
视觉变换器和 MLP 模型的多轴方法
自 2012 年推出AlexNet以来,卷积神经网络一直是计算机视觉领域的主要机器学习架构。最近,受到自然语言处理中Transformers演变的启发,注意力机制已被广泛纳入视觉模型中。这些注意力机制会增强输入数据的某些部分,同时最小化其他...
自 2012 年推出AlexNet以来,卷积神经网络一直是计算机视觉领域的主要机器学习架构。最近,受到自然语言处理中Transformers演变的启发,注意力机制已被广泛纳入视觉模型中。这些注意力机制会增强输入数据的某些部分,同时最小化其他...

四足机器人的一个重要前景是它们有可能在人类难以或无法进入的复杂户外环境中运行。无论是在深山中寻找自然资源,还是在地震灾区寻找生命信号,一个坚固而多功能的四足机器人都会非常有用。为了实现这一点,机器人需要感知环境,了解其运动挑战,并相应地调整...
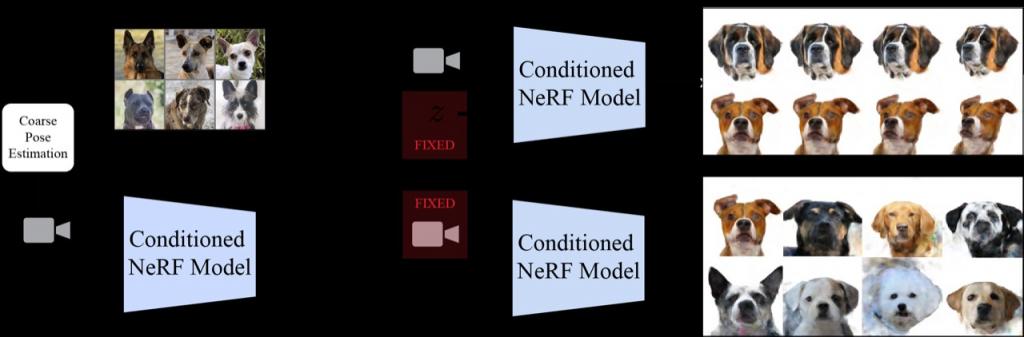
人类视觉的一个重要方面是,我们能够从观察到的二维图像中理解三维形状。利用计算机视觉系统实现这种理解一直是该领域的一项基本挑战。许多成功的方法依赖于多视图数据,即从不同角度获得同一场景的两张或多张图像,这使得推断图像中物体的三维形状变得容易得...
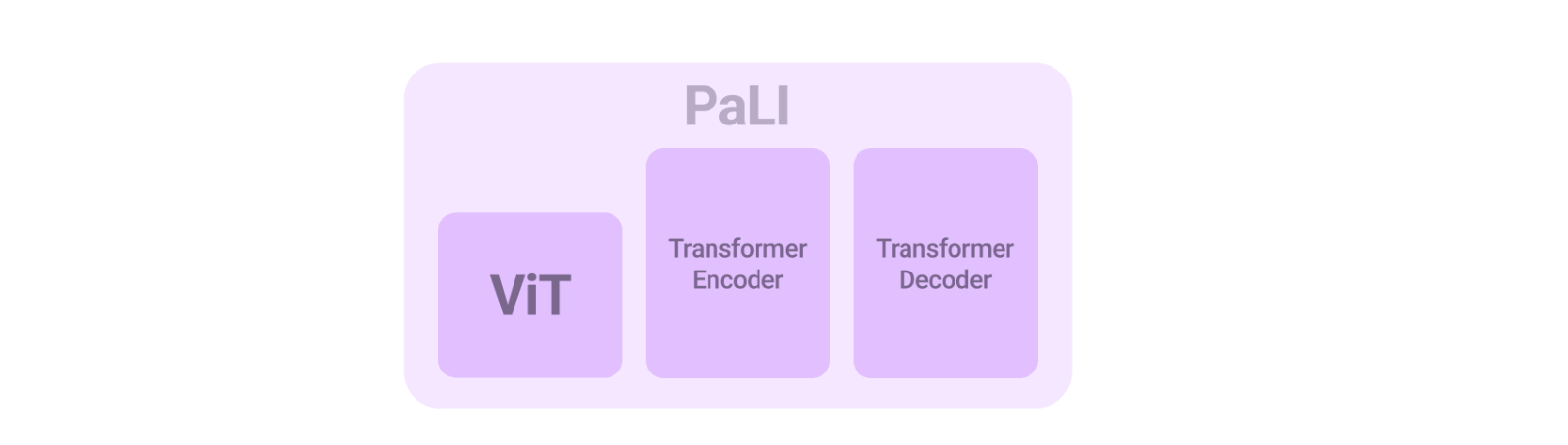
高级语言模型(例如GPT、GLaM、PaLM和T5)已经展示了多样化的功能,并通过扩大其参数数量在各个任务和语言中取得了令人瞩目的成果。视觉语言 (VL) 模型可以从类似的扩展中受益,以解决许多任务,例如图像字幕、视觉问答(VQA)、对象识...
