任何机器学习方法的有效性都主要取决于其训练数据。在强化学习(RL) 的情况下,人们可以依赖与现实世界交互的代理收集的有限数据,也可以依赖可用于收集所需数据的模拟训练环境。后一种模拟训练方法越来越受欢迎,但它有一个问题——RL 代理可以学习模拟器内置的内容,但往往不善于推广到 与模拟任务略有不同的任务。显然,构建一个涵盖现实世界所有复杂性的模拟器极具挑战性。
解决此问题的一种方法是通过随机化模拟器的所有参数来自动创建更加多样化的训练环境,这一过程称为域随机化(DR)。但是,即使在非常简单的环境中,DR 也可能失败。例如,在下面的动画中,蓝色代理正试图导航到绿色目标。左侧面板显示了使用 DR 创建的环境,其中障碍物和目标的位置已随机化。许多这样的 DR 环境用于训练代理,然后将其转移到中间面板中的简单 Four Rooms 环境。请注意,代理找不到目标。这是因为它还没有学会绕墙行走。尽管 Four Rooms 示例中的墙壁配置可以在 DR 训练阶段随机生成,但可能性不大。因此,代理没有花足够的时间在类似于 Four Rooms 结构的墙壁上进行训练,无法达到目标。

域随机化(左)无法有效地让代理做好转移到之前未见过的环境(例如 Four Rooms 场景(中))的准备。为了解决这个问题,使用极小最大对手来构建之前未见过的环境(右),但可能会导致无法解决的情况。
除了随机化环境参数,还可以训练第二个 RL 代理来学习如何设置环境参数。可以通过查找和利用策略中的弱点(例如,构建它以前从未遇到过的墙壁配置)来训练这个极小极大 对手,以最小化第一个 RL 代理的性能。但这又出现了一个问题。右侧面板显示了由极小极大对手构建的环境,其中代理实际上不可能达到目标。虽然极小极大对手已成功完成其任务(它已最小化原始代理的性能),但它没有为代理提供学习的机会。使用纯对抗性目标也不适合生成训练环境。
我们与加州大学伯克利 分校合作,在最近于NeurIPS 2020上发表的论文“通过无监督环境设计的突发复杂性和零样本迁移”中,提出了一种用于训练对手的新多智能体方法。在这项工作中,我们提出了一种基于极小最大遗憾的算法,即主角对手诱导的遗憾环境设计(PAIRED),它可以防止对手创建不可能的环境,同时仍使其能够纠正智能体策略中的弱点。PAIRED 激励对手将生成环境的难度调整到刚好超出智能体当前能力的范围,从而自动生成越来越具有挑战性的训练任务。我们表明,使用 PAIRED 训练的智能体可以学习更复杂的行为,并且可以更好地推广到未知的测试任务。我们已经在我们的GitHub 存储库上发布了 PAIRED 的开源代码。
成对
为了灵活地限制对手,PAIRED 引入了第三个RL 代理,我们称之为对抗代理,因为它与对抗代理(即设计环境的代理)结盟。我们将最初的代理(导航环境的代理)重命名为主角。一旦对手生成环境,主角和对抗代理都会在该环境中进行游戏。
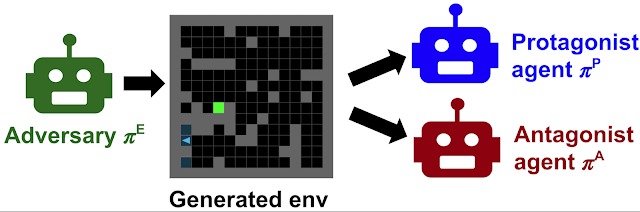
对手的任务是最大化对手的奖励,同时最小化主角的奖励。这意味着它必须创造可行的环境(因为对手可以解决它们并获得高分),但对主角来说具有挑战性(利用其当前策略中的弱点)。两种奖励之间的差距就是遗憾—— 对手试图最大化遗憾,而主角则竞相将其最小化。
上面讨论的方法(域随机化、极小最大遗憾和 PAIRED)可以使用相同的理论框架进行分析,即我们在论文中详细描述的无监督环境设计 (UED)。UED 在环境设计和决策理论之间建立了联系,使我们能够证明域随机化等同于理由不足原理,极小最大对手遵循最大最小原理,而 PAIRED 正在优化极小最大遗憾。这种形式主义使我们能够使用决策理论中的工具来了解每种方法的优点和缺点。下面,我们展示了这些想法如何应用于环境设计:
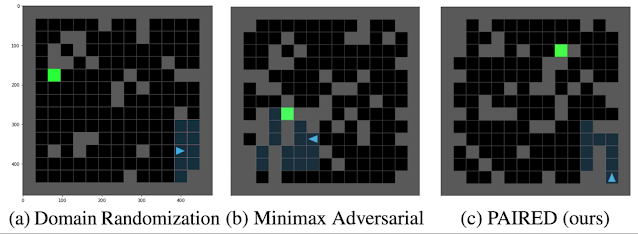
域随机化 ( a ) 会生成非结构化环境,这些环境并不适合代理的学习进度。极小最大对手 ( b ) 可能会创建不可能的环境。PAIRED ( c ) 可以生成具有挑战性的结构化环境,但代理仍有可能完成这些环境。
课程生成
极小最大遗憾的有趣之处在于,它激励对手生成一个最初简单,然后越来越具有挑战性的环境课程。在大多数 RL 环境中,奖励函数将为更高效地完成任务或在更少的时间步内完成任务的人提供更高的分数。当这是真的时,我们可以表明遗憾激励对手创造主角尚无法解决的最简单的环境。为了说明这一点,让我们假设对手是完美的,并且总是获得可能的最高分。同时,主角很糟糕,在所有事情上都得到零分。在这种情况下,遗憾仅取决于环境的难度。由于更简单的环境可以在更少的时间步内完成,因此它们允许对手获得更高的分数。因此,在简单环境中失败的遗憾大于在困难环境中失败的遗憾:

