
十多年前,Arm Ltd 的高管们发现数据中心的能源成本飙升,并意识到有机会扩展其同名片上系统的低功耗架构,该架构从一开始就主导了手机市场,并从 PowerPC 手中接管了嵌入式设备市场并进入企业服务器。
我们的想法是创建功耗更低、更便宜且更具延展性的 Intel Xeon 和 AMD Epyc CPU 替代品。
虽然花了数年时间开发架构,也曾因一些早期 Arm 服务器处理器供应商倒闭或放弃计划而感到失望,也曾为发展软件生态系统付出了巨大努力,但该公司现在已在本地系统和云数据中心站稳了脚跟
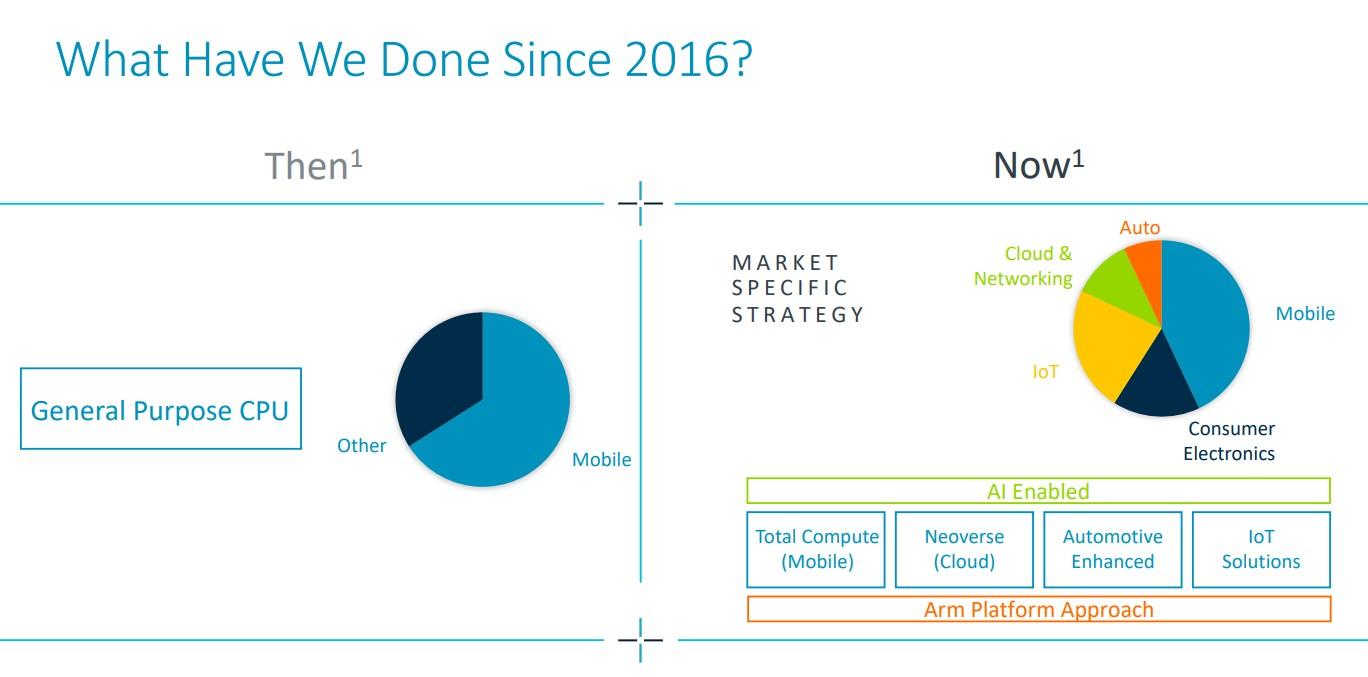
在2 月份提交的最新季度财报中,Arm 夸耀了其面向市场的平台方法,并指出 2016 年至少有三分之二的收入来自移动领域的通用 CPU。现在,Arm 的平台面向多个市场,包括云和网络系统。该公司还在HPC 领域取得了成功,富士通的 A64FX 处理器基于 Armv8.2-A 架构,为最新 Top500 榜单中速度排名第四的超级计算机“Fugaku”提供动力。
随着人工智能的兴起,Arm 首席执行官雷内·哈斯 (Rene Haas) 看到了类似的机会。哈斯告诉The Next Platform,现在模型消耗大量电力,而且未来只会增加。
“我花了很多时间与这些公司的首席执行官交谈,电力问题一直是每个人最关心的问题,因为我们认为人工智能可以带来的好处是相当巨大的,”哈斯说。“为了获得越来越多的智能、更好的模型、更好的预测能力、添加上下文、学习等,对计算的需求正在不断增加,这显然会推动电力需求。感觉它在过去几个月里加速了——这是双关语——我们看到了生成式人工智能的一切,尤其是所有这些复杂的工作负载。”
