基于Transformers 的自然语言处理(NLP) 模型,例如BERT、RoBERTa、T5或GPT3,可成功完成各种任务,并且是现代 NLP 研究的中流砥柱。 Transformers 的多功能性和稳健性是其被广泛采用的主要驱动力,这使得它们可以轻松地适用于各种基于序列的任务——作为翻译、摘要、生成等的 seq2seq 模型,或作为情感分析、词性标记、机器阅读理解等的独立编码器。 Transformers 的关键创新是引入了自注意力机制,该机制计算输入序列中所有位置对的相似度得分,并且可以对输入序列的每个标记进行并行评估,从而避免了循环神经网络的顺序依赖性,并使 Transformers 的性能大大优于之前的序列模型,如LSTM。
然而,现有 Transformer 模型及其衍生物的一个限制是,完全自注意力机制的计算和内存要求与输入序列长度成二次方关系。使用目前常见的硬件和模型大小,这通常会将输入序列限制为大约 512 个 token,并且阻止 Transformer 直接应用于需要更大上下文的任务,如问答、文档摘要或基因组片段分类。两个自然的问题出现了:1)我们能否使用计算和内存要求与输入序列长度成线性关系的稀疏模型来实现二次全 Transformer 的经验优势?2)是否有可能从理论上证明这些线性 Transformer 保留了二次全 Transformer 的表达力和灵活性?
我们在最近的两篇论文中解决了这两个问题。在EMNLP 2020上发表的“ ETC:在 Transformers 中编码长输入和结构化输入”中,我们提出了扩展 Transformer 构造 (ETC),这是一种新颖的稀疏注意方法,其中使用结构信息来限制计算的相似度得分对的数量。这将对输入长度的二次依赖性降低为线性,并在 NLP 领域产生强有力的经验结果。然后,在NeurIPS 2020上发表的“ Big Bird:用于更长序列的 Transformers ”中,我们介绍了另一种稀疏注意方法,称为 BigBird,它将 ETC 扩展到更通用的场景,在这些场景中可能无法获得有关源数据中存在的结构的先决条件领域知识。此外,我们还从理论上表明,我们提出的稀疏注意机制保留了二次全 Transformers 的表达力和灵活性。我们提出的方法在具有挑战性的长序列任务上取得了新的进展,包括问答、文档摘要和基因组片段分类。
注意力机制图
Transformer 模型中使用的注意力模块会计算输入序列中所有位置对的相似度得分。将注意力机制视为有向图很有用,其中标记由节点表示,而一对标记之间的相似度得分由边表示。从这个角度来看,完整的注意力模型是一个完整的图。我们方法背后的核心思想是精心设计稀疏图,这样只需计算线性数量的相似度得分。
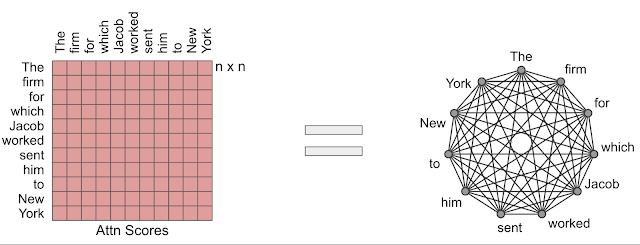
充分的注意力可以看作是一个完整的图。
扩展变压器结构 (ETC)
对于需要长而结构化输入的 NLP 任务,我们提出了一种结构化的稀疏注意力机制,我们称之为扩展 Transformer 构造(ETC)。为了实现自我注意力的结构化稀疏化,我们开发了全局-局部注意力机制。在这里,Transformer 的输入被分成两部分:全局输入,其中 token 具有不受限制的注意力;长输入,其中 token 只能关注全局输入或局部邻域。这实现了注意力的线性扩展,从而使 ETC 能够显著扩展输入长度。
为了进一步利用长文档的结构,ETC 结合了其他思想:以相对方式表示标记的位置信息,而不是使用它们在序列中的绝对位置;使用超出 BERT等模型中通常使用的屏蔽语言模型 (MLM) 的附加训练目标;灵活地屏蔽标记以控制哪些标记可以关注哪些其他标记。例如,给定一段长文本,将全局标记应用于每个句子,连接到句子内的所有标记,并将全局标记应用于每个段落,连接到同一段落内的所有标记。

基于文档结构的 ETC 模型稀疏注意力示例。全局变量用 C(蓝色)表示段落,用 S(黄色)表示句子,而局部变量用 X(灰色)表示与长输入相对应的标记。
通过这种方法,我们在五个需要长或结构化输入的具有挑战性的 NLP 数据集中报告了最先进的结果:TriviaQA、Natural Questions (NQ)、HotpotQA、WikiHop和OpenKP。
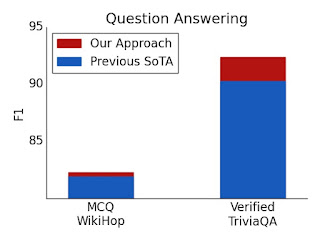
问答测试集结果。对于经过验证的 TriviaQA 和 WikiHop,使用 ETC 达到了新的最佳水平。
大鸟
我们扩展了 ETC 的工作,提出了BigBird——一种稀疏注意力机制,其数量也与 token 数量呈线性关系,是 Transformers 中使用的注意力机制的通用替代品。与 ETC 相比,BigBird 不需要任何有关源数据中存在的结构的先决知识。BigBird 模型中的稀疏注意力由三个主要部分组成:
