高级语言模型(例如GPT、GLaM、PaLM和T5)已经展示了多样化的功能,并通过扩大其参数数量在各个任务和语言中取得了令人瞩目的成果。视觉语言 (VL) 模型可以从类似的扩展中受益,以解决许多任务,例如图像字幕、视觉问答(VQA)、对象识别和上下文光学字符识别(OCR)。提高这些实际任务的成功率对于日常交互和应用非常重要。此外,对于一个真正通用的系统,视觉语言模型应该能够以多种语言运行,而不仅仅是一种。
在“ PaLI:一种联合扩展的多语言语言-图像模型”中,我们引入了一个统一的语言-图像模型,该模型经过训练可以执行多项任务,并且支持 100 多种语言。这些任务涵盖视觉、语言以及多模态图像和语言应用,例如视觉问答、图像字幕、对象检测、图像分类、OCR、文本推理等。此外,我们使用了一组包含 109 种语言自动收集的注释的公共图像,我们将其称为 WebLI 数据集。在 WebLI 上预训练的 PaLI 模型在具有挑战性的图像和语言基准测试(例如COCO-Captions、 TextCaps、VQAv2、OK-VQA、TextVQA等)上实现了最佳性能。它还优于之前模型的多语言视觉字幕和视觉问答基准测试。
概述
该项目的一个目标是研究语言和视觉模型如何在规模上相互作用,特别是语言-图像模型的可扩展性。我们探索每个模态的扩展以及由此产生的跨模态扩展交互。我们将最大的模型训练为 170 亿 (17B) 个参数,其中视觉组件扩展到 4B 个参数,语言模型扩展到 13B。
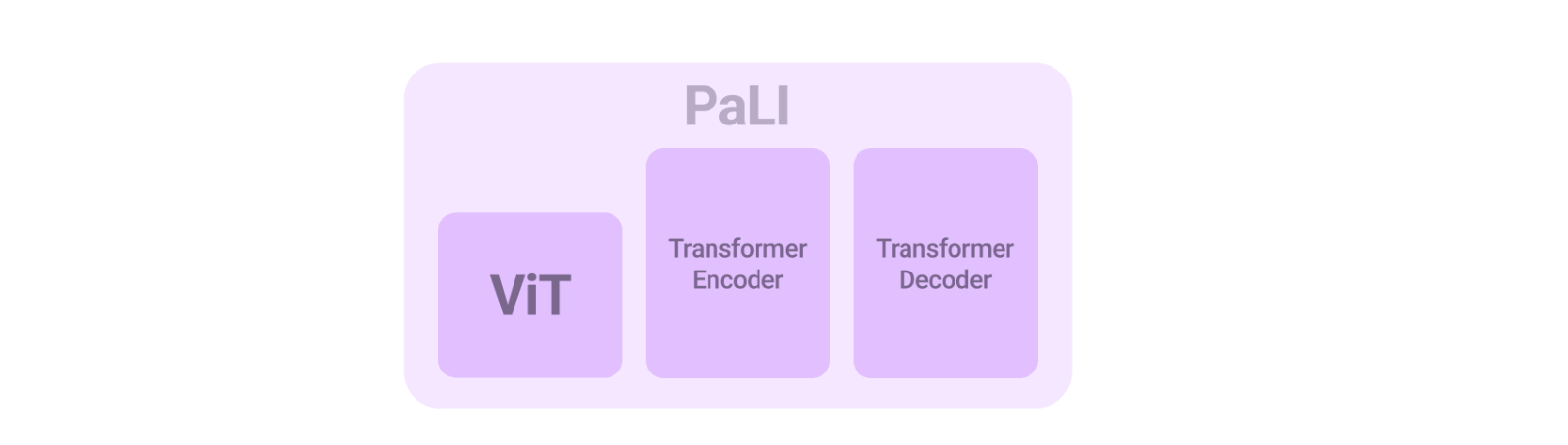
PaLI 模型架构简单、可重复使用且可扩展。它由处理输入文本的Transformer编码器和生成输出文本的自回归 Transformer 解码器组成。为了处理图像,Transformer 编码器的输入还包括表示经Vision Transformer (ViT) 处理的图像的“视觉词”。PaLI 模型的一个关键组成部分是重复使用,我们使用先前训练的单模视觉和语言模型(例如mT5-XXL和大型ViT )的权重来为模型播种。这种重复使用不仅能够从单模训练中转移能力,而且还节省了计算成本。
PaLI 模型使用相同的 API 处理语言-图像、纯语言和纯图像领域的各种任务(例如,视觉问题回答、图像字幕、场景文本理解等)。该模型经过训练,支持 100 多种语言,并经过调整,可针对多种语言-图像任务执行多种语言。
数据集:100 多种语言的语言-图像理解
深度学习的扩展研究表明,更大的模型需要更大的数据集才能有效训练。为了释放语言图像预训练的潜力,我们构建了 WebLI,这是一个多语言语言图像数据集,由公共网络上的图像和文本构建而成。
WebLI 将文本语言从纯英语数据集扩展到 109 种语言,这使我们能够以多种语言执行下游任务。数据收集过程与其他数据集(例如ALIGN和LiT)所采用的过程类似,使我们能够将 WebLI 数据集扩展到 100 亿张图片和 120 亿个替代文本。
除了使用网络文本进行注释外,我们还应用Cloud Vision API对图像执行 OCR,从而生成 290 亿个图像-OCR 对。我们根据 68 个常见视觉和视觉语言数据集的训练、验证和测试分割对图像执行近乎重复的数据删除,以避免从下游评估任务中泄露数据,这是文献中的标准做法。为了进一步提高数据质量,我们根据图像和替代文本对的跨模态相似性对其进行评分,并调整阈值以仅保留 10% 的图像,总共有 10 亿张图像用于训练 PaLI。