Haas 表示,Arm 与母公司软银一起参与了最近1.1 亿美元的美日联合资助人工智能研究计划,并为该计划贡献了 2500 万美元。Arm 将在控制功耗和相关成本方面发挥核心作用。 。 Arm 已经证明,其架构可以使数据中心的能源效率提高 15%。他说,这些类型的节省也可以转化为人工智能工作负载。
哈斯指出,现代数据中心现在每年消耗约 460 太瓦时的电力,到 2030 年,这一数字可能会增加两倍。他说,数据中心现在消耗了全球电力需求的约 4%。如果不加以控制,这一比例可能会上升到 25%。
这也是有代价的。在斯坦福大学最新的人工智能指数报告中,研究人员写道“训练这些巨型模型的成本呈指数级增长”,并指出谷歌的 Gemini Ultra 的训练成本约为 1.91 亿美元,而 OpenAI 的 GPT-4 的训练成本估计为 7800 万美元。相比之下,“最初的 Transformer 模型引入了几乎所有现代 LLM 的基础架构,成本约为 900 美元。”
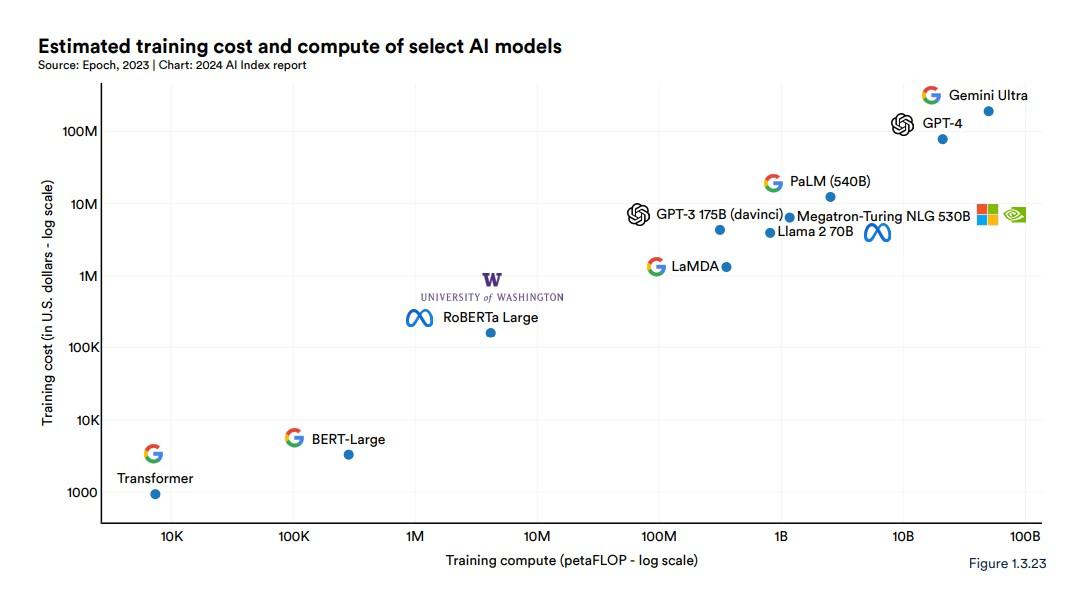
哈斯表示,这些成本只会越来越高。OpenAI 和谷歌等人工智能公司正在努力实现通用人工智能(AGI),即人工智能系统能够推理、思考、学习,并且表现得和人类一样好甚至更好,这将需要更大、更复杂的模型,需要输入更多数据,这将增加功耗。
“我在想 GPT-3 与 GPT-4 相比有多复杂,GPT-3 需要十倍的数据、更大的规模、更长的 token 等等。然而,它在思考、背景和判断方面做出惊人事情的能力仍然非常有限,”他说。“模型需要发展,在某种程度上,需要在数据集方面变得更加复杂。