 我们发布了 MISeD(会议信息搜索对话)数据集,其中包含专注于会议记录的信息搜索对话以及相应的基线模型。MISeD 采用半自动方法生成,其中对话轮次由 LLM 生成,然后由人工验证,人工还提供归因跨度。
我们发布了 MISeD(会议信息搜索对话)数据集,其中包含专注于会议记录的信息搜索对话以及相应的基线模型。MISeD 采用半自动方法生成,其中对话轮次由 LLM 生成,然后由人工验证,人工还提供归因跨度。
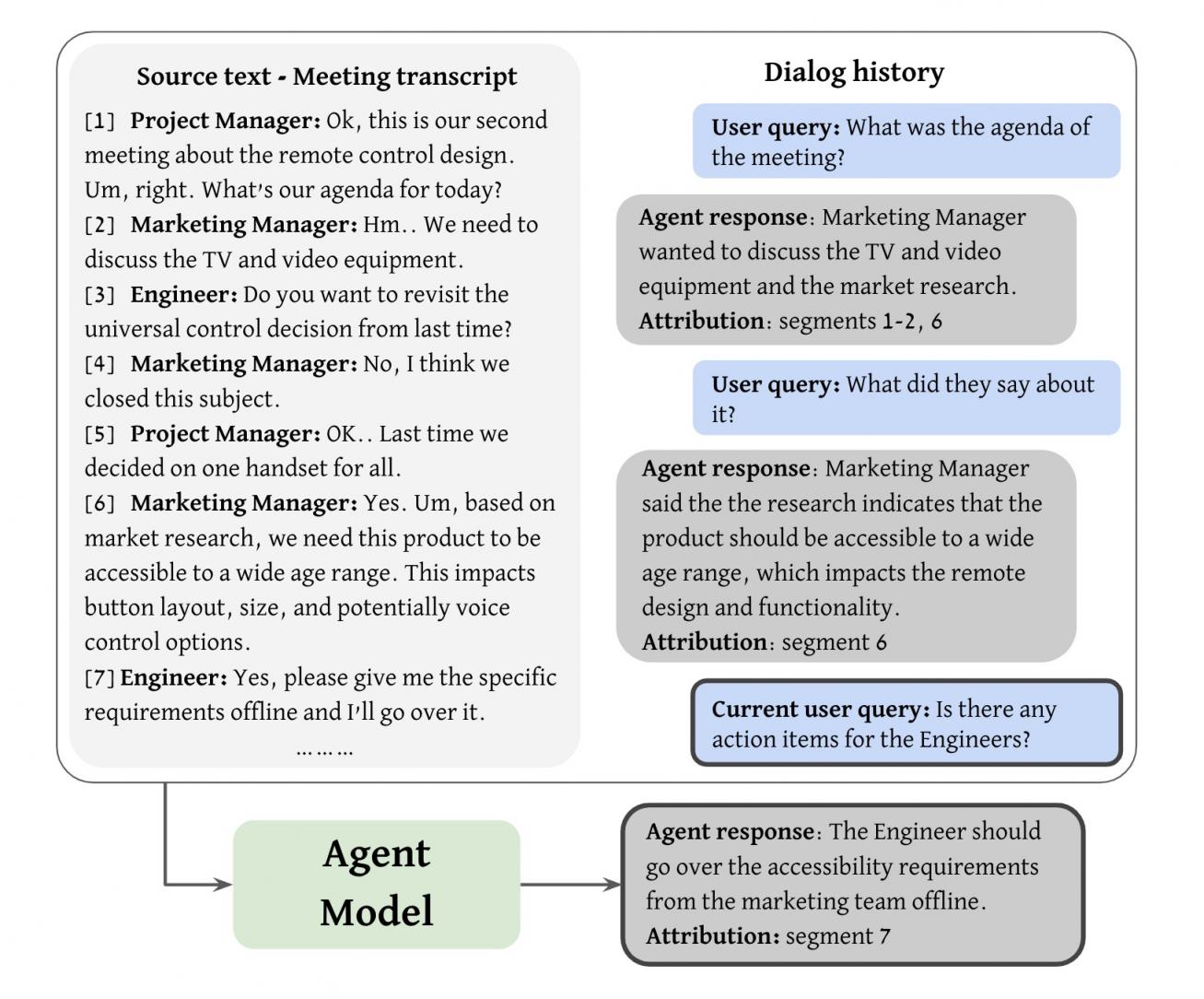
会议录音帮助世界各地的人们补上错过的会议,在通话期间集中注意力而不是记笔记,并查看信息。但审查录音也需要花费大量时间。实现录音高效导航的一种解决方案是使用支持自然语言对话的代理来查看会议录音,以便用户能够补上他们错过的会议。这可以表现为基于源的信息搜索对话任务,其中代理将允许用户高效地浏览给定的知识源并提取感兴趣的信息。在这种对话设置中,用户将与代理就源文本进行多轮查询和响应交互。代理模型的输入将包括源文本、对话历史记录和当前用户查询,其输出应该是对查询的响应和一组归因(支持响应的源文档中的文本跨度)。
WDIM-1-代理
代理模型任务的说明。代理接收源文本(会议记录)、对话历史记录和当前用户查询。然后,它会生成相应的响应以及源文本中的支持归因。每个归因都是一系列连续的记录片段。
然而,要训练有效的代理模型,高质量的对话数据集至关重要。会议领域中现有的数据集提供了摘要和问答数据,但没有一个支持会议内容的多轮对话。对话设置带来了额外的复杂性,因为每个查询和响应除了记录之外还必须考虑共享的对话状态(例如,之前共享的信息),以保持连贯的对话流。创建对话数据集的一种突出技术是 Wizard-of-Oz (WOZ) 方法,其中两个人类注释者共同制作对话,扮演用户和代理的角色。然而,WOZ 方法完全是手动的,耗时,并且可能导致答案的质量因注释者而异。
考虑到这一点,我们提出了“基于源的信息寻求对话的有效数据生成:会议记录的用例”,其中描述了我们的第一个开源会议信息寻求对话数据集(MISeD)。为了扩展最近自动生成对话数据集的趋势,我们通过提示预先训练的 LLM 来部分自动化 WOZ 流程创建了 MISeD。我们使用单独的提示来指导 LLM 生成用户查询和代理响应。接下来是注释器验证和手动生成归因。使用 MISeD 微调的模型与现成的模型相比表现出卓越的性能,即使是那些更大规模的模型。在 MISeD 上进行微调可以提供与完全手动数据微调相当的响应生成质量,同时提高归因质量并减少时间和精力。
WDIM-2-概述
迭代对话生成流程。每次,查询提示都会引导 LLM 根据记录、累积的对话历史记录和查询模板生成用户查询。然后,响应提示会结合迄今为止的完整上下文生成代理响应。迭代此自动过程会产生完整的对话,然后由注释者验证,并进一步通过响应属性对其进行扩充。
