 大型语言模型 (LLM) 的最新进展为开发Gemini等功能强大的多模态 LLM (MLLM) 奠定了基础。MLLM 可以处理其他模态,例如图像或视频,同时保留语言理解和生成功能。尽管 MLLM 在各种任务中的表现令人印象深刻,但对象幻觉问题对其广泛采用构成了重大挑战。对象幻觉是指生成的语言中包含给定输入中不存在或无法验证的对象或其属性的描述。
大型语言模型 (LLM) 的最新进展为开发Gemini等功能强大的多模态 LLM (MLLM) 奠定了基础。MLLM 可以处理其他模态,例如图像或视频,同时保留语言理解和生成功能。尽管 MLLM 在各种任务中的表现令人印象深刻,但对象幻觉问题对其广泛采用构成了重大挑战。对象幻觉是指生成的语言中包含给定输入中不存在或无法验证的对象或其属性的描述。
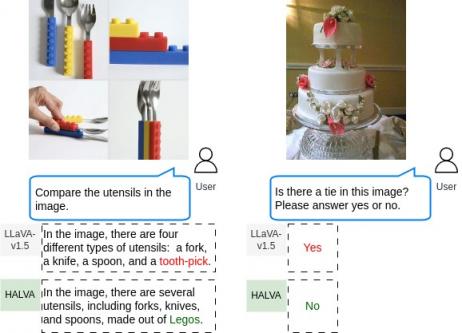
物体幻觉的例子。 左图:当被要求比较图像中的餐具时,LLaVA-v1.5错误地提到了牙签的存在,而没有提到乐高积木的存在。右图:LLaVA-v1.5 错误地确认了婚礼蛋糕图像中“领带”的存在。
先前的研究尝试在三个关键阶段之一中解决物体幻觉问题:推理(例如,Woodpecker)、预训练(例如,HACL)或微调(例如,HA-DPO)。微调方法是一种更有效的方法,因为它们既不需要从头开始训练(与基于预训练的方法不同),也不需要更改服务基础设施(与基于推理的方法不同)。然而,现有的微调方法优先考虑缓解物体幻觉,而以牺牲基础模型在解决一般视觉和语言任务时的性能为代价。
为此,在“通过数据增强对比调节减轻物体幻觉”中,我们引入了一种对比调节方法,该方法可应用于现成的 MLLM 以减轻幻觉,同时保留其一般的视觉语言能力。对于给定的事实标记(即,真实字幕中的单词或词段),我们通过选择性地改变真实信息,通过生成数据增强来创建幻觉标记。此方法在一对标记之间运行,目的是提高模型输出事实标记而非幻觉标记的概率。我们证明该方法简单、快速,并且只需要最少的训练,并且在推理时没有额外的开销。
数据增强对比调整
我们的方法包括两个关键步骤:(1)生成数据增强和(2)对比调整。对于给定的一对视觉语言指令和相应的正确答案,应用生成数据增强来获得幻觉响应。我们从正确答案中选择性地改变地面真实对象和与对象相关的属性,以引入输入图像中不存在的幻觉概念。
然后计算一对事实标记和幻觉标记之间的对比损失。我们的目标是尽量减少生成幻觉标记的可能性,相应地,尽量增加生成事实标记的可能性。我们使用KL 散度正则化器训练 MLLM,以确保 MLLM 在一般视觉语言任务中保持其原始性能,防止其偏离基础模型。我们将使用对比调整框架训练的 MLLM 称为幻觉减弱语言和视觉助手 (HALVA)。
给定一对视觉语言指令和相应的正确答案,我们执行生成数据增强来构建幻觉反应,有选择地改变真实对象和相关属性。
结果
我们使用广泛使用的开源 MLLM LLaVA-v1.5作为基础模型,并使用对比调整框架 (HALVA) 对其进行训练。然后,我们将其在物体幻觉缓解和一般视觉问答任务 (VQA) 方面的表现与基于微调的方法HA-DPO和EOS进行比较。鉴于其在标准基准上的表现,我们将 LLaVA-v1.5 视为下限,并将GPT-4V视为强有力的参考点。
我们使用AMBER基准和带图像相关性的字幕幻觉评估(CHAIR) 指标来评估 MLLM 在图像描述任务上的表现,评估幻觉率和生成的图像描述的细节水平。后者通过计算图像中存在的、在模型输出中准确捕获的真实对象的百分比来量化。我们的目标是减轻幻觉,同时保留或提高图像描述的丰富性。如下图左所示,HALVA 捕获了更多的真实对象,而幻觉比 HA-DPO 更少。此外,虽然 EOS 实现了略低的幻觉率,但它降低了图像描述的细节水平,表现不如 HALVA。