一组全局标记,关注输入序列的所有部分
所有 token 都关注一组本地相邻 token
所有 token 都属于一组随机 token
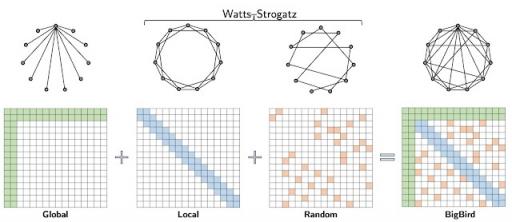
BigBird 稀疏注意力可以看作是在Watts-Strogatz 图上添加了一些全局标记。
在BigBird 论文中,我们解释了为什么稀疏注意力足以近似二次注意力,这部分解释了 ETC 为何成功。一个关键的观察是,计算的相似度得分数量与不同节点之间的信息流(即一个 token 相互影响的能力)之间存在内在的矛盾。全局 token 充当信息流的管道,我们证明具有全局 token 的稀疏注意力机制可以与完整注意力模型一样强大。特别是,我们表明 BigBird 与原始 Transformer 一样具有表现力,具有计算通用性(遵循Yun 等人和Perez 等人的工作),并且是连续函数的通用近似器。此外,我们的证明表明使用随机图可以进一步帮助缓解信息流——激发使用随机注意力组件。
这种设计可以扩展到更长的序列长度,适用于结构化和非结构化任务。通过使用梯度检查点,以训练时间换取序列长度,可以实现进一步的扩展。这让我们可以扩展高效的稀疏变换器,以包括需要编码器和解码器的生成任务,例如长文档摘要,我们在这方面取得了新的领先水平。
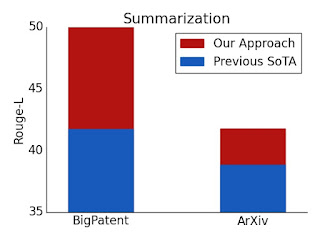
长文档的摘要ROUGE分数。对于BigPatent和ArXiv数据集,我们都取得了新的最先进成果。
此外,BigBird 是一种通用替代品,因此它无需预先具备领域知识即可扩展到新领域。具体来说,我们介绍了一种基于 Transformer 的模型的新应用,其中长上下文是有益的——提取基因组序列 (DNA) 的上下文表示。通过更长的掩蔽语言模型预训练,BigBird 在下游任务(如启动子区域预测和染色质谱预测)上实现了最先进的性能。
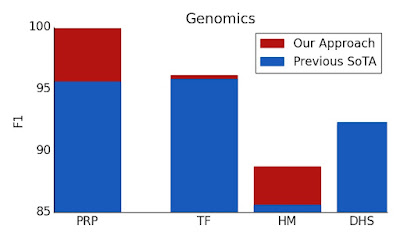
在启动子区域预测 (PRP)、染色质谱预测(包括转录因子 (TF)、组蛋白标记 (HM) 和 DNase I 高敏性 (DHS)检测)等多个基因组学任务上,我们的表现优于基线。此外,我们的结果表明,Transformer 模型可以应用于目前尚未充分探索的多个基因组学任务。
主要实现思路
大规模采用稀疏注意力的主要障碍之一是稀疏操作在现代硬件中效率相当低。在 ETC 和 BigBird 背后,我们的关键创新之一是高效实施稀疏注意力机制。由于现代硬件加速器(如 GPU 和 TPU)擅长使用合并内存操作,这些操作一次加载连续字节块,因此由滑动窗口(用于局部注意力)或随机元素查询(随机注意力)引起的小规模零星查找效率不高。相反,我们将稀疏局部和随机注意力转换为密集张量操作,以充分利用现代单指令多数据(SIMD) 硬件。
为此,我们首先将注意力机制“分块化”,以便更好地利用设计为以块为单位进行操作的 GPU/TPU。然后,我们通过一系列简单的矩阵运算(例如重塑、滚动和聚集)将稀疏注意力机制计算转换为密集张量积,如下面的动画所示。
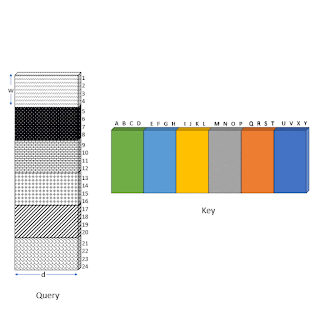
说明如何使用滚动和重塑来有效计算稀疏窗口注意力,而无需小规模的零星查找。
最近,“长距离竞技场:高效 Transformers 的基准”提供了六个需要较长上下文的任务的基准,并进行了实验以对所有现有的长距离 Transformers 进行基准测试。结果表明,与其他同类模型不同,BigBird 模型明显减少了内存消耗,同时不牺牲性能。
结论
我们表明,精心设计的稀疏注意力模型可以像原始的全注意力模型一样富有表现力和灵活性。除了理论保证之外,我们还提供了一种非常有效的实现,使我们能够扩展到更长的输入。因此,我们在问答、文档摘要和基因组片段分类方面取得了最先进的成果。鉴于我们的稀疏注意力模型的通用性,该方法应该适用于许多其他任务,如程序合成和长篇开放域问答。我们已经为ETC (github)和BigBird (github)开源了代码,它们都可以在 GPU 和 TPU 上高效运行长序列。
致谢
这项研究是与 Amr Ahmed、Joshua Ainslie、Chris Alberti、Vaclav Cvicek、Avinava Dubey、Zachary Fisher、Guru Guruganesh、Santiago Ontañón、Philip Pham、Anirudh Ravula、Sumit Sanghai、Qifan Wang、Li Yang、Manzil Zaheer 合作完成的,他们共同撰写 EMNLP 和 NeurIPS 论文。
评论