数据集创建方法
我们使用基于会议记录的半自动化方法创建了 MISeD 数据集。它包括以下阶段:
自动对话生成
我们迭代地生成对话轮次,每个轮次由一个用户查询和一个代理响应组成。这些都是通过有针对性的 LLM 提示生成的(详见我们的论文)。
• 用户查询提示:这些提示包含记录、对话历史记录和从查询指令池中随机选择的模板化指令,旨在包含各种查询类型。这些模板改编自QMSum论文查询模式(最初用于人工注释者),以指导 LLM 生成。我们既包括针对整体会议主题的一般查询,也包括关注特定主题或个人的特定查询。我们还扩展了 QMSum 模式以包括是/否问题、无法回答的变体以生成无法从记录中回答的查询,以及依赖于现有对话获取上下文的上下文相关查询。
• 代理响应提示:生成用户查询后,我们为 LLM 提供一个提示,其中包括会议记录、对话历史记录、当前查询以及如何生成代理响应的说明。该说明指导法学硕士生成符合一定长度和格式指南并以会议内容为基础的答案。
对话注释和验证
我们将自动生成的对话呈现给注释者,他们评估生成的查询和响应,如有必要进行更正,并在源文本中识别相应的归因。
MISeD 数据集
我们将自动数据创建方法应用于QMSum 会议语料库的记录,涉及三个会议领域:产品,使用AMI语料库;学术,使用ICSI语料库;以及公开的议会委员会会议。为了根据会议记录生成对话(包括查询和响应),我们使用了公开的 Gemini Pro 模型。生成的数据集包括 443 个对话,包含 4430 个查询-响应轮次。在验证过程中,注释者消除了 6% 的查询,产生了 4161 个轮次。在这些剩余的轮次中,注释者纠正了 11% 的响应。
每个数据集条目都包含一个关于特定会议记录的对话,其中包含最多十个查询-响应轮次以及相关元数据和归因记录跨度。为了进行模型训练和评估,对话被拆分为任务实例。每个实例代表一个查询及其历史记录、目标响应和归因。
WDIM-3-分布
MISeD 中的成绩单和归属统计。
我们已经开源MISeD 数据集,以便研究人员可以公开使用。
评估与表现
为了评估 MISeD 数据,我们将它与使用传统 WOZ 方法收集的数据集进行比较。“用户”注释者被赋予会议的一般背景并被问及相关问题,而“代理”注释者则使用完整的记录来提供答案和支持归因。此 WOZ 测试集包含 70 个对话(700 个查询-响应对)。它可用作无偏测试集,揭示模型在完全由人工生成的数据上的性能。我们发现 WOZ 注释时间比 MISeD 注释时间慢 1.5 倍。
我们比较了以下三种模型类型的性能:针对长上下文(16k 个标记)在 MISeD 上进行微调的编码器-解码器( LongT5 XL );使用带有成绩单和查询(28k 个标记)的提示的 LLM( Gemini Pro/Ultra);以及针对 MISeD 进行微调的 LLM(Gemini Pro),使用与上述相同的提示和上下文长度。