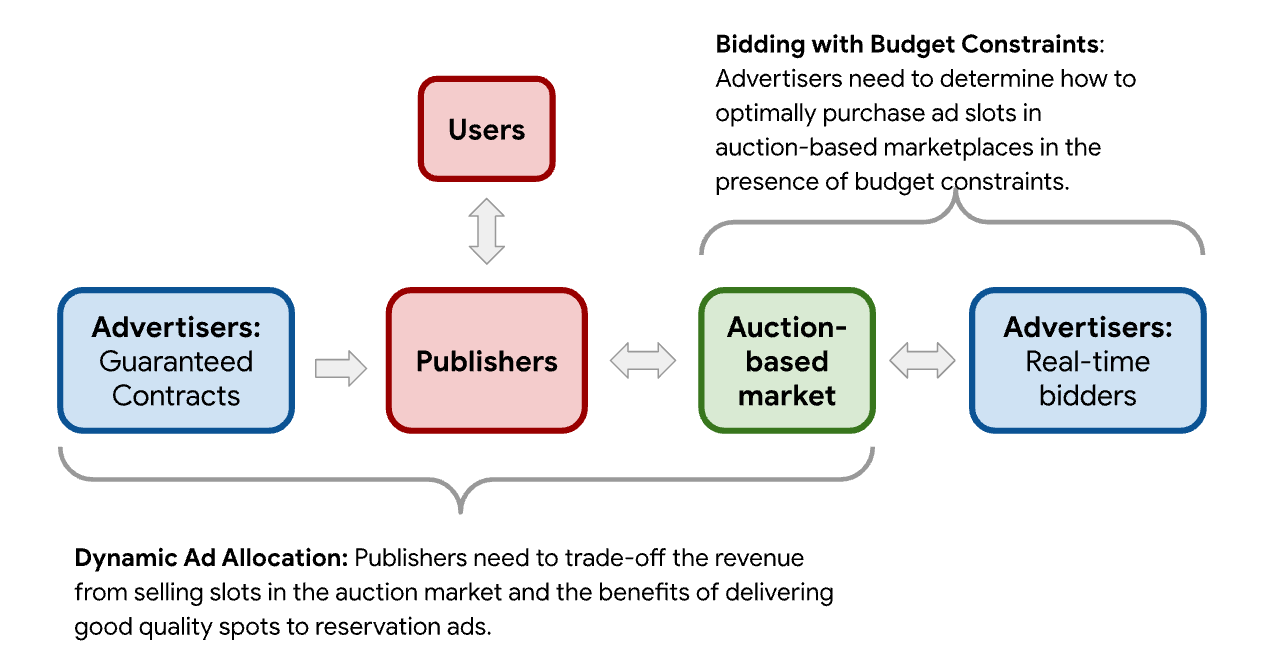
数字技术的出现改变了航空、在线零售和互联网广告等商业领域的决策方式。如今,需要在高度不确定和快速变化的环境中反复做出实时决策。此外,组织的资源通常有限,需要在决策之间进行有效分配。这类问题被称为资源受限的在线分配问题,应用比比皆是。一些示例...

