全景分割是一项计算机视觉任务,它将语义分割(为每个像素分配一个类别标签)和实例分割(检测和分割每个对象实例)统一起来。全景分割是现实世界应用的核心任务,它可以预测一组不重叠的掩码及其相应的类别标签(即对象类别,如“汽车”、“交通信号灯”、“道路”等),并且通常使用多个替代子任务来完成,这些子任务可以近似(例如,通过使用框检测方法)全景分割的目标。

来自Cityscapes数据集的示例图像及其全景分割蒙版。
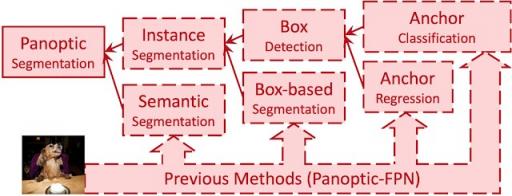
以前的方法利用替代子任务树来近似全景分割。
该代理树中的每个代理子任务都会引入额外的手动设计模块,例如锚点设计规则、框分配规则、非最大值抑制(NMS)、事物合并等。尽管对于各个代理子任务和模块都有很好的解决方案,但是当这些子任务在全景分割的流程中组合在一起时会引入不良伪影,尤其是在具有挑战性的条件下(例如,两个具有相似边界框的人会触发 NMS,导致丢失掩模)。
先前的研究(例如DETR)尝试通过将盒子检测子任务简化为端到端操作来解决其中的一些问题,这在计算上更有效并且会产生更少的不良伪影。然而,训练过程仍然严重依赖于盒子检测,这与基于掩模的全景分割定义不符。另一项工作将盒子从管道中完全移除,这样做的好处是可以移除整个代理子任务及其相关模块和伪影。例如,Axial-DeepLab可以预测与预定义实例中心的像素级偏移,但是它使用的代理子任务在处理高度可变形的物体(具有多种形状(例如猫))或图像平面中中心靠得很近的附近物体(例如下图中坐在椅子上的狗)时会遇到挑战。

