神经网络的设备推理可以低延迟且注重隐私地 实现各种实时应用,例如姿势估计和背景模糊。通过使用带有XNNPACK ML 加速库的TensorFlow Lite等 ML 推理框架,工程师可以在模型大小、推理速度和预测质量之间找到一个最佳平衡点,从而优化其模型以在各种设备上运行。
优化模型的一种方法是使用稀疏神经网络 [ 1、2、3 ],其中很大一部分权重设置为零。一般来说,这是一种理想的品质,因为它不仅可以通过压缩减小模型大小,还可以跳过很大一部分乘加运算,从而加快推理速度。此外,可以增加模型中的参数数量,然后将其稀疏化以匹配原始模型的质量,同时仍可从加速推理中受益。然而,这种技术的使用在生产中仍然受到限制,主要是因为缺乏稀疏流行卷积架构的工具,以及对在设备上运行这些操作的支持不足。
今天,我们宣布发布XNNPACK 加速库和 TensorFlow Lite 的一组新功能,这些功能可实现稀疏网络的高效推理,同时还发布了有关如何稀疏化神经网络的指南,旨在帮助研究人员开发自己的稀疏设备模型。这些工具由我们与DeepMind合作开发,为新一代实时感知体验提供支持,包括MediaPipe中的手势跟踪和Google Meet 中的背景功能,推理速度提高了 1.2 倍到 2.4 倍,同时模型大小减少了一半。在这篇文章中,我们提供了稀疏神经网络的技术概述——从训练期间引入稀疏性到设备部署——并就研究人员如何创建自己的稀疏模型提供了一些想法。

相同质量的密集(左)和稀疏(右)模型对 Google Meet背景特征的处理时间比较。为了便于阅读,显示的处理时间是 100 帧的移动平均值。
稀疏化神经网络
许多现代深度学习架构(例如MobileNet和EfficientNetLite)主要由具有小空间核的深度卷积和线性组合输入图像特征的1x1 卷积组成。虽然此类架构有许多潜在的稀疏化目标,包括许多网络开头经常出现的完整2D 卷积或深度卷积,但 1x1 卷积是推理时间最昂贵的运算符。由于它们占总计算量的 65% 以上,因此它们是稀疏化的最佳目标。
建筑学 推理时间
移动网络 85%
MobileNetV2 71%
MobileNetV3 71%
高效网络精简版 66%
现代移动架构中 1x1 卷积专用推理时间的比较(百分比)。
在现代设备上的推理引擎(如 XNNPACK)中,1x1 卷积以及深度学习模型中的其他操作的实现依赖于 HWC 张量布局,其中张量维度对应于输入图像的高度、宽度和通道(例如红色、绿色或蓝色)。此张量配置允许推理引擎并行处理与每个空间位置(即图像的每个像素)相对应的通道。但是,这种张量排序并不适合稀疏推理,因为它将通道设置为张量的最内层维度,并且使其访问的计算成本更高。
我们对 XNNPACK 的更新使其能够检测模型是否稀疏。如果是,它会从标准密集推理模式切换到稀疏推理模式,在该模式中它采用 CHW(通道、高度、宽度)张量布局。这种张量的重新排序可以加速稀疏 1x1 卷积核的实现,原因有二:1) 当相应的通道权重在单次条件检查后为零时,可以跳过张量的整个空间切片,而不是逐像素测试;2) 当通道权重非零时,可以通过将相邻像素加载到同一内存单元中来提高计算效率。这使我们能够同时处理多个像素,同时还可以跨多个线程并行执行每个操作。当至少 80% 的权重为零时,这些变化共同导致速度提高 1.8 倍至 2.3 倍。
为了避免每次运算之后都在最适合稀疏推理的 CHW 张量布局和标准 HWC 张量布局之间来回转换,XNNPACK 提供了多个 CNN 算子在 CHW 布局中的高效实现。
训练稀疏神经网络的指南
要创建稀疏神经网络,此版本中包含的指南建议从密集版本开始,然后在训练期间逐渐将其权重的一部分设置为零。这个过程称为修剪。在众多可用的修剪技术中,我们建议使用幅度修剪(可在TF 模型优化工具包中使用)或最近推出的RigL方法。在训练时间略有增加的情况下,这两种方法都可以成功地稀疏化深度学习模型,而不会降低其质量。生成的稀疏模型可以高效地以压缩格式存储,与密集模型相比,其大小减少了一半。