我们还使用F1 分数来比较 MLLM 在视觉问答任务上的表现,使用AMBER基准来评估物体幻觉,使用TextVQA基准来评估一般视觉语言准确性。如下图右图所示,与基础模型相比,HA-DPO 和 EOS 在减轻物体幻觉方面的表现均不及 HALVA,甚至降低了一般视觉语言能力。
将 HALVA 的性能与现有微调方法进行比较的高级概述。减轻图像描述任务中的物体幻觉(左)。一般视觉语言任务中的表现(右)。
图像描述任务中物体幻觉的评估
在评估图像描述任务的性能时,我们使用 CHAIR 在两个层面上测量幻觉:实例级和句子级。在此任务中,HALVA 被提示“详细描述图像”,这会触发它生成详细的图像描述。在MS COCO数据集上,与基础变体相比,HALVA 显著减少了幻觉。例如,与 LLaVA-v1.5 相比,7B(HALVA-7B)和 13B(HALVA-13B)变体分别将实例级幻觉从 15.4 分减少到 11.7 分,从 13 分减少到 12.8 分。在 AMBER 基准测试中,CHAIR 还捕获了图像描述中幻觉对象的频率,其中 HALVA-7B 和 HALVA-13B 分别将幻觉从 7.8 分和 6.6 分减少到 6.6 分和 6.4 分。
定量结果表明,与基础模型 LLaVA-v1.5 相比,HALVA 在图像描述任务中的物体幻觉率有所降低。我们在实例级别测量 CHAIR,值越低越好。
在图像描述任务中,HALVA 与基础模型 LLaVA-v1.5 进行定性演示的比较示例。
视觉问答任务中物体幻觉的评估
我们使用MME基准在判别任务上评估 HALVA 。具体来说,我们利用 MME 的幻觉子集,它由四个与对象相关的子任务组成——存在、计数、位置和颜色——称为 MME-Hall。下面显示的结果表明,与基本模型 LLaVA-v1.5 相比,HALVA 的性能有了显著提高。例如,HALVA-13B 的得分为 675 分(满分 800 分),与基本模型相比,性能提高了 31.7 分。
定量结果表明,与基础模型 LLaVA-v1.5 相比,HALVA 在视觉问答任务中的物体幻觉有所减少。最高分数为 800 分;分数越高越好。
在 AMBER 基准测试中,HALVA 7B 和 13B 将 LLaVA-v1.5 7B 和 13B 的 F1 分数大幅提高 8.7 分和 13.4 分。
定量结果表明,与基础模型 LLaVA-v1.5 相比,HALVA 在视觉问答任务中减少了物体幻觉。最高分为 100 分,分数越高越好。
在下面的定性示例中,我们展示了 HALVA 如何捕捉图像中的细节来为给定的问题提供事实答案。
HALVA-image8
HALVA 与视觉问答基础模型 LLaVA-v1.5 的定性演示示例比较。
评估缓解物体幻觉以外的幻觉
为了进一步对我们的方法进行压力测试,以应对不局限于物体且可能因视觉错觉而发生的其他形式的视觉语言幻觉,我们使用HallusionBench基准来评估性能。我们的结果表明,HALVA 也直接有利于其他形式的视觉语言幻觉。与基本模型相比,HALVA 7B 和 13B 变体分别将整体准确率提高了 1.86% 和 2.16%。
定量结果表明,与基础模型 LLaVA-v1.5 相比,HALVA 在缓解其他形式的视觉语言幻觉方面有所减少,这些幻觉不限于物体,可能由于视觉错觉等原因而发生。我们报告的准确度越高越好。
我们在下面的定性示例中说明了 HALVA 捕捉超越物体幻觉的视觉幻觉的能力:
HALVA 对视觉错觉有效性的定性演示样本。
结论
为了缓解 MLLM 中的物体幻觉,我们引入了数据增强对比调整。我们提出的方法可以有效缓解物体幻觉及其他问题,同时保留甚至提高其在一般视觉语言任务中的表现。此外,所提出的对比调整简单、快速,并且只需要极少的训练,推理时无需额外开销。我们相信我们的方法也可能应用于其他领域。例如,它可能适用于缓解偏见和有害语言生成等。
致谢
我们衷心感谢我们的合著者 Ali Etemad、Ahmad Beirami、Sercan Arik 和 Tomas Pfister 的贡献。特别感谢 Tom Small 为本篇博文制作动画人物。
评论