合设备上的推理(例如Gemini Nano)和联合学习可以防止潜在的数据泄露。未来的研究可能会采用更多的传感技术,例如深度感应、超宽带和眼动追踪,以便为用户提供更精细的控制,让他们的设备能够适应不断变化的需求和情况。
我们设想这项技术不仅可以改善单个设备的交互,还可以为未来普适计算的发展奠定基础。
视频预览图像
观看影片
致谢
本研究主要由 Xingyu Bruce Liu、Jiahao Nick Li、David Kim、Xiang 'Anthony' Chen 和 Ruofei Du 完成。我们还要感谢 Guru Somadder、Adarsh Kowdle、Siyou Pei、Xiuxiu Yuan、Alex Olwal、Eric Turner 和 Federico Tombari 为本文手稿和博客文章提供的反馈或帮助。
评论