我们使用 MISeD 训练集(2922 个训练示例)训练了微调后的代理模型。自动评估是在完整测试集(628 个 MISeD 查询、700 个 WOZ 查询)上计算的,而手动评估则在每个测试集的 100 个查询的随机子集上运行。
我们通过自动和人工评估从两个维度评估代理模型:生成的响应的质量和提供的归因的准确性。我们的评估方法在我们的论文中进行了描述,结果如下所示:
WDIM-4-自动评估
WDIM-5-人类评估
MISeD 和 WOZ 测试集的响应评估。
这些在 MISeD 和完全手动 WOZ 测试集以及现有的基于查询的摘要基准 ( QMSum ) 上进行的基线模型评估显示了使用 MISeD 数据集进行训练的好处。它帮助较小的、经过微调的 LongT5 模型几乎匹配更大的 Gemini 模型的性能。在 MISeD 上微调 Gemini Pro 可显著改善其结果,甚至优于更大的 Gemini Ultra。
总体而言,WOZ 测试集的得分较低,表明由于完全由人类创建,其挑战性更大。由于与训练数据一致,经过微调的模型在 MISeD 测试集上的表现不出所料地更好。归因评估得出了类似的趋势,表明使用 MISeD 进行微调可以提高性能。当我们将使用半自动 MISeD 数据训练的模型的性能与使用手动 WOZ 数据训练的模型的性能进行比较时,我们发现两个训练集(大小相同)都产生了可比的结果。完整结果可以在论文中找到。
结论与未来工作
我们引入了一种创建基于源、信息搜索型对话数据集的新方法。使用有针对性的 LLM 提示和人工编辑,我们半自动化了传统的 WOZ 流程。我们用会议记录对话数据集 MISeD 演示了这种方法,实现了质量的提高、数据生成速度的加快以及数据集生成工作的减少。我们正在与研究界分享MISeD 数据集,并很高兴看到它将如何增强会议探索研究。
虽然查询和响应创建成功,但归因仍然具有挑战性。未来对改进归因生成模型的研究可以实现更完整的对话生成自动化,从而实现更高效的流程。此外,LLM 和提示技术的进步将使它们能够产生高质量的结果,而这些结果可能几乎不需要人工验证。
致谢
该作品的直接贡献者包括 Lotem Golany、Filippo Galgani、Maya Mamo、Nimrod Parasol、Omer Vandsburger、Nadav Bar 和 Ido Dagan。
我们感谢 David Karam、Michelle Tadmor Ramanovich、Eliya Nachmani、Benny Schlesinger、David Petrou 和 Blaise Aguera y Arcas 对本研究的支持和反馈。我们还要感谢 Victor Cărbune、Lucas Werner 和 Ondrej Skopek 对注释框架的帮助,以及 Riteeka Kapila 领导注释团队。
评论