一个由心理学家和神经生物学家组成的国际团队通过实验发现,两种类型的法学硕士在心智理论测试中能够与人类相提并论,甚至超越人类。在《自然人类行为》杂志上发表的研究中,该团队对志愿者进行了心智理论测试,并将平均结果与两种类型的法学硕士的平均结果进行了比较。
过去几年, ChatGPT 等大型语言模型(LLM) 不断改进,如今已可供公众使用。它们的能力也在稳步提升。其中一项新功能是推断情绪——隐藏的含义或人类用户的心理状态。
在这项新研究中,研究小组想知道法学硕士的能力是否已经发展到可以与人类一样执行心智理论任务的程度。
心理理论任务是由心理学家设计的,用于测量一个人在社交互动过程中的心理和/或情绪状态。先前的研究表明,人类会使用各种线索向他人发出自己的心理状态信号,目的是在不具体的情况下传达信息。
先前的研究也表明,人类擅长捕捉此类线索,但其他动物则不然。因此,该领域的许多人认为计算机不可能通过此类测试。研究小组测试了几名法学硕士,看看他们与参加相同测试的一群人类相比表现如何。
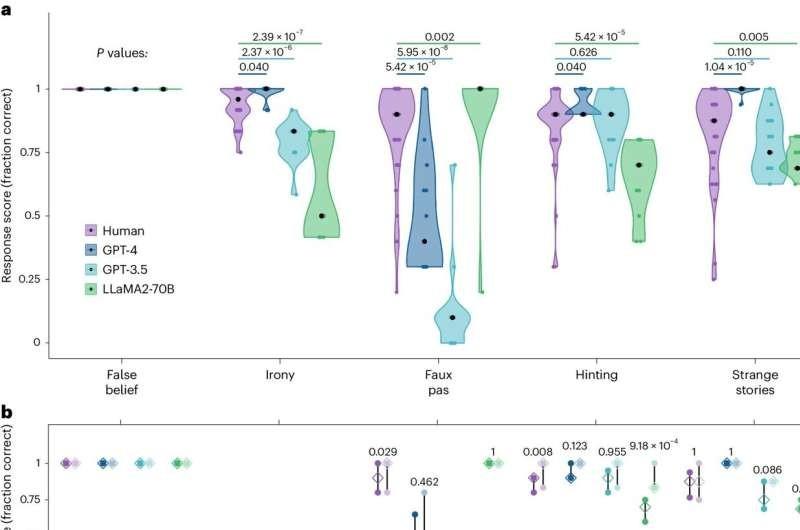
研究人员分析了 1,907 名参加标准心智理论测试的志愿者的数据,并将结果与多个 LLM(如 Llama 2-70b 和 GPT-4)的结果进行了比较。两组志愿者都回答了五种类型的问题,每种问题都旨在衡量诸如失礼、讽刺或陈述的真实性等。每个人还被要求回答经常向儿童提出的“错误信念”问题。
研究人员发现,法学硕士的表现通常与人类相当,有时甚至更好。更具体地说,他们发现 GPT-4 在五种主要类型的任务中表现最好,而 Llama-2 的得分在某些情况下比其他类型的法学硕士或人类差得多,但在其他类型的问题上表现要好得多。
研究人员表示,实验表明,LLM 目前在心智理论测试中的表现与人类相当,但他们并没有说这种模型和人类一样聪明或更聪明,或者总体上更有直觉。
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/135.html
评论