因此,通过最大化遗憾,对手正在寻找主角无法完成的简单环境。一旦主角学会了解决每个环境,对手就必须继续寻找主角无法解决的稍微困难的环境。因此,对手会生成越来越困难的任务课程。
结果
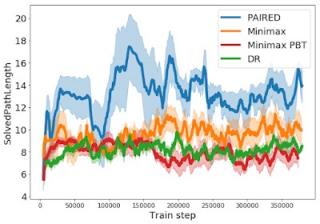
我们可以在下方的学习曲线中看到课程的出现,该曲线绘制了代理成功解决的迷宫的最短路径长度。与极小极大或域随机化不同,PAIRED 对手创建了一个越来越长但可能的迷宫课程,使 PAIRED 代理能够学习更复杂的行为。
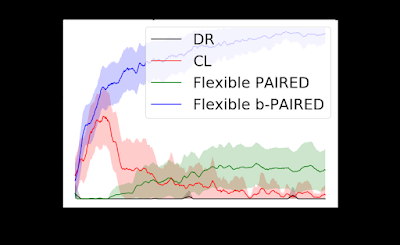
但是,这些不同的训练方案能否帮助代理更好地泛化到未知的测试任务?下面,我们可以看到每种算法在一系列具有挑战性的测试任务上的零样本迁移性能。随着迁移环境的复杂性增加,PAIRED 与基线之间的性能差距越来越大。对于像 Labyrinth 和 Maze 这样极其困难的任务,PAIRED 是唯一可以偶尔解决任务的方法。这些结果提供了有希望的证据,表明 PAIRED 可用于提高深度 RL 的泛化能力。

不可否认的是,这些简单的网格世界并不能反映许多强化学习方法试图解决的现实世界任务的复杂性。我们在“用于学习浏览网页的对抗环境生成”中解决了这个问题,该文考察了 PAIRED 在应用于更复杂的问题(例如教强化学习代理浏览网页)时的性能。我们提出了一个改进版的 PAIRED,并展示了如何使用它来训练对手生成越来越具有挑战性的网站课程:

上图显示了对手在训练的早期、中期和后期阶段构建的网站,这些网站从每页使用很少的元素发展到同时使用许多元素,使任务变得越来越困难。我们测试了使用此课程训练的代理是否可以推广到标准化的网页导航任务,并实现了 75% 的成功率,比最强的课程学习基线提高了 4 倍:
结论
深度强化学习非常擅长拟合模拟训练环境,但我们如何构建涵盖现实世界复杂性的模拟?一种解决方案是使此过程自动化。我们提出了无监督环境设计 (UED) 作为一个框架,描述了自动创建训练环境分布的不同方法,并表明 UED 包含了域随机化和极小最大对抗训练等先前的工作。我们认为 PAIRED 是 UED 的一种好方法,因为遗憾最大化会导致越来越具有挑战性的任务课程,并让代理做好成功转移到未知测试任务的准备。
致谢
我们要感谢“通过无监督环境设计的突发复杂性和零样本迁移”的共同作者:Michael Dennis、Natasha Jaques、Eugene Vinitsky、Alexandre Bayen、Stuart Russell、Andrew Critch 和 Sergey Levine,以及“用于学习浏览网页的对抗性环境生成”的共同作者:Izzeddin Gur、Natasha Jaques、Yingjie Miao、Jongwook Choi、Kevin Malta、Manoj Tiwari、Honglak Lee 和 Aleksandra Faust。此外,我们感谢 Michael Chang、Marvin 张、Dale Schuurmans、Aleksandra Faust、Chase Kew、Jie Tan、Dennis Lee、Kelvin Xu、Abhishek Gupta、Adam Gleave、Rohin Shah、Daniel Filan、Lawrence Chan、Sam Toyer、Tyler Westenbroek、Igor Mordatch、Shane Gu、DJ Strouse 和 Max Kleiman-Weiner 对本工作做出贡献的讨论。
评论