从 WebLI 中抽样的图像与多语言替代文本和 OCR 相关。第二幅图像由 jopradier 提供(原件),根据CC BY-NC-SA 2.0 许可使用。其余图像也已获得使用许可。
WebLI 中来自 alt-text 和 OCR 的识别语言的统计数据。
WebLI 和其他大型视觉语言数据集CLIP、ALIGN和LiT的图像文本对计数。
训练大型语言图像模型
视觉语言任务需要不同的能力,有时目标也不同。有些任务天生就需要定位对象才能准确解决任务,而有些任务可能需要更全局的视角。同样,不同的任务可能需要长答案或紧凑答案。为了实现所有这些目标,我们利用 WebLI 预训练数据的丰富性,并引入预训练任务的混合,为各种下游应用准备模型。为了实现解决各种任务的目标,我们将所有任务转换为单个通用 API(输入:图像 + 文本;输出:文本),从而实现多个图像和语言任务之间的知识共享,该 API 也与预训练设置共享。用于预训练的目标被转换为相同的 API,作为加权混合,旨在保持重用模型组件的能力并训练模型执行新任务(例如,用于图像描述的拆分字幕、用于场景文本理解的 OCR 预测、VQG 和 VQA 预测)。
该模型在JAX中使用开源T5X和Flaxformer框架通过Flax 进行训练。对于视觉组件,我们使用开源BigVision框架引入并训练了一个名为 ViT-e 的大型ViT架构,该架构具有 4B 参数。ViT-e 遵循与ViT-G架构(具有 2B 参数)相同的配方。对于语言组件,我们将密集的 token 嵌入与视觉组件生成的 patch 嵌入连接在一起,作为多模态编码器-解码器的输入,该编码器-解码器由 mT5-XXL 初始化。在训练 PaLI 期间,此视觉组件的权重被冻结,并且仅更新多模态编码器-解码器的权重。
结果
我们在多种多样且具有挑战性的常见视觉语言基准上对 PaLI 进行了比较。PaLI 模型在这些任务上取得了最先进的结果,甚至超过了文献中的非常大的模型。例如,它在几个 VQA 和图像字幕任务上的表现优于大几倍(80B 参数)的 Flamingo模型,并且在具有挑战性的纯语言和纯视觉任务上也保持了良好的性能,而这些任务并不是主要的训练目标。
PaLI(17B 参数)在多个视觉和语言任务上的表现优于最先进的方法(包括SimVLM、CoCa、GIT2、Flamingo、BEiT3)。在此图中,我们展示了与之前的最佳模型相比的绝对分数差异,以突出 PaLI 的相对改进。比较是在官方测试分组(如果有)上进行的。CIDEr分数用于评估图像字幕任务,而 VQA 任务则通过 VQA 准确度进行评估。
模型缩放结果
我们研究了图像和语言模型组件在模型扩展方面如何相互作用,以及模型在何处产生最大的收益。我们得出结论,同时扩展两个组件可获得最佳性能,具体而言,扩展需要相对较少参数的视觉组件是最重要的。扩展对于在多语言任务中获得更好的性能也至关重要。
缩放 PaLI 模型的语言和视觉组件有助于提高性能。该图显示了与 PaLI-3B 模型相比的分数差异:CIDEr分数用于评估图像字幕任务,而 VQA 任务则通过 VQA 准确度进行评估。
多语言字幕极大地受益于扩展 PaLI 模型。我们在 35 种语言基准 Crossmodal-3600 上评估了 PaLI。这里我们展示了所有 35 种语言的平均分数以及七种不同语言的单独分数。