当狗和椅子的中心彼此靠近时,Axial-DeepLab 将它们合并为一个物体。
在即将于CVPR 2021上展示的 “ MaX-DeepLab:使用 Mask Transformers 的端到端全景分割”中,我们提出了第一个完全端到端的全景分割流程方法,通过将 Transformer 架构扩展到此计算机视觉任务,直接预测带类标记的掩码。我们的方法被称为MaX -DeepLab,用于使用Ma sk X成型器扩展 Axial-DeepLab,它采用双路径架构,引入了全局内存路径,允许与任何卷积层直接通信。结果,MaX-DeepLab在具有挑战性的COCO数据集上的无框方案中显示出显着的 7.1%的全景质量(PQ) 增益,首次缩小了基于框和无框方法之间的差距。MaX-DeepLab 在 COCO 测试开发集上实现了最先进的 51.3% 的 PQ,而无需测试时间增加。
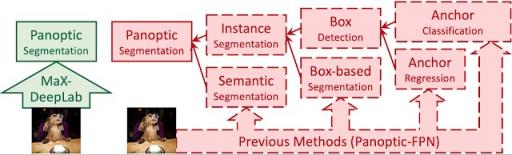
MaX-DeepLab 是完全端到端的:它直接从图像中预测全景分割掩模。
端到端全景分割
受DETR的启发,我们的模型直接预测一组不重叠的掩码及其对应的语义标签,并使用 PQ 样式目标进行优化的输出掩码和类。具体而言,受评估指标 PQ 的启发,PQ 定义为识别质量(预测的类别是否正确)乘以分割质量(预测的掩码是否正确),我们以完全相同的方式定义两个类标记掩码之间的相似性度量。通过一对一匹配最大化地面真实掩码和预测掩码之间的相似性,直接训练模型。这种全景分割的直接建模可以实现端到端的训练和推理,消除了现有基于框和无框方法中必需的手工编码先验。
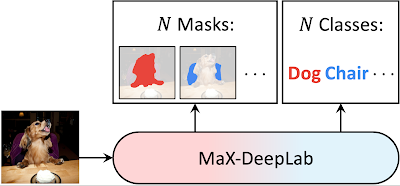
MaX-DeepLab 使用 CNN 和 mask Transformer 直接预测 N 个 mask 和 N 个类。
双路变压器
我们提出了一种双路径框架,将 CNN 与变压器相结合,而不是在卷积神经网络(CNN) 上堆叠传统的变压器。具体来说,我们使用双路径变压器块使任何 CNN 层都能读取和写入全局内存。这个提议的块采用了 CNN 路径和内存路径之间的所有四种注意力类型,并且可以插入 CNN 中的任何位置,从而实现与任何层的全局内存的通信。MaX-DeepLab 还采用了堆叠沙漏式解码器,可将多尺度特征聚合为高分辨率输出。然后将输出与全局内存特征相乘,以形成掩码集预测。使用掩码变压器的另一个分支来预测掩码的类别。
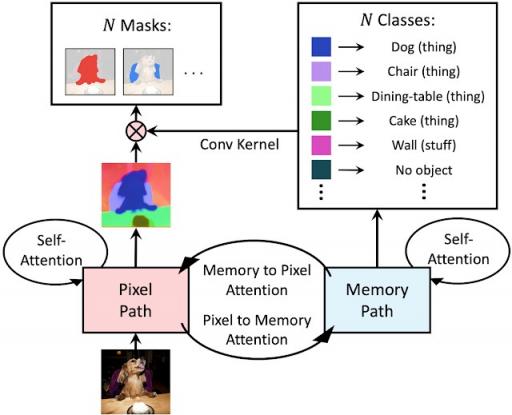
双路径变压器架构概述。
结果
我们在最具挑战性的全景分割数据集之一COCO上对 MaX-DeepLab 进行了评估,并与最先进的无框 (Axial-DeepLab) 和基于框 (DetectoRS) 方法进行了对比。MaX-DeepLab 在没有测试时间增强的情况下,在测试开发集上实现了 51.3% PQ 的最优结果。
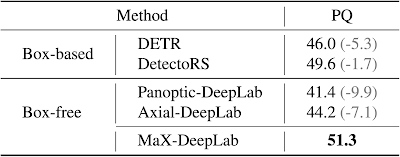
在 COCO 测试开发集上进行比较。
该结果在无框情况下比 Axial-DeepLab 高出 7.1% PQ,比 DetectoRS 高出 1.7% PQ,首次缩小了基于框的方法和无框方法之间的差距。为了与DETR进行一致的比较,我们还评估了与 DETR 参数数量和计算量相匹配的轻量级 MaX-DeepLab 版本。轻量级 MaX-DeepLab 在验证集上的表现比 DETR 高出 3.3% PQ,在测试开发集上的表现比 DETR 高出 3.0% PQ。此外,我们对我们的端到端公式、模型缩放、双路径架构和损失函数进行了广泛的消融研究和分析。此外,DETR 的超长训练计划对于 MaX-DeepLab 来说不是必要的。
如下图所示,MaX-DeepLab 正确地分割了坐在椅子上的狗。Axial- DeepLab依赖于回归对象中心偏移的替代子任务。它失败了,因为狗和椅子的中心彼此靠近。DetectoRS 将对象边界框(而不是掩码)分类为替代子任务。它过滤掉了椅子掩码,因为椅子边界框的置信度较低。
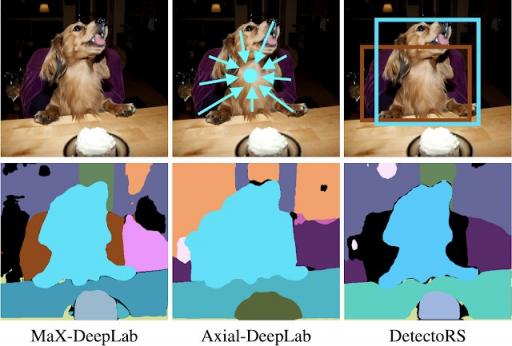
MaX-DeepLab 和最先进的无框和基于框的方法的案例研究。
另一个例子展示了MaX-DeepLab如何正确地分割具有挑战性的条件下的图像。

MaX-DeepLab 正确地分割了重叠的斑马。这种情况对其他方法来说也具有挑战性,因为斑马具有相似的边界框和附近的物体中心。(信用和许可)
结论
我们首次展示了全景分割可以端到端训练。MaX-DeepLab 使用掩码转换器直接预测掩码和类别,无需许多手工设计的先验,例如对象边界框、事物合并等。配备 PQ 样式损失和双路径转换器后,MaX-DeepLab 在具有挑战性的 COCO 数据集上取得了最先进的结果,缩小了基于框的方法和无框方法之间的差距。
致谢
我们感谢我们的合著者 Yukun Zhu、Hartwig Adam 和 Alan Yuille。我们还要感谢 Maxwell Collins、Sergey Ioffe、Jiquan Ngiam、Siyuan Qiao、Chen Wei、Jieneng Chen 以及 Mobile Vision 团队的支持和宝贵的讨论。
评论