多年来,在线多人游戏的受欢迎程度呈爆炸式增长,吸引了全球数百万玩家。这种受欢迎程度也成倍增加了对游戏设计师的要求,因为玩家希望游戏制作精良且平衡——毕竟,玩一款单一策略胜过所有其他策略的游戏并不好玩。
为了创造积极的游戏体验,游戏设计师通常会反复调整游戏的平衡性:
通过测试用户的数千次游戏测试进行压力测试
吸收反馈并重新设计游戏
重复 1 和 2,直到游戏测试员和游戏设计师都满意
这个过程不仅耗时,而且不完美——游戏越复杂,细微的缺陷就越容易被忽略。当游戏通常有许多不同的角色可以扮演,有几十种相互关联的技能时,实现正确的平衡就变得更加困难了。
今天,我们介绍了一种利用机器学习 (ML) 调整游戏平衡的方法,即通过训练模型作为游戏测试员,并在数字卡牌游戏原型Chimera上演示了这种方法,我们之前曾将其展示为ML 生成艺术的试验台。通过使用训练有素的代理运行数百万次模拟来收集数据,这种基于 ML 的游戏测试方法使游戏设计师能够更有效地让游戏更有趣、更平衡、更符合他们的原始愿景。
奇美拉
我们开发了Chimera作为游戏原型,在开发过程中会大量依赖机器学习。对于游戏本身,我们特意设计了规则来扩大可能性空间,这使得构建传统的手工 AI 来玩游戏变得困难。
Chimera 的游戏玩法围绕着游戏中的奇美拉展开,玩家的目标是强化和进化这些生物。游戏的目标是击败对手的奇美拉。以下是游戏设计的关键点:
玩家可以玩:
生物,它们可以攻击(通过它们的攻击属性)或被攻击(对抗它们的生命属性),或者
咒语,产生特殊效果。
生物被召唤到容量有限的生物群系中,这些生物群系会物理地放置在棋盘空间中。每个生物都有一个偏好的生物群系,如果被放置在错误的生物群系或容量超标的生物群系中,则会受到反复伤害。
玩家控制一个嵌合体,它从基本的“蛋”状态开始,可以通过吸收生物来进化和强化。要做到这一点,玩家还必须获得一定数量的链接能量,这些能量是由各种游戏机制产生的。
当玩家成功将对手的嵌合体生命值降至 0 时,游戏结束。
学习玩 Chimera
Chimera是一款具有大状态空间的不完美信息纸牌游戏,我们预计对于 ML 模型来说,这款游戏很难学习,尤其是当我们的目标是一个相对简单的模型时。我们使用了一种受早期游戏代理(如AlphaGo)启发的方法,其中训练卷积神经网络(CNN) 来预测给定任意游戏状态时的获胜概率。在对选择随机动作的游戏训练初始模型后,我们让代理与自己对战,迭代地收集游戏数据,然后使用这些数据来训练新代理。随着每次迭代,训练数据的质量不断提高,代理玩游戏的能力也不断提高。
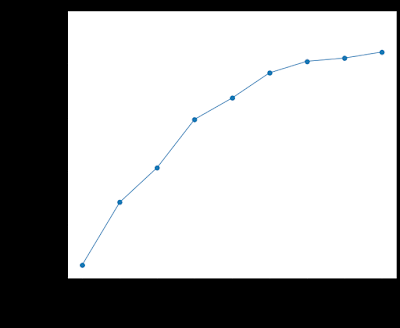
随着训练的进行,ML 代理与我们最好的手工制作的 AI 相比的表现。初始 ML 代理(版本 0)随机选择动作。
对于模型将作为输入接收的实际游戏状态表示,我们发现将“图像”编码传递给 CNN 可获得最佳性能,击败所有基准程序代理和其他类型的网络(例如全连接)。所选模型架构足够小,可以在合理的时间内在 CPU 上运行,这使我们能够下载模型权重并使用Unity Barracuda在 Chimera 游戏客户端中实时运行代理。
用于训练神经网络的游戏状态表示示例。
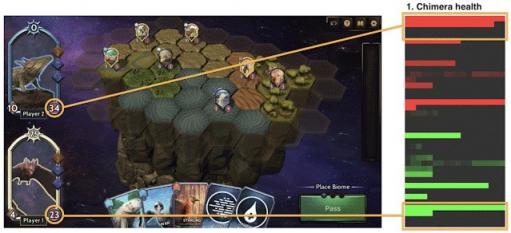
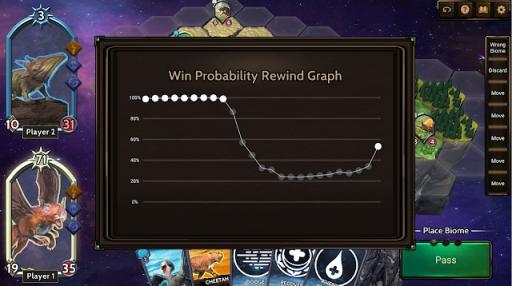
除了为游戏 AI 做出决策之外,我们还使用该模型显示玩家在游戏过程中的预计获胜概率。
平衡奇美拉
这种方法使我们能够模拟比真实玩家在相同时间范围内能够玩的游戏多数百万场的游戏。在收集了表现最佳的代理所玩的游戏数据后,我们分析了结果,以找出我们设计的两种玩家牌组之间的不平衡。