模型自省:模型公平性、偏见和其他潜在问题
为了避免在大型语言和图像模型中产生或强化不公平偏见,重要的第一步是 (1) 对所使用的数据以及模型如何使用这些数据保持透明,以及 (2) 测试模型公平性并进行负责任的数据分析。为了解决 (1),我们的论文包含数据卡和模型卡。为了解决 (2),本文包含数据集的人口统计分析结果。我们认为这是第一步,并且知道在将模型应用于新任务时继续衡量和减轻潜在偏见非常重要,这符合我们的AI 原则。
结论
我们介绍了 PaLI,这是一种可扩展的多模态和多语言模型,旨在解决各种视觉语言任务。我们在视觉、语言和视觉语言任务中展示了改进的性能。我们的工作说明了规模在模型的视觉和语言部分以及两者之间的相互作用中的重要性。我们发现,完成视觉和语言任务,尤其是多种语言的任务,实际上需要大规模模型和数据,并且可能会从进一步扩展中受益。我们希望这项工作能够激发对多模态和多语言模型的进一步研究。
致谢
我们感谢进行这项研究的所有作者:Soravit (Beer) Changpinyo、AJ Piergiovanni、Piotr Padlewski、Daniel Salz、Sebastian Goodman、Adam Grycner、Basil Mustafa、Lucas Beyer、Alexander Kolesnikov、Joan Puigcerver、Nan Ding、Keran Rong、Hassan Akbari、Gaurav Mishra、Linting Xue、Ashish Thapliyal、James Bradbury、Weicheng Kuo、Mojtaba Seyedhosseini、Chao Jia、Burcu Karagol Ayan、Carlos Riquelme、Andreas Steiner、Anelia Angelova、Xiaohua Zhai、Neil Houlsby 和 Radu Soricut。我们还要感谢 Claire Cui、Slav Petrov、Tania Bedrax-Weiss、Joelle Barral、Tom Duerig、Paul Natsev、Fernando Pereira、Jeff Dean、Jeremiah Harmsen、Zoubin Ghahramani、Erica Moreira、Victor Gomes、Sarah Laszlo、Kathy Meier-Hellstern、Susanna Ricco、Rich Lee、Austin Tarango、Emily Denton、Bo Pang、Wei Li、Jihyung Kil、Tomer Levinboim、Julien Amelot、Zhenhai Zhu、Xiangning Chen、Liang Chen、Filip Pavetic、Daniel Keysers、Matthias Minderer、Josip Djolonga、Ibrahim Alabdulmohsin、Mostafa Dehghani、Yi Tay、Elizabeth Adkison、James Cockerille、Eric Ni、Anna Davies 和 Maysam Moussalem 提出的建议、改进和支持。我们感谢 Tom Small 为该博文提供可视化效果。
评论