生成逼真的音频需要对以不同尺度表示的信息进行建模。例如,就像音乐从单个音符构建复杂的乐句一样,语音将时间局部结构(如音素或音节)组合成单词和句子。在所有这些尺度上创建结构良好且连贯的音频序列是一项挑战,通过将音频与可以指导生成过程的转录相结合,可以解决这个问题,无论是语音合成的文本转录还是钢琴的 MIDI 表示。然而,当试图对音频的未转录方面进行建模时,这种方法就会失效,例如帮助有语言障碍的人恢复声音所必需的说话者特征,或钢琴演奏的风格成分。
在“ AudioLM:一种用于音频生成的语言建模方法”中,我们提出了一种用于音频生成的新框架,该框架通过仅收听音频来学习生成逼真的语音和钢琴音乐。AudioLM 生成的音频表现出长期一致性(例如语音中的语法、音乐中的旋律)和高保真度,优于以前的系统,并通过语音合成或计算机辅助音乐中的应用推动了音频生成的前沿。根据我们的AI 原则,我们还开发了一个模型来识别 AudioLM 生成的合成音频。
从文本到音频语言模型
近年来,在非常大的文本语料库上训练的语言模型已经展示了其卓越的生成能力,从开放式对话到机器翻译,甚至常识推理。它们还展示了对文本以外的其他信号(例如自然图像)进行建模的能力。AudioLM 背后的关键直觉是利用语言建模的这种进步来生成音频,而无需在带注释的数据上进行训练。
然而,从文本语言模型转向音频语言模型时,需要解决一些挑战。首先,必须应对这样一个事实:音频的数据速率明显更高,因此序列会更长——虽然一个书面句子可以用几十个字符来表示,但其音频波形通常包含数十万个值。其次,文本和音频之间存在一对多关系。这意味着,同一句话可以由具有不同说话风格、情感内容和录音条件的不同说话者来呈现。
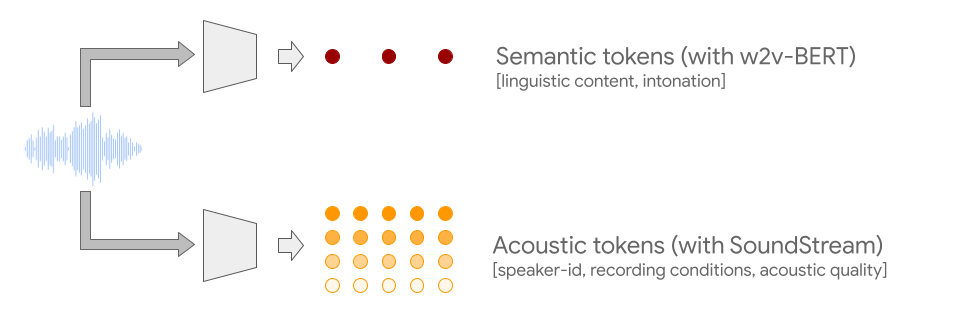
为了克服这两个挑战,AudioLM 利用了两种音频标记。首先,从自监督音频模型w2v-BERT中提取语义标记。这些标记既能捕捉局部依赖关系(例如语音中的语音、钢琴音乐中的局部旋律),也能捕捉全局长期结构(例如语音中的语言语法和语义内容、钢琴音乐中的和声和节奏),同时对音频信号进行大量下采样,以便对长序列进行建模。
然而,从这些标记重建的音频保真度较差。为了克服这一限制,除了语义标记外,我们还依赖于SoundStream 神经编解码器生成的声学标记,这些标记可以捕捉音频波形的细节(例如扬声器特性或录音条件)并实现高质量的合成。训练系统生成语义和声学标记可同时实现高音频质量和长期一致性。
训练纯音频语言模型
AudioLM 是一个纯音频模型,在训练过程中不使用任何文本或音乐符号表示。AudioLM 通过链接多个Transformer模型(每个阶段一个)来分层建模音频序列,从语义标记到精细声学标记。每个阶段都根据过去的标记进行下一个标记预测的训练,就像训练文本语言模型一样。第一阶段对语义标记执行此任务,以建模音频序列的高级结构。
在第二阶段,我们将整个语义标记序列与过去的粗略声学标记连接起来,并将两者作为条件输入到粗略声学模型中,然后该模型预测未来的标记。此步骤对声学特性进行建模,例如语音中的说话者特征或音乐中的音色。
在第三阶段,我们使用精细声学模型处理粗略声学标记,从而为最终音频添加更多细节。最后,我们将声学标记输入 SoundStream 解码器以重建波形。
经过训练后,我们可以使用几秒钟的音频来调节 AudioLM,使其能够产生一致的连续性。为了展示 AudioLM 框架的普遍适用性,我们考虑了来自不同音频领域的两个任务:
语音延续,其中模型有望保留提示的说话者特征、韵律和录音条件,同时产生语法正确、语义一致的新内容。
钢琴延续,模型有望生成在旋律、和声和节奏方面与提示一致的钢琴音乐。
在下面的视频中,您可以收听示例,其中要求模型继续语音或音乐并生成训练期间未见过的新内容。在收听时,请注意,灰色垂直线之后听到的所有内容都是由 AudioLM 生成的,并且模型从未见过任何文本或音乐转录,而只是从原始音频中学习。我们在此网页上发布了更多示例。
为了验证我们的结果,我们请人类评分员聆听简短的音频片段,并判断它是人类语音的原始录音还是 AudioLM 生成的合成延续。根据收集到的评分,我们观察到成功率为 51.2%,与随机分配标签时实现的 50% 的成功率在统计上没有显著差异。这意味着对于普通听众来说,很难将 AudioLM 生成的语音与真实语音区分开来。
我们对 AudioLM 的研究仅用于研究目的,目前我们还没有计划将其更广泛地发布。根据我们的AI 原则,我们试图了解并降低人们可能将 AudioLM 合成的短语音样本误解为真实语音的可能性。为此,我们训练了一个分类器,它可以以非常高的准确率 (98.6%) 检测 AudioLM 生成的合成语音。这表明,尽管对于某些听众来说 (几乎) 无法区分,但 AudioLM 生成的连续语音很容易通过简单的音频分类器检测到。这是帮助防止 AudioLM 被滥用的关键第一步,未来的努力可能会探索音频“水印”等技术。
结论
我们引入了 AudioLM,这是一种用于音频生成的语言建模方法,它既能提供长期连贯性,又能提供高音频质量。语音生成实验表明,AudioLM 不仅可以生成语法和语义上连贯的语音而无需任何文本,而且该模型生成的连续语音几乎与人类的真实语音没有区别。此外,AudioLM 的功能远远超出语音,可以对钢琴音乐等任意音频信号进行建模。这鼓励了未来扩展到其他类型的音频(例如多语言语音、复音音乐和音频事件),以及将 AudioLM 集成到编码器-解码器框架中,以执行文本到语音或语音到语音翻译等条件任务。
致谢
本文所述工作由 Zalán Borsos、Raphaël Marinier、Damien Vincent、Eugene Kharitonov、Olivier Pietquin、Matt Sharifi、Dominik Roblek、Olivier Teboul、David Grangier、Marco Tagliasacchi 和 Neil Zeghidour 撰写。我们非常感谢 Google 同事就这项工作提出的所有讨论和反馈。
评论