机器人研究的总体目标是设计能够协助完成各种任务的系统,从而有可能改善日常生活。大多数用于教导代理执行新任务的强化学习算法都需要奖励函数,该函数为代理提供积极的反馈,以促使其采取行动,从而取得良好的结果。然而,实际上指定这些奖励函数可能非常繁琐,而且在没有明确目标的情况下很难定义,例如房间是否干净或门是否关得足够紧。即使对于易于描述的任务,实际衡量任务是否已解决也可能很困难,可能需要在机器人的环境中添加许多传感器。
另外,使用示例训练模型(称为基于示例的控制)有可能克服依赖传统奖励函数的方法的局限性。这个新的问题陈述与基于“成功检测器”的先前 方法最为相似,而基于示例的控制的高效算法可以让非专家用户教机器人执行新任务,而无需编码专业知识、奖励函数设计知识或安装环境传感器。
在“用示例代替奖励:通过递归分类进行基于示例的策略搜索”中,我们提出了一种机器学习算法,通过提供成功示例来教代理如何解决新任务(例如,如果“成功”示例显示钉子嵌入墙壁,代理将学习拿起锤子并将钉子敲入墙壁)。这种算法,即示例的递归分类(RCE),不依赖于手工制作的奖励函数、距离函数或特征,而是直接从数据中学习解决任务,要求代理学习如何自行解决整个任务,而不需要任何中间状态的示例。使用时间差异学习的版本(类似于Q 学习),但仅使用成功示例替换典型的奖励函数项 - RCE 优于基于模仿学习的模拟机器人任务的先前方法。加上与基于奖励的学习类似的理论保证,所提出的方法提供了一种用户友好的替代方法来教机器人新任务。
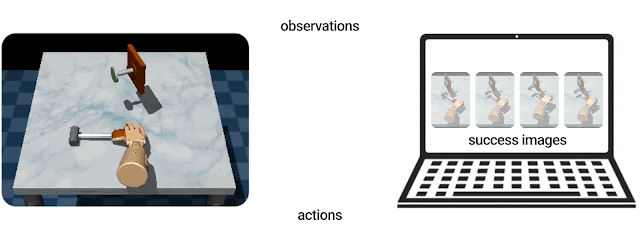
顶部:为了教机器人将钉子钉入墙壁,大多数强化学习算法都要求用户定义奖励函数。底部:基于示例的控制方法使用任务完成时世界的样子的示例来教机器人解决任务,例如,钉子已经钉入墙壁的示例。
基于示例的控制与模仿学习
虽然基于示例的控制方法与模仿学习类似,但有一个重要的区别——它不需要专家 演示。事实上,用户自己执行任务可能很差,只要他们能回顾并找出他们确实遇到过的一小部分状态来解决任务即可。
此外,以前的 研究采用分阶段方法,其中模型首先使用成功示例来学习奖励函数,然后将该奖励函数应用于现成的强化学习算法,而 RCE 直接从示例中学习并跳过定义奖励函数的中间步骤。这样做可以避免潜在的错误并绕过定义与学习奖励函数相关的超参数的过程(例如更新奖励函数的频率或如何对其进行正则化),并且在调试时无需检查与学习奖励函数相关的代码。
示例的递归分类
RCE 方法背后的直觉很简单:考虑到当前的世界状态和代理正在采取的行动,模型应该预测代理将来是否会解决该任务。如果有数据指定哪些状态-动作对会导致未来成功,哪些状态-动作对会导致未来失败,那么可以使用标准监督学习解决这个问题。但是,当唯一可用的数据由成功示例组成时,系统不知道哪些状态和动作导致了成功,虽然系统也有与环境交互的经验,但这种经验不会被标记为会导致成功或不会。
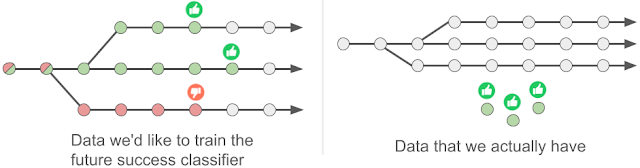
左图:关键思想是学习一个未来的成功分类器,该分类器可以预测轨迹中的每个状态(圆圈)未来是否会解决该任务(竖起大拇指/竖起大拇指)。右图:在基于示例的控制方法中,模型仅提供未标记的经验(灰色圆圈)和成功示例(绿色圆圈),因此无法应用标准监督学习。相反,模型使用成功示例自动标记未标记的经验。
尽管如此,如果这些数据可用,我们可以拼凑出它们的样子。首先,根据定义,成功的示例必须是能够解决给定任务的示例。其次,即使不知道任意状态-动作对是否会成功解决任务,也可以估计如果代理从下一个状态开始,任务被解决的可能性有多大。如果下一个状态可能导致未来的成功,则可以假设当前状态也可能导致未来的成功。实际上,这是递归分类,其中标签是根据下一个时间步骤的预测推断出来的。
使用模型在未来时间步骤的预测作为当前时间步骤的标签的底层算法思想与现有的时间差分方法(例如Q 学习和后继特征)非常相似。关键区别在于此处描述的方法不需要奖励函数。尽管如此,我们表明该方法继承了与时间差分方法相同的许多理论收敛保证 。实际上,实现 RCE 只需要在现有的 Q 学习实现中更改几行代码。
评估
我们在一系列具有挑战性的机器人操作任务上评估了 RCE 方法。例如,在一项任务中,我们需要机械手拿起锤子并将钉子敲入木板。之前对这项任务的研究 [ 1 , 2 ] 使用了复杂的奖励函数(其中的术语对应于手和锤子之间的距离、锤子和钉子之间的距离以及钉子是否已敲入木板)。相比之下,RCE 方法只需要对钉子被锤入木板后的世界进行一些观察即可。
我们将 RCE 的性能与许多先前的方法进行了比较,包括学习显式奖励函数的方法和基于模仿学习的方法,所有这些方法都很难解决此任务。此实验强调了基于示例的控制如何让用户轻松指定甚至复杂的任务,并表明递归分类可以成功解决这些类型的任务。
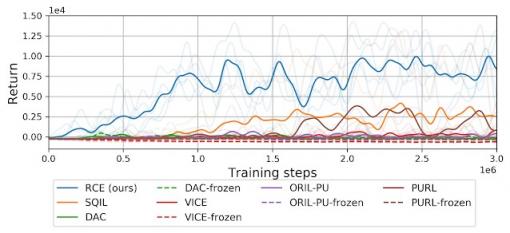
与之前的方法相比,RCE 方法比基于模仿学习的先前方法 [ SQIL,DAC ] 和学习显式奖励函数的先前方法 [ VICE,ORIL,PURL ]更可靠地解决了将钉子钉入木板的任务。
结论
我们提出了一种方法,通过向自主代理提供成功示例来教它们执行任务,而不是精心设计奖励函数或收集第一人称演示。我们在论文中讨论了基于示例的控制的一个重要方面,即系统对不同用户的能力做出了哪些假设。设计能够适应用户能力差异的 RCE 变体可能对现实世界机器人中的应用很重要。代码可用,项目网站包含学习行为的更多视频。
致谢
我们感谢我们的合著者 Ruslan Salakhutdinov 和 Sergey Levine。我们还感谢 Surya Bhupatiraju、Kamyar Ghasemipour、Max Igl 和 Harini Kannan 对本文的反馈,以及 Tom Small 帮助设计本文的图表。
评论