除非你进行越来越多的训练,否则你无法做到这一点。这是一个良性循环。要变得更聪明、推进模型并进行更多研究,你只需要进行越来越多的训练。在未来几年内,推进这种训练所需的计算量将非常大,而且看起来,与你运行模型的方式相比,短期内不会有任何大的根本性变化。”
最近几周,Arm、英特尔和英伟达推出了新平台,旨在满足日益增长的人工智能功率需求,包括在边缘进行更多模型训练和推理的压力,而边缘数据的生成和存储越来越多。 Arm 本月推出了 Ethos-U85 神经处理单元 (NPU),承诺比前代产品性能提高四倍,能效提高 20%。

同一天,英特尔推出了 Gaudi 3 AI 加速器和 Xeon 6 CPU,首席执行官帕特·基辛格 (Pat Gelsinger) 认为,芯片的功能和供应商的开放系统方法将推动英特尔的 AI 工作负载发展。 Haas 不太确定,他说“英特尔和 AMD 可能很难做他们的事情,因为他们只是构建标准产品和插入连接到英特尔或 AMD CPU 的 Nvidia H100 加速器的伟大想法。”
Haas 表示,对更高数据中心效率的需求也推动了定制芯片的趋势,并指出大多数芯片都是采用 Arm 的 Neoverse 架构构建的。这些芯片包括亚马逊的 Graviton 处理器、谷歌云的 Axion、微软 Azure 的 Cobalt和Oracle Cloud 的 Ampere,它们不仅可以提高性能和效率,还可以实现 AI 工作负载所需的集成。
“现在,你基本上可以为数据中心构建一个 AI 定制实现,并以任何你想要的方式配置它,以获得巨大的性能,”他说。“这些定制芯片就是我们前进的机会。”
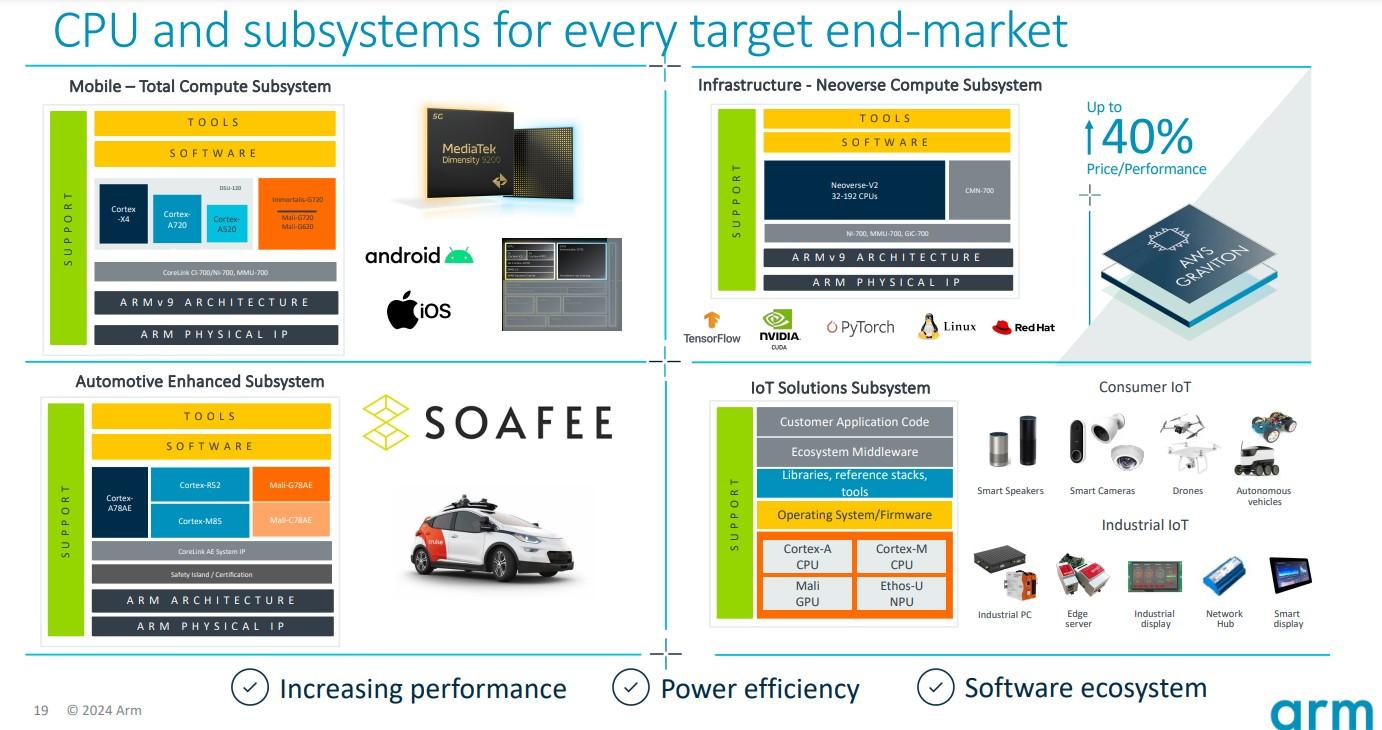