稀疏网络的质量受多个超参数的影响,包括训练时间、学习率和修剪计划。TF Pruning API提供了有关如何选择这些参数的出色示例,以及一些训练此类模型的技巧。我们建议运行超参数搜索以找到适合您的应用程序的最佳点。
应用
我们证明了可以对分类任务、密集分割(例如Meet 背景模糊)和回归问题(MediaPipe Hands)进行稀疏化,这为用户带来了切实的好处。例如,在 Google Meet 的案例中,稀疏化将模型的推理时间缩短了 30%,从而让更多用户能够使用更高质量的模型。
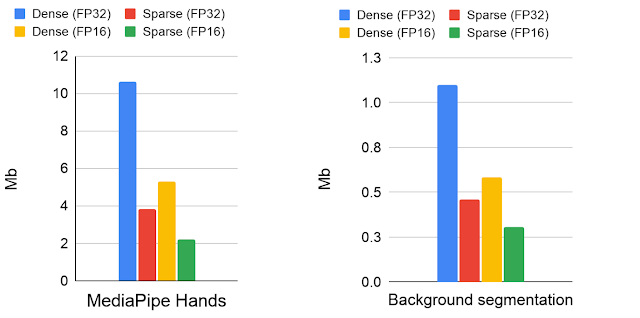
密集模型和稀疏模型的模型大小比较(单位:Mb)。模型已存储为 16 位和 32 位浮点格式。
本文描述的稀疏性方法最适用于基于倒置残差块的架构,例如MobileNetV2、MobileNetV3和EfficientNetLite。网络中的稀疏度会影响推理速度和质量。从固定容量的密集网络开始,我们发现即使在 30% 的稀疏度下性能也会有所提升。随着稀疏度的增加,模型的质量保持相对接近密集基线,直到达到 70% 的稀疏度,超过此值,准确度下降会更加明显。但是,可以通过将基础网络的规模增加 20% 来弥补 70% 稀疏度下准确度的下降,从而缩短推理时间而不会降低模型质量。运行稀疏模型不需要进一步更改,因为 XNNPACK 可以识别并自动启用稀疏推理。
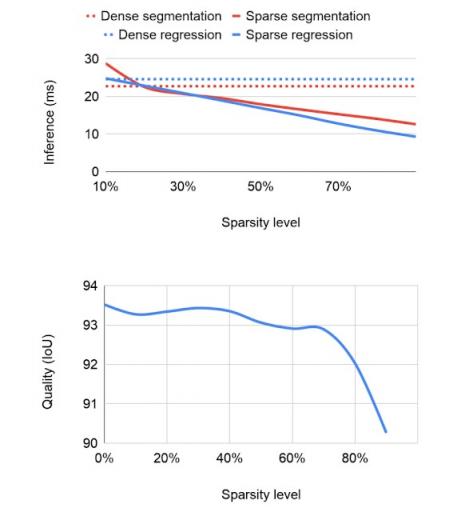
针对推理时间(越小越好)和预测分割掩模的交并比(IoU) 测量的质量,对不同稀疏度水平的消融研究。
稀疏性作为提炼的自动替代
Google Meet 中的背景模糊使用基于经过修改的 MobileNetV3 主干的分割模型,该模型带有注意块。我们通过应用 70% 的稀疏化将模型速度提高了 30%,同时保留了前景蒙版的质量。我们在来自 17 个地理子区域的图像上检查了稀疏和密集模型的预测,没有发现显着差异,并在相关模型卡中发布了详细信息。
同样,MediaPipe Hands使用基于 EfficientNetLite 主干的模型在移动设备和网络上实时预测手部标志点。此主干模型是从大型密集模型中手动提炼出来的,这是一个计算量巨大的迭代过程。使用密集模型的稀疏版本(而不是提炼版),我们能够保持相同的推理速度,但无需从密集模型中进行劳动密集型提炼。与密集模型相比,稀疏模型将推理速度提高了两倍,实现了与提炼模型相同的标志点质量。从某种意义上说,稀疏化可以被视为一种非结构化模型提炼的自动化方法,它可以提高模型性能而无需大量的手动工作。我们在地理多样性数据集上评估了稀疏模型,并公开了模型卡。

相同质量的密集(左)、精简(中)和稀疏(右)模型的执行时间比较。密集模型的处理时间比稀疏或精简模型大 2 倍。精简模型取自官方MediPipe 解决方案。密集和稀疏网络演示可公开获取。
未来工作
我们发现稀疏化是一种简单但功能强大的技术,可用于改进神经网络的 CPU 推理。稀疏推理使工程师能够运行更大的模型,而不会产生显著的性能或大小开销,并为研究提供了一个有前途的新方向。我们将继续扩展 XNNPACK,以更广泛地支持 CHW 布局中的操作,并正在探索如何将其与量化等其他优化技术相结合。我们很高兴看到您可以使用这项技术构建什么!
致谢
特别感谢参与该项目的所有人员:Karthik Raveendran、Erich Elsen、Tingbo Hou、Trevor Gale、Siargey Pisarchyk、Yury Kartynnik、Yunlu Li、Utku Evci、Matsvei Zhdanovich、Sebastian Jansson、Stéphane Hulaud、Michael Hays、Juhyun Lee、张帆、张绰灵、Gregory Karpiak、Tyler Mullen、唐九强、明光勇、Igor Kibalchich 和 Matthias Grundmann。
评论