首先,Evasion Link Gen 牌组由具有产生额外链接能量的能力的法术和生物组成,这些能量可用于进化玩家的嵌合体。它还包含使生物能够躲避攻击的法术。相比之下,Damage-Heal牌组包含力量各异的生物,其法术专注于治疗和造成轻微伤害。尽管我们将这些牌组设计为具有同等实力,但Evasion Link Gen牌组在与Damage-Heal牌组对战时获胜的几率为 60% 。
当我们收集与生物群落、生物、法术和嵌合体进化相关的各种统计数据时,有两件事立即引起了我们的注意:
进化嵌合体具有明显的优势——在大多数游戏中,智能体比对手进化嵌合体更多,从而赢得了胜利。然而,每场游戏的平均进化次数并未达到我们的预期。为了使其成为一种核心游戏机制,我们希望增加总体平均进化次数,同时保持其使用的战略性。
T-Rex 生物太强大了。它的出现与胜利密切相关,并且模型总是会扮演 T-Rex,无论召唤到错误或过于拥挤的生物群系会受到什么惩罚。
根据这些见解,我们对游戏进行了一些调整。为了强调嵌合体进化是游戏的核心机制,我们将进化嵌合体所需的链接能量从 3 减少到 1。我们还为霸王龙生物增加了一个“冷却”期,使其从任何行动中恢复所需的时间加倍。
使用更新后的规则重复我们的“自我游戏”训练程序,我们观察到这些变化将游戏推向了预期的方向——每场游戏的平均进化次数增加了,而霸王龙的统治地位逐渐减弱。
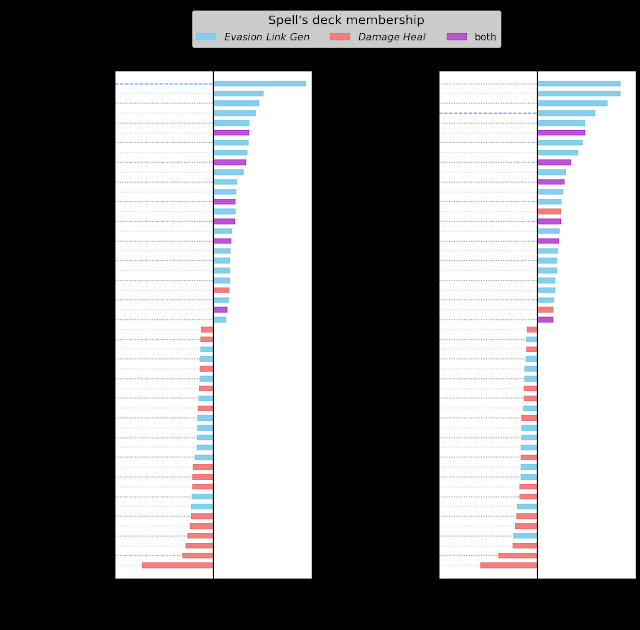
平衡前后霸王龙影响力的对比示例。图表显示了当牌组发起特定咒语互动(例如,使用“躲避”咒语使霸王龙受益)时获胜(或失败)的游戏次数。左图:在更改之前,霸王龙在所检查的每个指标中都具有很强的影响力——最高的存活率、最有可能无视惩罚被召唤、获胜时吸收最多的生物。右图:更改后,霸王龙的强大程度大大降低。
通过削弱 T-Rex,我们成功减少了Evasion Link Gen套牌对超强生物的依赖。即便如此,套牌之间的胜率仍为 60/40,而不是 50/50。仔细查看单个游戏日志后发现,游戏玩法通常不如我们所希望的那样具有战略性。再次搜索我们收集的数据后,我们发现还有几个地方需要进行更改。
首先,我们增加了双方玩家的初始生命值以及治疗法术可以补充的生命值。这是为了鼓励更长的游戏时间,从而让更多不同的策略得以蓬勃发展。特别是,这让伤害-治疗套牌能够存活足够长的时间,从而利用其治疗策略。为了鼓励正确召唤和战略性地放置生物群系,我们增加了将生物放入不正确或过于拥挤的生物群系的现有惩罚。最后,我们通过轻微的属性调整缩小了最强和最弱生物之间的差距。
经过新的调整,我们得到了这两副牌的最终游戏平衡数据:
甲板 每场游戏平均进化次数
(之前 → 之后) 胜率 (100 万场)
(之前 → 之后)
逃避链接生成 1.54 → 2.16 59.1%→49.8%
伤害治疗 0.86 → 1.76 40.9%→50.2%
结论
通常,识别新原型游戏中的不平衡可能需要数月的游戏测试。通过这种方法,我们不仅能够发现潜在的不平衡,还能在几天内引入调整来缓解它们。我们发现一个相对简单的神经网络足以在与人类和传统游戏人工智能的较量中达到高水平的表现。这些代理可以以更多方式发挥作用,例如指导新玩家或发现意想不到的策略。我们希望这项工作能够激发更多探索机器学习在游戏开发中的可能性。
致谢
该项目与许多人合作完成。感谢 Ryan Poplin、Maxwell Hannaman、Taylor Steil、Adam Prins、Michal Todorovic、Xuefan Zhou、Aaron Cammarata、Andeep Toor、Trung Le、Erin Hoffman-John 和 Colin Boswell。感谢所有通过游戏测试、游戏设计建议和提供宝贵反馈做出贡献的人。
评论