他提到了 Nvidia上个月推出的专注于 AI 的Grace Blackwell GB200 加速器,其中包括两个 Nvidia B200 Tensor Core GPU,通过 900 GB/s NVLink 互连连接到基于 Arm 的 Grace CPU。
“在某种程度上,Grace-Blackwell 是一款定制芯片,因为他们之前的 H1 100 基本上是插入机架并与 X86 处理器相连,”Haas 说。 “现在 Grace-Blackwell 已高度集成到使用 Arm 的产品中。 Arm 将成为其中的核心,因为 Arm 所实现的集成水平以及您可以进行定制的事实将真正允许优化最高效的工作负载类型。我将以格雷斯-布莱克威尔为例。在该架构中,通过在 NVLink 上使用 CPU 和 GPU,您可以开始解决有关内存带宽的一些关键问题,因为最终,这些巨型模型需要大量的内存访问才能运行推理。”
他表示,与法学硕士中的 H100 GPU 相比,Arm 架构实现的系统级设计优化有助于将功耗降低 25 倍,并将每个 GPU 的性能提高 30 倍。在人工智能时代,这种定制是必要的,因为创新和采用的步伐只会加快。
“在某种程度上,我们整个行业面临的挑战之一是,虽然这些基础模型变得越来越智能,而且创新的步伐非常快,但构建新芯片需要一定的时间,建立新的数据中心需要一定的时间,建立新的配电能力需要大量的时间,”哈斯说。 “确保能够以尽可能多的灵活性设计芯片,这是相当艰巨的任务。但它正在发生。它正在以令人难以置信的速度发生。”
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/94.html
评论