视图合成是计算机视觉和计算机图形学交叉领域的一个 长期存在的问题,它的任务是从该场景的多张图片中创建新的场景视图。自神经辐射场 (NeRF) 引入以来,这一问题受到了越来越多的关注 [ 1、2、3 ] 。这个问题很有挑战性,因为要准确地合成...
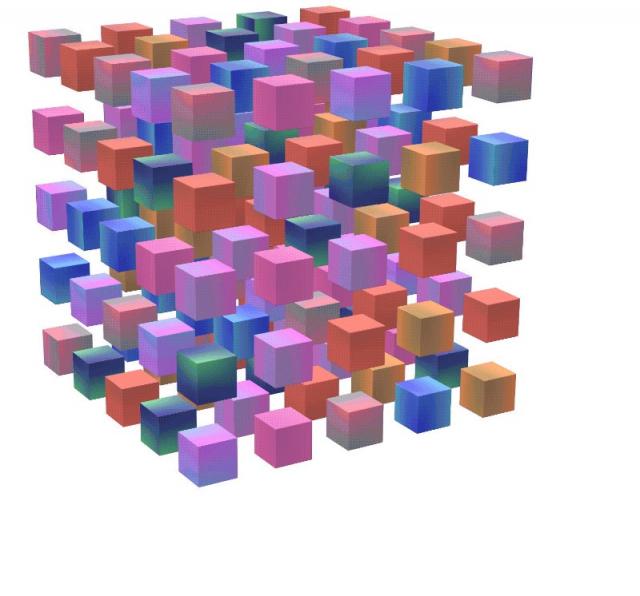
当今计算机科学和机器学习 (ML) 的许多激动人心的应用都处理跨单个大型坐标系的多维数据集,例如,根据空间网格上的大气测量值进行天气建模,或根据 2d 或 3d 扫描中的多通道图像强度值进行医学成像预测。在这些设置中,即使是单个数据集也可能...

帧插值是从给定的一组图像中合成中间图像的过程。该技术通常用于时间上采样,以提高视频的刷新率或创建慢动作效果。如今,有了数码相机和智能手机,我们经常在几秒钟内拍摄多张照片以捕捉最佳照片。在这些“几乎重复”的照片之间进行插值可以产生引人入胜的视...
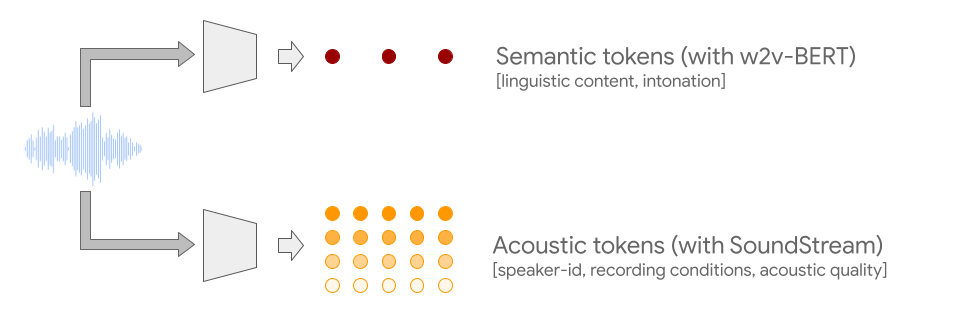
生成逼真的音频需要对以不同尺度表示的信息进行建模。例如,就像音乐从单个音符构建复杂的乐句一样,语音将时间局部结构(如音素或音节)组合成单词和句子。在所有这些尺度上创建结构良好且连贯的音频序列是一项挑战,通过将音频与可以指导生成过程的转录相结...
图像字幕制作是一项机器学习任务,用于自动为给定图像生成流畅的自然语言描述。这项任务对于提高视障用户的可访问性非常重要,也是涵盖视觉和语言建模的多模态研究的核心任务。然而,用于图像字幕的数据集主要以英语提供。除此之外,只有少数数据集涵盖了有限...